






一、本文介绍
本文给大家带来的改进机制是ACmix自注意力机制的改进版本,它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。本文改进是基于ResNet18、ResNet34、ResNet50、ResNet101,文章中均以提供,本专栏的改进内容全网独一份深度改进RT-DETR非那种无效Neck部分改进,同时本文的改进也支持主干上的即插即用,本文内容也支持PP-HGNetV2版本的修改。
目录
4.1 修改Basicclock/Bottleneck的教程
5.1 替换ResNet的yaml文件1(ResNet18版本)
5.2 替换ResNet的yaml文件1(ResNet50版本)
二、ACmix的框架原理

官方论文地址:官方论文地址
官方代码地址:官方代码地址

2.1 ACMix的基本原理
ACmix是一种混合模型,结合了自注意力机制和卷积运算的优势。它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。
ACmix模型的主要改进机制可以分为以下两点:
1. 自注意力和卷积的整合:将自注意力和卷积技术融合,实现两者优势的结合。
2. 运算分解与重构:通过分解自注意力和卷积中的运算,重构为1×1卷积形式,提高了运算效率。
2.1.1 自注意力和卷积的整合
文章中指出,自注意力和卷积的整合通过以下方式实现:
特征分解:自注意力机制的查询(query)、键(key)、值(value)与卷积操作通过1x1卷积进行特征分解。
运算共享:卷积和自注意力共享相同的1x1卷积运算,减少了重复的计算量。
特征融合:在ACmix模型中,卷积和自注意力生成的特征通过求和操作进行融合,加强了模型的特征提取能力。
模块化设计:通过模块化设计,ACmix可以灵活地嵌入到不同的网络结构中,增强网络的表征能力。

这张图片展示了ACmix中的主要概念,它比较了卷积、自注意力和ACmix各自的结构和计算复杂度。图中:
(a) 卷积:展示了标准卷积操作,包含一个的1x1卷积,表示卷积核大小和卷积操作的聚合。
(b) 自注意力:展示了自注意力机制,它包含三个头部的1x1卷积,代表多头注意力机制中每个头部的线性变换,以及自注意力聚合。
(c) ACmix(我们的方法):结合了卷积和自注意力聚合,其中1x1卷积在两者之间共享,旨在减少计算开销并整合轻量级的聚合操作。
整体上,ACmix旨在通过共享计算资源(1x1卷积)并结合两种不同的聚合操作,以优化特征通道上的计算复杂度。
2.1.2 运算分解与重构
在ACmix中,运算分解与重构的概念是指将传统的卷积运算和自注意力运算拆分,并重新构建为更高效的形式。这主要通过以下步骤实现:
分解卷积和自注意力:将标准的卷积核分解成多个1×1卷积核,每个核处理不同的特征子集,同时将自注意力机制中的查询(query)、键(key)和值(value)的生成也转换为1×1卷积操作。
重构为混合模块:将分解后的卷积和自注意力运算重构成一个统一的混合模块,既包含了卷积的空间特征提取能力,也融入了自注意力的全局信息聚合功能。
提高运算效率:这种分解与重构的方法减少了冗余计算,提高了运算效率,同时降低了模型的复杂度。

这张图片展示了ACmix提出的混合模块的结构。图示包含了:
(a) 卷积:3x3卷积通过1x1卷积的方式被分解,展示了特征图的转换过程。
(b)自注意力:输入特征先转换成查询(query)、键(key)和值(value),使用1x1卷积实现,并通过相似度匹配计算注意力权重。
(c) ACmix:结合了(a)和(b)的特点,在第一阶段使用三个1x1卷积对输入特征图进行投影,在第二阶段将两种路径得到的特征相加,作为最终输出。
右图显示了ACmix模块的流程,强调了两种机制的融合并提供了每个操作块的计算复杂度。
三、ACmix的核心代码
该代码本身存在一个bug,会导致验证的时候报类型不匹配的错误,我将其进行了解决,这也是一个读者和我说的想要帮忙解决一下这个问题困扰了他很久。
import torch
import torch.nn as nn
__all__ = ['ACmix', 'BasicBlock_ACmix', 'BottleNeck_ACmix']
def position(H, W, type, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1).to(type)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W).to(type)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
out_planes = in_planes
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3 * self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes,
kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1,
stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i // self.kernel_conv, i % self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h // self.stride, w // self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.dtype, x.is_cuda))
q_att = q.view(b * self.head, self.head_dim, h, w) * scaling
k_att = k.view(b * self.head, self.head_dim, h, w)
v_att = v.view(b * self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b * self.head, self.head_dim,
self.kernel_att * self.kernel_att, h_out,
w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att * self.kernel_att, h_out,
w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2) * (unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(
1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b * self.head, self.head_dim, self.kernel_att * self.kernel_att,
h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat(
[q.view(b, self.head, self.head_dim, h * w), k.view(b, self.head, self.head_dim, h * w),
v.view(b, self.head, self.head_dim, h * w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
from collections import OrderedDict
import torch.nn.functional as F
class ConvNormLayer(nn.Module):
def __init__(self,
ch_in,
ch_out,
filter_size,
stride,
groups=1,
act=None):
super(ConvNormLayer, self).__init__()
self.act = act
self.conv = nn.Conv2d(
in_channels=ch_in,
out_channels=ch_out,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups)
self.norm = nn.BatchNorm2d(ch_out)
def forward(self, inputs):
out = self.conv(inputs)
out = self.norm(out)
if self.act:
out = getattr(F, self.act)(out)
return out
class BasicBlock_ACmix(nn.Module):
expansion = 1
def __init__(self,
ch_in,
ch_out,
stride,
shortcut,
act='relu',
variant='b',
att=False):
super(BasicBlock_ACmix, self).__init__()
self.shortcut = shortcut
if not shortcut:
if variant == 'd' and stride == 2:
self.short = nn.Sequential()
self.short.add_sublayer(
'pool',
nn.AvgPool2d(
kernel_size=2, stride=2, padding=0, ceil_mode=True))
self.short.add_sublayer(
'conv',
ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=1))
else:
self.short = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=1,
stride=stride)
self.branch2a = ConvNormLayer(
ch_in=ch_in,
ch_out=ch_out,
filter_size=3,
stride=stride,
act='relu')
self.branch2b = ConvNormLayer(
ch_in=ch_out,
ch_out=ch_out,
filter_size=3,
stride=1,
act=None)
self.att = att
if self.att:
self.se = ACmix(ch_out)
def forward(self, inputs):
out = self.branch2a(inputs)
out = self.branch2b(out)
if self.att:
out = self.se(out)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
out = out + short
out = F.relu(out)
return out
class BottleNeck_ACmix(nn.Module):
expansion = 4
def __init__(self, ch_in, ch_out, stride, shortcut, act='relu', variant='d', att=False):
super().__init__()
if variant == 'a':
stride1, stride2 = stride, 1
else:
stride1, stride2 = 1, stride
width = ch_out
self.branch2a = ConvNormLayer(ch_in, width, 1, stride1, act=act)
self.branch2b = ConvNormLayer(width, width, 3, stride2, act=act)
self.branch2c = ConvNormLayer(width, ch_out * self.expansion, 1, 1)
self.shortcut = shortcut
if not shortcut:
if variant == 'd' and stride == 2:
self.short = nn.Sequential(OrderedDict([
('pool', nn.AvgPool2d(2, 2, 0, ceil_mode=True)),
('conv', ConvNormLayer(ch_in, ch_out * self.expansion, 1, 1))
]))
else:
self.short = ConvNormLayer(ch_in, ch_out * self.expansion, 1, stride)
self.att = att
if self.att:
self.se = ACmix(ch_out * 4)
def forward(self, x):
out = self.branch2a(x)
out = self.branch2b(out)
out = self.branch2c(out)
if self.att:
out = self.se(out)
if self.shortcut:
short = x
else:
short = self.short(x)
out = out + short
out = F.relu(out)
return out
四、手把手教你添加ACmix
修改教程分两种,一种是替换修改ResNet中的Basicclock/Bottleneck模块的,一种是在主干上即插即用的修改教程,如果你只需要一种那么修改对应的就行,互相之间并不影响,需要注意的是即插即用的需要修改ResNet改进才行,链接如下:
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
4.1 修改Basicclock/Bottleneck的教程
4.1.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.1.2 修改二
第二步此处需要注意,因为我这里默认大家修改了ResNet系列的模型了,同级目录下应该有一个ResNet.py的文件夹,我们这里需要找到我们'ultralytics/nn/Addmodules/ResNet.py'创建的ResNet的文件夹(默认大家已经创建了!!!)

我们只需要修改上面的两步即可,后面复制yaml文件进行运行即可了,修改方法大家只要仔细看是非常简单的。
4.2 修改主干上即插即用的教程
4.2.1 修改一(如果修改了4.1教程此步无需修改)
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。
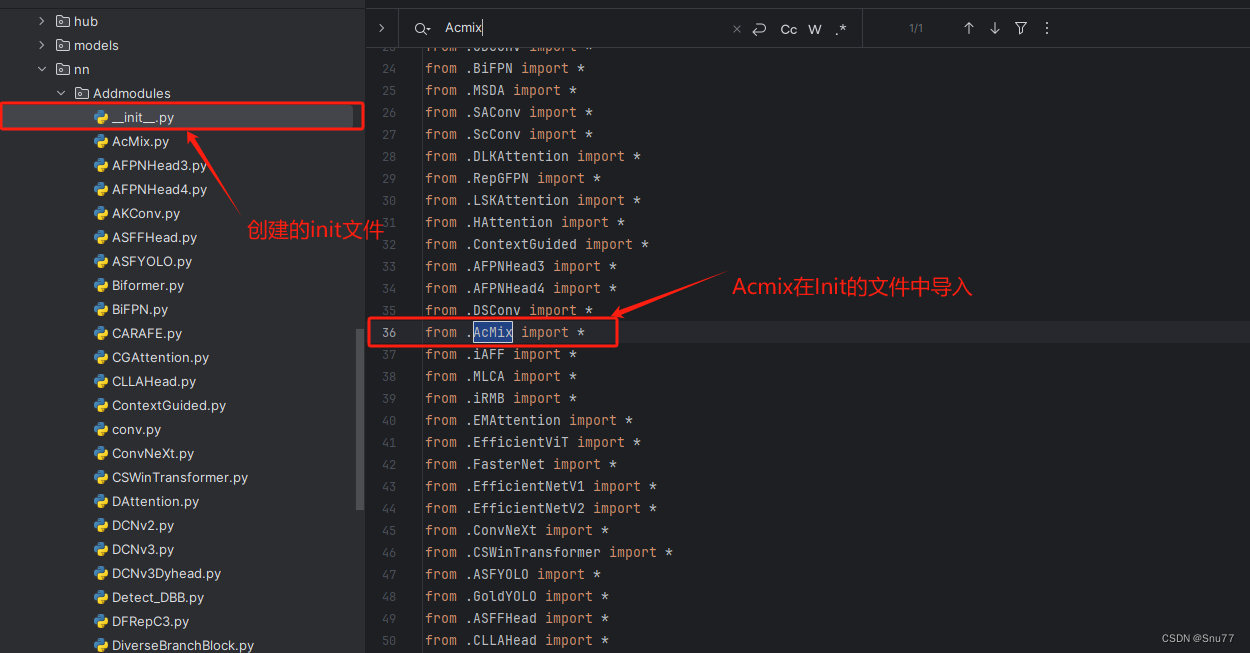
4.2.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
4.2.3 修改三
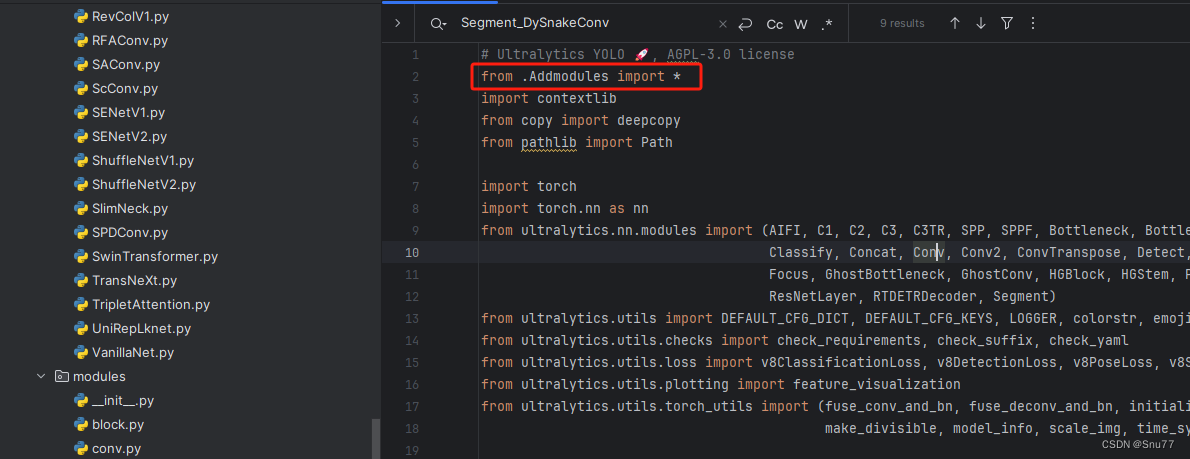
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
4.2.4 修改四
按照我的添加在parse_model里添加即可。

elif m in {ACmix}:
c2 = ch[f]
args = [c2, *args]到此就修改完成了,大家可以复制下面的yaml文件运行。
五、ACmix的yaml文件
5.1 替换ResNet的yaml文件1(ResNet18版本)
需要修改如下的ResNet主干才可以运行本文的改进机制 !
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, 1, 'relu']] # 0-P1
- [-1, 1, ConvNormLayer, [32, 3, 1, 1, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, 1, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2
- [-1, 2, Blocks, [64, BasicBlock_ACmix, 2, True]] # 4
- [-1, 2, Blocks, [128, BasicBlock_ACmix, 3, True]] # 5-P3
- [-1, 2, Blocks, [256, BasicBlock_ACmix, 4, True]] # 6-P4
- [-1, 2, Blocks, [512, BasicBlock_ACmix, 5, True]] # 7-P5
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256, 0.5]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P4
- [-1, 3, RepC3, [256, 0.5]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256, 0.5]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256, 0.5]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)
5.2 替换ResNet的yaml文件1(ResNet50版本)
需要修改如下的ResNet主干才可以运行本文的改进机制 !
ResNet文章地址:【RT-DETR改进涨点】ResNet18、34、50、101等多个版本移植到ultralytics仓库(RT-DETR官方一比一移植)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, 1, 'relu']] # 0-P1
- [-1, 1, ConvNormLayer, [32, 3, 1, 1, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, 1, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2
- [-1, 3, Blocks, [64, BottleNeck_ACmix, 2, True]] # 4
- [-1, 4, Blocks, [128, BottleNeck_ACmix, 3, True]] # 5-P3
- [-1, 6, Blocks, [256, BottleNeck_ACmix, 4, True]] # 6-P4
- [-1, 3, Blocks, [512, BottleNeck_ACmix, 5, True]] # 7-P5
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]] # 9
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]] # 13
- [-1, 3, RepC3, [256]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 6]] # Detect(P3, P4, P5)
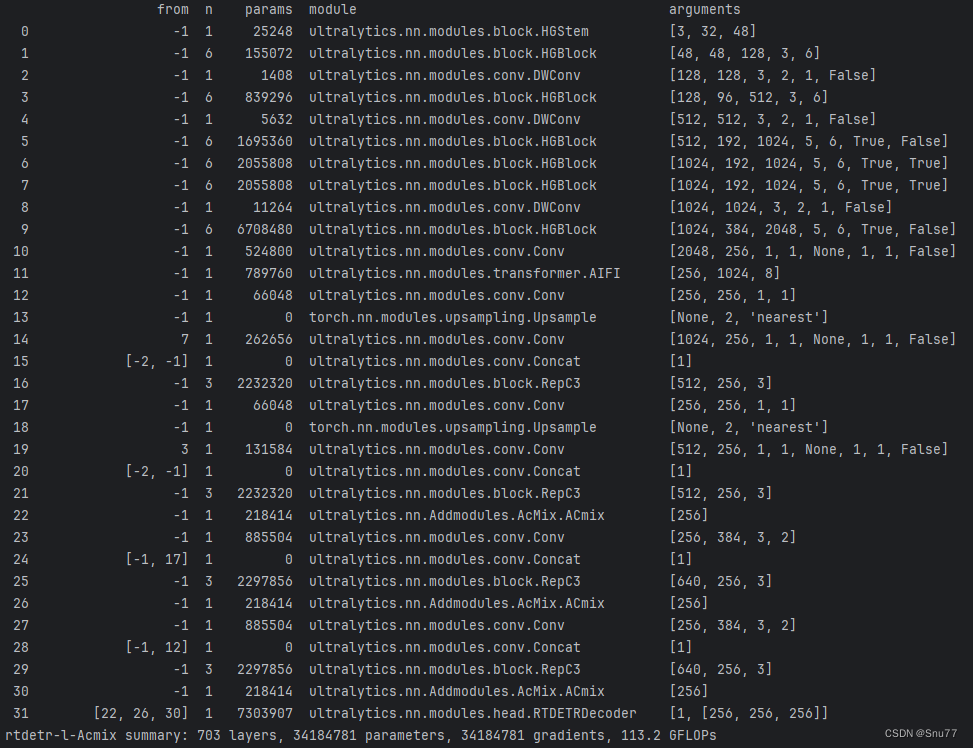
5.3 即插即用的yaml文件(HGNetV2版本)
此版本为HGNetV2-l的yaml文件!
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P3/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P4/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, ACmix, []] # 22
- [-1, 1, Conv, [384, 3, 2]] # 23, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (25), pan_blocks.0
- [-1, 1, ACmix, []] # 26
- [-1, 1, Conv, [384, 3, 2]] # 27, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (29), pan_blocks.1
- [-1, 1, ACmix, []] # 30
- [[22, 26, 30], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
六、成功运行记录
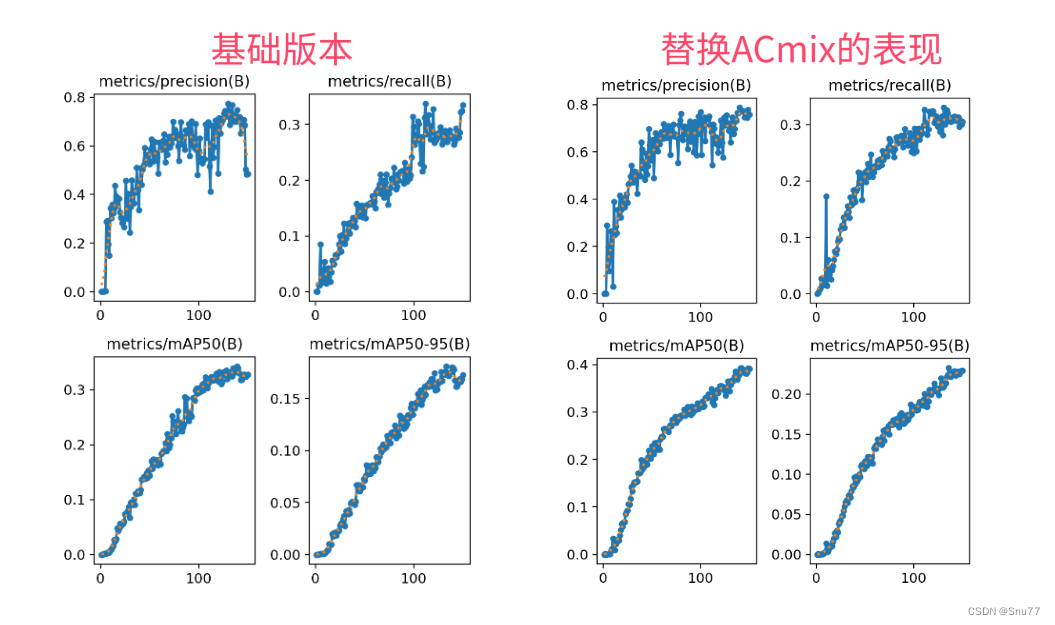
6.1 ResNet18运行成功记录截图

6.2 ResNet50运行成功记录截图
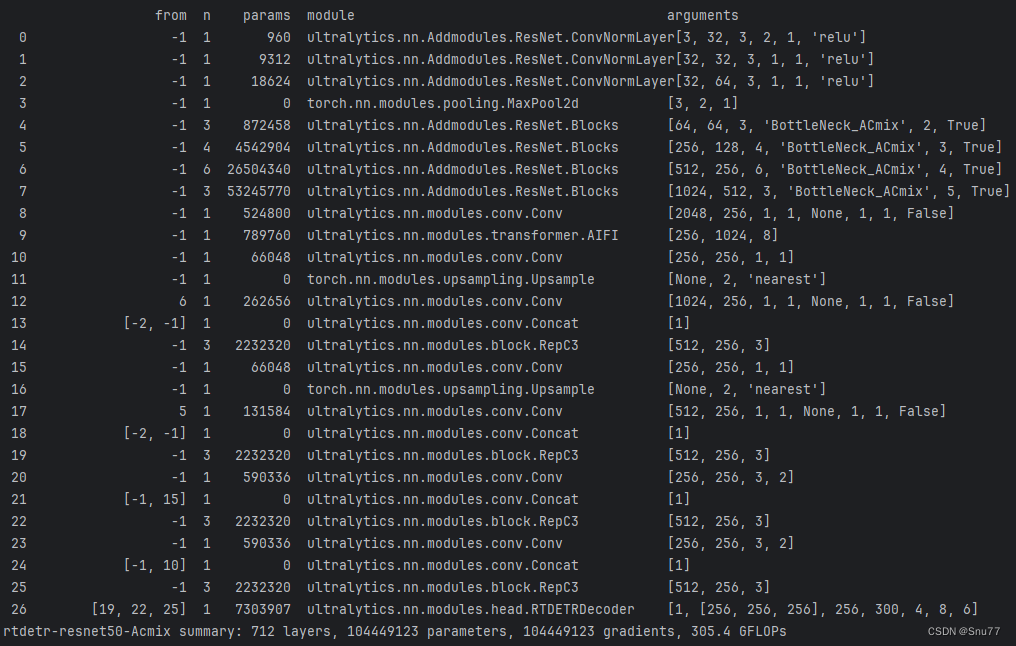
6.3 HGNetv2运行成功记录截图
七、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的RT-DETR改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~















 6931
6931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











