







 本文探讨了缓存管理中常见的问题,包括热点数据与淘汰策略、缓存雪崩、缓存击穿和缓存穿透,以及如何确保缓存数据一致性。在缓存满载时,提出了数据淘汰机制,如随机淘汰和LRU策略。为避免缓存雪崩,建议随机打散过期时间。缓存击穿可通过分布式锁和预热加载机制解决。针对缓存穿透,可以使用白名单策略或设置访问阈值来防止恶意请求。在数据一致性方面,讨论了先更新数据库再更新/删除缓存的策略,并引入了补偿机制和缓存过期时间以降低不一致风险。
本文探讨了缓存管理中常见的问题,包括热点数据与淘汰策略、缓存雪崩、缓存击穿和缓存穿透,以及如何确保缓存数据一致性。在缓存满载时,提出了数据淘汰机制,如随机淘汰和LRU策略。为避免缓存雪崩,建议随机打散过期时间。缓存击穿可通过分布式锁和预热加载机制解决。针对缓存穿透,可以使用白名单策略或设置访问阈值来防止恶意请求。在数据一致性方面,讨论了先更新数据库再更新/删除缓存的策略,并引入了补偿机制和缓存过期时间以降低不一致风险。
热点数据与淘汰策略
大部分服务端使用的抗压型缓存,为了保证缓存执行速度,普遍都是将数据存储在内存中。而受限于硬件与成本约束,内存的容量不太可能像磁盘一样近乎无限的去随意扩容使用。对于实际数据量及其庞大且无法将其全部存储于缓存中的时候,我们需要保证存储在缓存中的有限部分数据要尽可能的命中更多的请求,即要求缓存中存储的都是热点数据。
说到这里,就会存在一个不得不面对的问题:当数据量超级大而缓存的内存容量有限的情况下,如果容量满了该怎么办?
断舍离!
缓存实现的时候,必须要有一种机制,能够保证内存中的数据不会无限制增加 —— 也即数据淘汰机制。数据淘汰机制,是一个成熟的缓存体系所必备的基础能力。这里有个概念需要厘清,即数据淘汰策略与数据过期是两个不同的概念。
-
数据过期,是缓存系统的一个正常逻辑,是符合业务预期的一种数据删除机制。即设定了有效期的缓存数据,过期之后从缓存中移除。
-
数据淘汰,是缓存系统的一种“有损自保”的
降级策略,是业务预期之外的一种数据删除手段。指的是所存储的数据没达到过期时间,但缓存空间满了,对于新的数据想要加入缓存中时,缓存模块需要执行的一种应对策略。

我们把缓存当做一个容器,试想一下,一个容器已满的情况下,继续往里面放东西,可以有什么应对之法?无外乎两种:
-
直接拒绝,因为满了,放不下了。
-
从容器里面扔掉一些已有内容,然后腾挪出部分空间出来,将新的东西放进来。
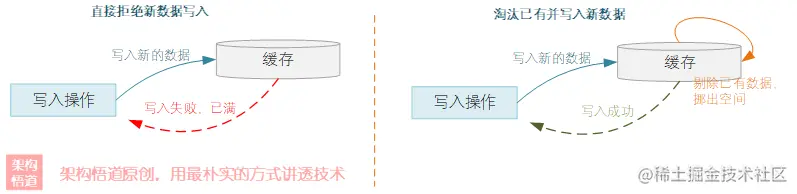
进一步地,当决定采用先从容器中扔掉一些已有内容的时候,又会面临一个新的抉择,应该扔掉哪些内容?实践中常用的也有几种方案:
-
一切随缘,随机决定。从容器中现有的内容中
随机扔掉剔除一些。 -
按需排序,保留常用。即基于
LRU策略,将最久没有被使用过的数据给剔除掉。 -
提前过期,淘汰出局。对于一些设置了过期时间的记录,将其按照过期时间点进行排序,将最近即将过期的数据剔除(类似让其
提前过期)。 -
其它策略。自行实现缓存时,除了上述集中常见策略,也可以根据业务的场景构建业务自定义的淘汰策略。比如根据
创建日期、根据最后修改日期、根据优先级、根据访问次数等等。
一些主流的缓存中间件的淘汰机制大都也是遵循上述的方案来实现的。比如Redis提供了高达6种不同的数据淘汰机制,供使用方按需选择,将有限的空间仅用来存储热点数据,实现缓存的价值最大化。如下:
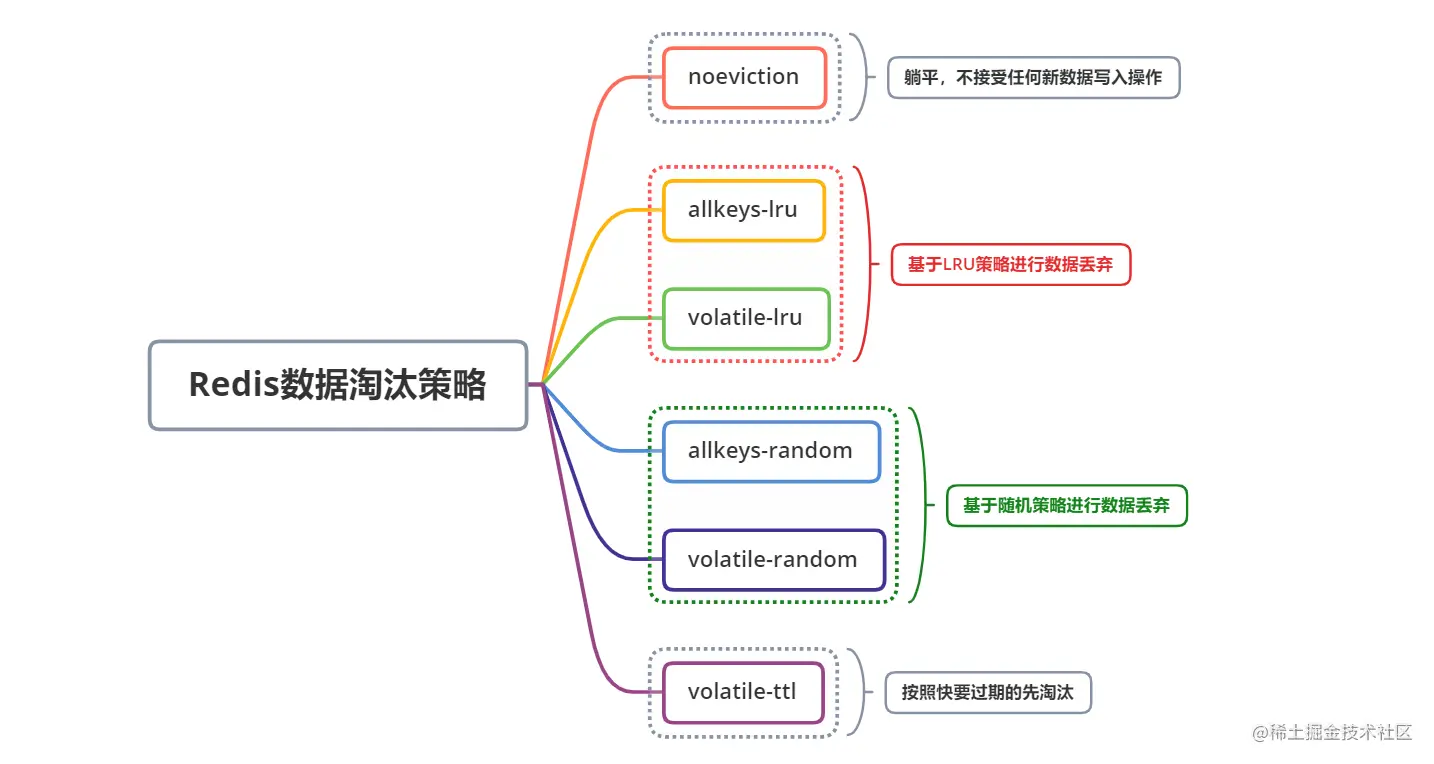
从上图可以看出,Redis对随机淘汰和LRU策略进行的更精细化的实现,支持将淘汰目标范围细分为全部数据和设有过期时间的数据,这种策略相对更为合理一些。因为一般设置了过期时间的数据,本身就具备可删除性,将其直接淘汰对业务不会有逻辑上的影响;而没有设置过期时间的数据,通常是要求常驻内存的,往往是一些配置数据或者是一些需要当做白名单含义使用的数据(比如用户信息,如果用户信息不在缓存里,则说明用户不存在),这种如果强行将其删除,可能会造成业务层面的一些逻辑异常。

缓存雪崩:避免缓存的集中失效
为了限制缓存的数量,很多的缓存记录都会设置一定的有效期,到期后自动失效。这种在一些批量缓存构建或者全量缓存重建时,因为设置了相同的失效时间,会导致大量甚至全部的缓存数据在短时间内集体
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









