






1、什么是机器学习?
机器学习其实是属于⼈⼯智能的⼀个研究范畴。说到⼈⼯智能,⼤家应该都很熟悉了。 像
AlphaGo
⼤战柯蓝,已经是⼀个⽿熟能详的故事了。
从现在来看,⼈⼯智能的实现⽅式⼤致分为了两个学派:
⼀个是符号主义或者也称为逻辑主义
(Symbolism)
,他强调⼈对事物的认知是有⼀定的推理过程的。所以只要通过计算机,把逻辑推理的过程模拟出来,就能实现⼈⼯智能。像纽厄尔、西蒙包括后来的尼尔逊,都是这个学派的代表⼈物。
另⼀个是连接主义
(Connectionism)
,他强调的是从仿⽣学的⻆度,来模拟⽣物体的结构,其中重点就是⼈脑的结构(其实就是深度学习领域的范畴)。这个学派认为只要⽤计算机硬件模拟出⼈脑神经⽹络的结构,最终计算机系统就能够模拟出⼈的认知以及决策的过程。
另外还有⼀个学派,⾏为主义
(Actionism)
,他强调的是从⾏为⻆度来⽤计算机模拟⽣物,主要是昆⾍,的⾏为。他们早期的研究⼯作重点是模拟⼈在控制过程中的智能⾏为和作⽤,⽐如⾃寻优、⾃适应、⾃镇定、⾃组织、⾃学习 等控制论系统的研究,并进⾏"
控制论动物
"
的研究。但是这个学派是从
20
世纪末期才出现的新⾯孔,到⽬前为⽌,⽆论是影响⼒,还是研究成果,都与前⾯两个学派差距还⽐较⼤。
2
、机器学习数据形式
机器学习有三个关键词: 数据,模型,预测。机器学习强调从历史数据中⾃动学习,对数据之间的规律进⾏归纳,形成模型,然后⽤模型来对实际问题进⾏预测。这个过程跟⼈类理解⼀个事物的过程是很类似的。回想⼀下,⼈类去分辨猫和狗、或者预测房价未来的⾛势,其实也是这样⼀个过程。⼈需要从⼤量的⽇常⽣活经验中归纳出⼀系列的规律,然后在⾯临具体问题时,就可以从众多规律中找到最优化的规律,来解决⽇常问题。
3、机器学习的数据集构成
机器学习能够处理的数据由特征值
+
⽬标值组成。下面以房价数据为列,简单阐释一下机器学习的数据集构成(如下图所示)
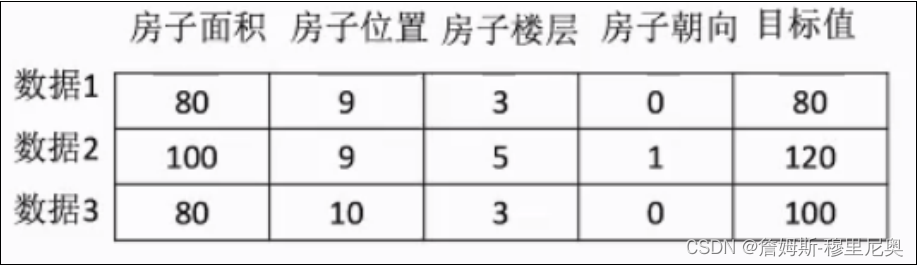
例如上图为⼀个房价数据,每⼀⾏数据称之为⼀个样本。多个样本就构成了⼀个数据集。⽽在每个样本当中,前⾯部分房⼦的各个属性构成了特征值,代表样本的各个数据特征。⽽最后的⽬标值相当于是样本的结果。⽽机器学习的过程就是要从已有的房价数据中学习到房价之间的规律,然后以后再来⼀个房⼦,我们就可以根据房⼦的这些属性,预测他的房价是多少。⽽在数据集中,特征值是必不可少的,⼀般就是原始数据。⽽⽬标值有可能需要通过对数据进⾏处理来获得,但是有些数据集是可以没有⽬标值的,而无目标值的数据集,就是需要通过机器学习算法来清洗筛选。
4、机器学习算法的分类
机器学习涉及到⾮常多的数学算法。对这些数学算法,通常会根据⽬标值的类型进⾏简单分类。已下为机器学习算法的大致分类:
分类算法: 这⼀类问题的⽬标值是有限的⼏个离散值。例如我们对动物进⾏分类。常⽤的算法有:
k
近邻算法、⻉叶斯算法、决策树与随机森林、逻辑回归等。
回归算法: 这⼀类问题的⽬标值是⼀组连续值。例如对房价的预测。常⽤的算法有:线性回归、岭回归等。
⽆监督学习:这⼀类问题没有⽬标值。也就是说,没有⼀个固定的⽬标去监督机器学习的过程。例如我们常说的⼈以类聚,物以群分。我们通常会需要将所有客⼾区分成⼀个个具有相似特征的客⼾群,但是我们也不知道要把客⼾分成哪些群⽐较合适。这个时候,就可以⽤⽆监督学习,让机器学习去找出最具有区分度的划分⽅式。常⽤的算法有 k-Means
分类算法。
与⽆监督学习对应的,分类算法和回归算法都是有⽬标值,也就是有具体⽬标的机器学习算法,他们就统称为监督学习。
5、怎么获取数据集?
以下获取数据集的方式推荐供参考使用
UCI : http://archive.ics.uci.edu/ml/ 这个⽹站上维护了很多经典的数据集。kaggle : https://www.kaggle.com/ ⼀个综合性的机器学习竞赛平台。上⾯会开放很多数据集,开展很多机器学习的竞赛。有很多都是⼀些公司⾃⼰处理不了的实际数据,数据集的质量通常都是⽐较⾼的。同时也有很多别⼈分享的基础教程以及算法分享。
6、机器学习的工具之特征工程
机器学习通过数据收集-》数据清洗-》模型训练-》模型优化这一系列过程,提炼出自己的机器算法,而通过这一算法,针对同一个数据集上进行训练,并且把数据集的特征值拆分为不同层次时,得出的结果往往会有差异。举个例子,我们看一个kaggle上的竞赛结果,如下图所示:
可以看到,针对同一个问题,同样的数据集,竞赛中却跑出来了非常多不同的成绩。那大家想一下,数据集是一样的,算法也就那么几种,这些顶级竞赛者肯定也都懂。那他们应该要跑出同样的结果才对。那为什么还能出现这么多结果,排出个名次来呢?这个区别就来自于特征工程。
业界流传一句非常经典的话:
数据和特征决定了机器学习的上限,而模型和算法
只是不断逼近这个上限而已
。那要怎么才能逼近呢?这就要靠特征工程。
特征工程是使用专业背景知识和技巧,处理数据,使得特征能够在机器学习算法
上发挥更好的作用的过程。也就是说,
特征工程会直接影响机器学习的效率
。而这
些各种机器学习竞赛,之所以分出不同的高下,很大一部分原因就在于他们的特征
工程处理方式不同。
7、常用的特征工程方法
特征工程的方法很多,今日时间有限,后续文章再做详解。。。。















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









