






1、
readme中说执行get_label_word.py文件时要用bert模型
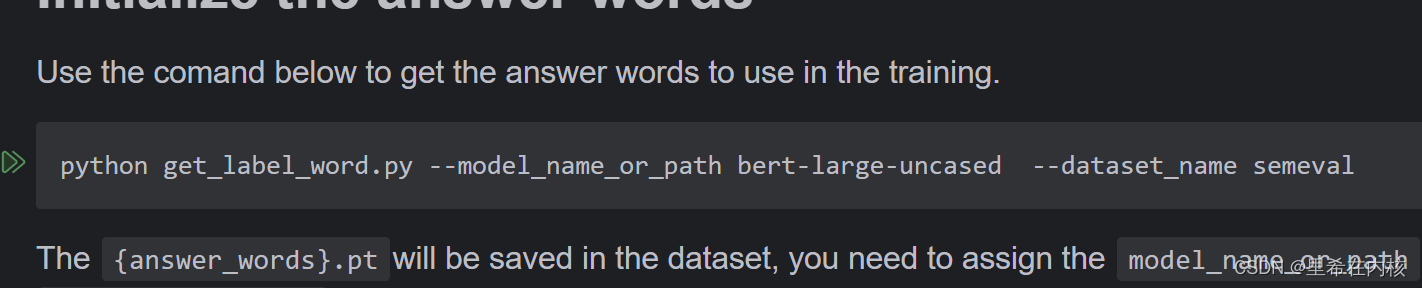
但是在训练模型时又用的roberta模型
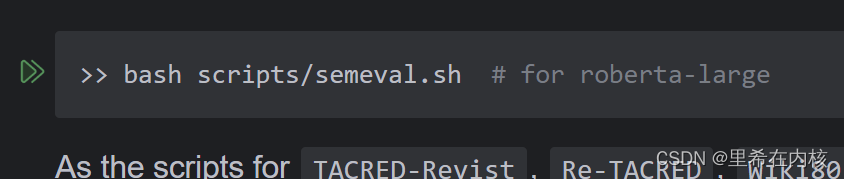
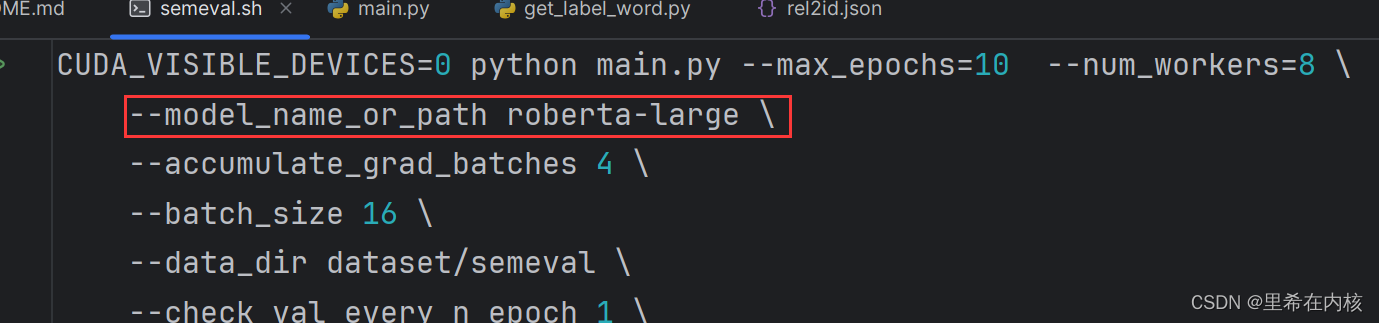
所以这里应该是有问题的。修改命令,执行get_label_word.py文件时使用roberta-large模型

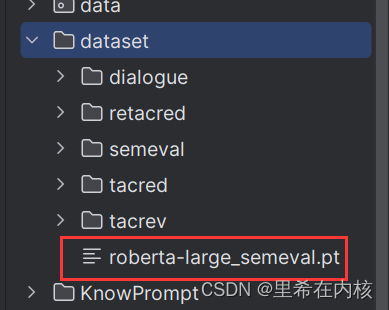
代码正常运行的标志
2、
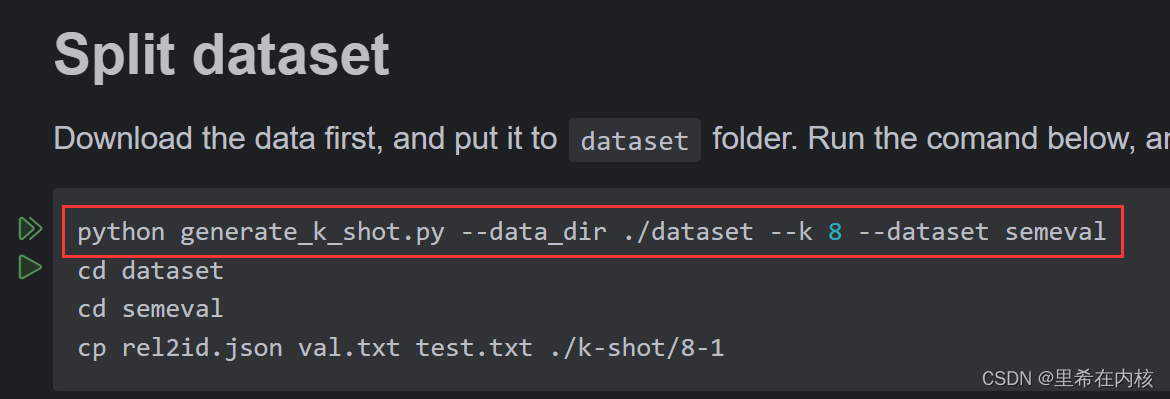
这个命令没有什么问题,直接在终端执行就可以
因为默认的种子是[1,2,3,4,5],所以这个文件执行成功的标志是dataset/semeval/k-shot/这个路径下会有8-1到8-5这5个目录
然后把dataset/semeval这个路径下的rel2id.json、val.txt、test.txt这三个文件复制到k-shot下的8-1文件中(图中的命令好像是linux下的命令,windows下不能用)
代码运行成功标志
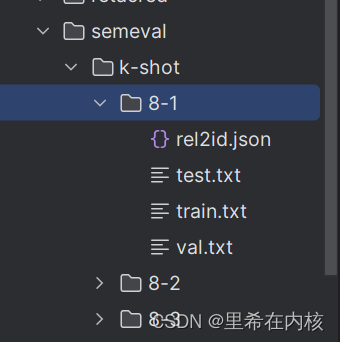
3、
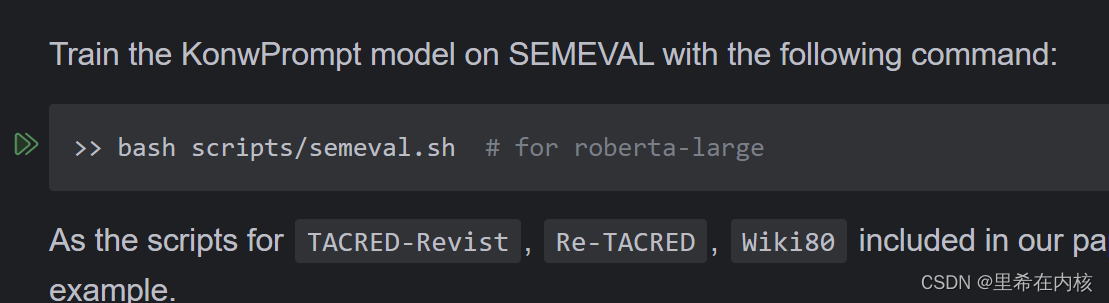
这一步就是训练模型了。这个命令是linux下的命令,windows不能用,然后对命令进行修改,如下:
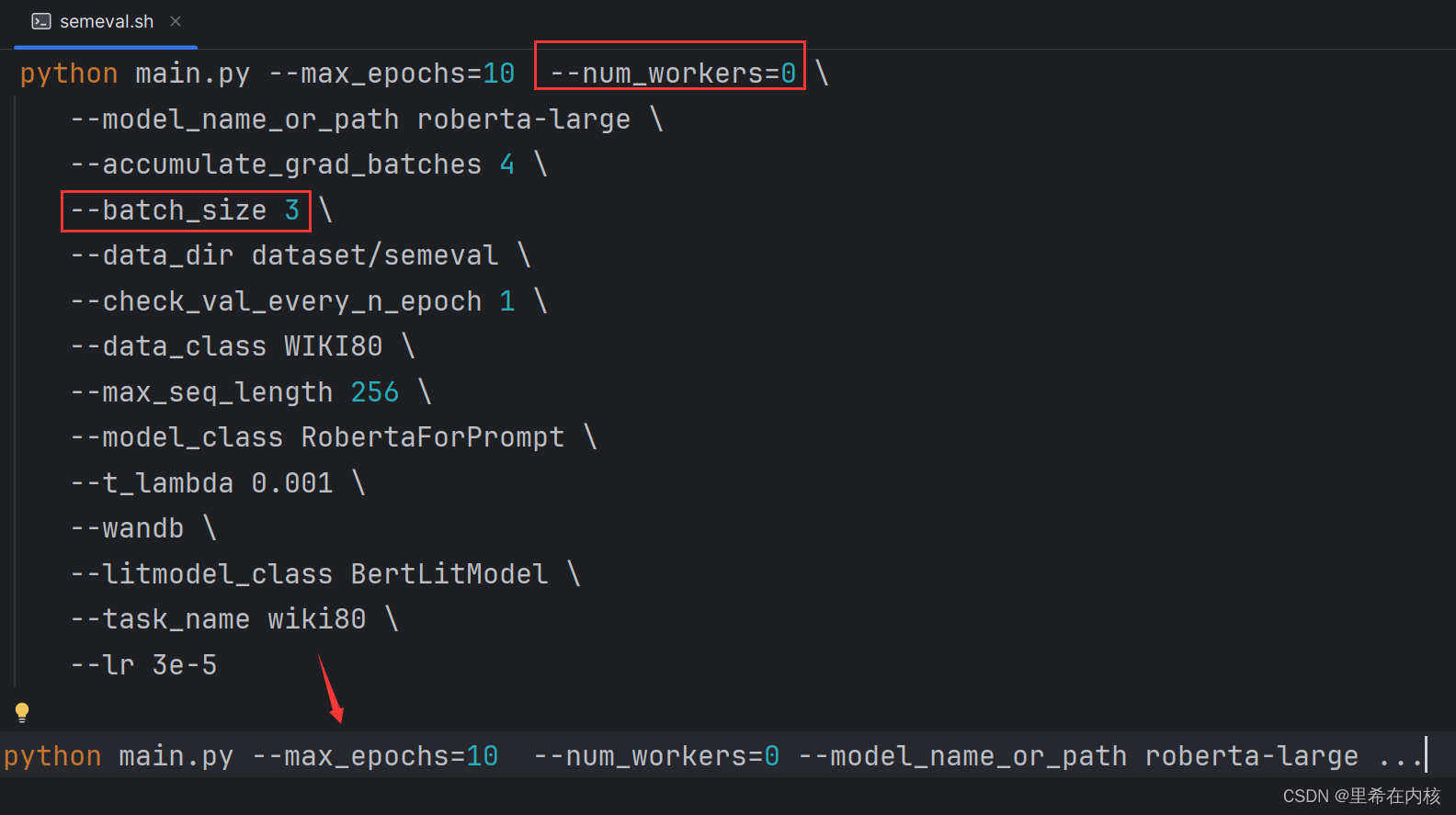
我的显卡是4060,8gb显存。这个模型好像有20多层,我只有在把num_work关了,把batch_size设为3的情况下才能跑模型,要不然显存就爆了
然后把修改后的命令复制到终端执行,就能正常训练了















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









