






统计了14天的气象数据(指标包括outlook,temperature,humidity,windy),并已知这些天气是否打球(play)。如果给出新一天的气象指标数据:sunny,cool,high,TRUE,判断一下会不会去打球。
| outlook | temperature | humidity | windy | play |
| sunny | hot | high | false | no |
| sunny | hot | high | true | no |
| overcast | hot | high | false | yes |
| rainy | mild | high | false | yes |
| rainy | cool | normal | false | yes |
| rainy | cool | normal | true | no |
| overcast | cool | normal | true | yes |
| sunny | mild | high | false | no |
| sunny | cool | normal | false | yes |
| rainy | mild | normal | false | yes |
| sunny | mild | normal | true | yes |
| overcast | mild | high | true | yes |
| overcast | hot | normal | false | yes |
| rainy | mild | high | true | no |
这个问题当然可以用朴素贝叶斯法求解,分别计算在给定天气条件下打球和不打球的概率,选概率大者作为推测结果。
现在我们使用ID3归纳决策树的方法来求解该问题。
预备知识:信息熵
熵是无序性(或不确定性)的度量指标。假如事件A的全概率划分是(A1,A2,...,An),每部分发生的概率是(p1,p2,...,pn),那信息熵定义为:

通常以2为底数,所以信息熵的单位是bit。
补充两个对数去处公式:
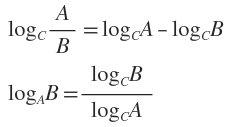
ID3算法
构造树的基本想法是随着树深度的增加,节点的熵迅速地降低。熵降低的速度越快越好,这样我们有望得到一棵高度最矮的决策树。
在没有给定任何天气信息时,根据历史数据,我们只知道新的一天打球的概率是9/14,不打的概率是5/14。此时的熵为:
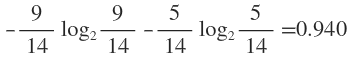
属性有4个:outlook,temperature,humidity,windy。我们首先要决定哪个属性作树的根节点。
对每项指标分别统计:在不同的取值下打球和不打球的次数。
下面我们计算当已知变量outlook的值时,信息熵为多少。
outlook=sunny时,2/5的概率打球,3/5的概率不打球。entropy=0.971
outlook=overcast时,entropy=0
outlook=rainy时,entropy=0.971
而根据历史统计数据,outlook取值为sunny、overcast、rainy的概率分别是5/14、4/14、5/14,所以当已知变量outlook的值时,信息熵为:5/14 × 0.971 + 4/14 × 0 + 5/14 × 0.971 = 0.693
这样的话系统熵就从0.940下降到了0.693,信息增溢gain(outlook)为0.940-0.693=0.247
同样可以计算出gain(temperature)=0.029,gain(humidity)=0.152,gain(windy)=0.048。
gain(outlook)最大(即outlook在第一步使系统的信息熵下降得最快),所以决策树的根节点就取outlook。

接下来要确定N1取temperature、humidity还是windy?在已知outlook=sunny的情况,根据历史数据,我们作出类似table 2的一张表,分别计算gain(temperature)、gain(humidity)和gain(windy),选最大者为N1。
依此类推,构造决策树。当系统的信息熵降为0时,就没有必要再往下构造决策树了,此时叶子节点都是纯的--这是理想情况。最坏的情况下,决策树的高度为属性(决策变量)的个数,叶子节点不纯(这意味着我们要以一定的概率来作出决策)。
例2
分类预测算法属于有指导学习,方法是通过训练数据,按照参考属性对目标属性的依赖程度对参考属性分级别处理,这种分级别处理体现在创建决策树,目的是通过生成的判别树,产生规则,用来判断以后的数据。以如下数据为例:

共14条记录,目标属性是,是否买电脑,共有两个情况,yes或者no。参考属性有4种情况,分别是,age,income,student,credit_rating。属性age有3种取值情况,分别是,youth,middle_aged,senior,属性income有3种取值情况,分别是,high,medium,low,属性student有2种取值情况,分别是,no,yes,属性credit_rating有2种取值情况,分别是fair,excellent。我们先求参考属性的信息熵:
 ,式中的5表示5个no,9表示9个yes,14是总的记录数。接下来我们求各个参考属性在取各自的值对应目标属性的信息熵,以属性age为例,有3种取值情况,分别是youth,middle_aged,senior,先考虑youth,youth共出现5次,3次no,2次yes,于是信息熵:
,式中的5表示5个no,9表示9个yes,14是总的记录数。接下来我们求各个参考属性在取各自的值对应目标属性的信息熵,以属性age为例,有3种取值情况,分别是youth,middle_aged,senior,先考虑youth,youth共出现5次,3次no,2次yes,于是信息熵:
类似得到middle_aged和senior的信息熵,分别是:0和0.971。整个属性age的信息熵应该是它们的加权平均值:
 。下面引入信息增益(information gain)这个概念,用Gain(D)表示,该概念是指信息熵的有效减少量,该量越高,表明目标属性在该参考属性那失去的信息熵越多,那么该属性越应该在决策树的上层(如果不好理解,可以用极限的方法,即假如在age属性上,当为youth时全部是on,当为middle时也全部是no,当为senior时全不是yes,那么Hage(D)=0)。
。下面引入信息增益(information gain)这个概念,用Gain(D)表示,该概念是指信息熵的有效减少量,该量越高,表明目标属性在该参考属性那失去的信息熵越多,那么该属性越应该在决策树的上层(如果不好理解,可以用极限的方法,即假如在age属性上,当为youth时全部是on,当为middle时也全部是no,当为senior时全不是yes,那么Hage(D)=0)。 ,类似可以求出Gain(income)=0.029,Gain(stduent)=0.151,Gain(credit_rating)=0.048。最大值为Gain(age),所以首先按照参考属性age,将数据分为3类,如下:
,类似可以求出Gain(income)=0.029,Gain(stduent)=0.151,Gain(credit_rating)=0.048。最大值为Gain(age),所以首先按照参考属性age,将数据分为3类,如下:
然后分别按照上面的方法递归的分类。递归终止的条件是,1,当分到某类时,目标属性全是一个值,如这里当年龄取middle_aged时,目标属性全是yes。2,当分到某类时,某个值的比例达到了给定的阈值,如这里当年龄取youth时,有60%的是no,当然实际的阈值远远大于60%。















 4463
4463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









