






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
背景介绍
- 清华大学团队,开源。
- ChatGLM-6B目前在GitHub中star数已超3.8万。
- 2022年11月的斯坦福全球主流大模型测评中,GLM-130B是亚洲地区唯一入选的,表现不错。
- ChatGLM是千亿级别,ChatGLM-6B是60亿参数。
- 参考视频:官方教程
GLM论文地址
ChatGLM的基础论文《GLM: General Language Model Pretraining with Autoregressive Blank Infifilling》以及《AN OPEN BILINGUAL PRE-TRAINED MODEL》:
题目:《以自回归式空白填充任务预训练的通用语言模型》
论文地址:https://arxiv.org/abs/2103.10360
题目:《一个开放的双语通用预训练模型》
论文地址:https://arxiv.org/abs/2210.02414
这篇博客之前已经有关于GLM论文的阅读:大模型论文阅读系列-GLM: General Language Model Pretraining with Autoregressive Blank Infilling
环境部署与模型下载
第一步就遇到了问题,我本人使用的是服务器,没有sudo权限,安装git-lfs都很费劲。
按照chatgpt的帮助,成功安装了git-lfs:
#先下载压缩包,可能具体代码会有所变化
wget https://github.com/git-lfs/git-lfs/releases/download/v2.14.1/git-lfs-linux-amd64-v2.14.1.tar.gz
#解压文件
tar -zxvf git-lfs-linux-amd64-v2.14.1.tar.gz
#添加环境变量
~/.bashrc
export PATH=/path/to/git-lfs/bin:$PATH
#最后验证安装,能输出版本就成功
git lfs version
接下来简单的使用conda创建虚拟环境并克隆项目:
git clone https://github.com/THUDM/ChatGLM-6B.git
配环境:
pip install -r requirements.txt
#建议先去pytorch官网使用对应cuda版本的指令下载pytorch,不直接使用requirements.txt安装,不然会是CPU版本。
接下来是很头疼的模型部分:
由于我使用的是服务器,GPU是2080ti,课程中使用的fp16版本模型需要的内存与显存对于我的机器不适用。经过一整天的反复摸索,选择了手动下载,远程传输,并修改代码:
- 选择int4分支的模型,将界面的所有内容下载至一个文件夹。(此处有坑,先别做,往下看。,实际是要下载int模型https://huggingface.co/THUDM/chatglm-6b-int4/tree/main)https://huggingface.co/THUDM/chatglm-6b/tree/int4
我使用的是第二块GPU,使用软链接ln -s把/opt位置下的模型链接到项目目录,cli_demo.py修改以下两行代码,把tokenizer和model的位置修改为自己刚才放huggingface下载内容的文件夹:
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).half().cuda(1)
python cli_demo.py
至此,终于终于终于能跑起来了!!!兴奋!!

接下来终于到了fine-tuning部分!
Fine-tuning
Mixed Precision
浮点数精度高时,对于计算资源要求很高,所以课程使用fp16。(哈哈,我使用的int4,服啦)

模型更新时,一些很小的梯度,比如假设<10e-27,对于训练几乎无影响。但是一些比如介于10e-27和10e-16之间的数可能会有影响。
Dynamic Loss Scaling是深度学习中用来解决在使用低精度算术(如16位浮点数)进行训练时可能遇到的数值不稳定问题的一种技术。损失缩放的目的是为了防止在低精度计算中出现的梯度下溢问题,即梯度过小而被四舍五入到0,导致模型无法学习。通过动态调整一个缩放因子来实现,这个缩放因子乘以计算出的损失,从而放大梯度值,避免梯度过小而消失。训练过程中,如果梯度出现非数(NaN)或无穷大(Inf)值,表明缩放过头,系统会降低缩放因子并丢弃当前的梯度更新;如果梯度正常,则逐渐增加缩放因子,以保持数值稳定性和训练效率。这种方法使得模型可以有效地使用低精度计算进行训练,同时减少因数值不稳定而导致的训练问题。
也就是说混合精度训练:模型大部分时刻用fp16进行计算与传输,对于某些关键计算,如损失函数的计算和参数更新,计算仍然以FP32进行。
ZeRO
ZeRO (Zero Redundancy Optimizer) 是一种创新的优化器,旨在解决大规模深度学习模型训练时的内存瓶颈问题。它通过优化数据和模型状态(如梯度、参数和优化器状态)的存储,显著减少了每个GPU所需的内存占用。ZeRO的核心思想是将这些状态在训练过程中的所有处理器间分配,从而减少每个处理器的内存负担。ZeRO分为不同的优化级别,如ZeRO-DP(数据并行)、ZeRO-R(冗余优化)和ZeRO-Offload(卸载),每个级别针对不同的内存优化方面。
Data Parallel (数据并行),数据并行是并行计算的一种形式,其中模型的每个副本都在不同的处理器(如GPU)上运行,但所有副本都处理不同的数据子集。在数据并行中,模型参数在每次迭代后通过所有处理器同步,以保证学习过程的一致性。这种方式可以有效地扩大训练数据集的处理能力,因为它允许模型同时在多个处理器上训练不同的数据批次。缺点:冗余非常大。
Model Parallel (模型并行),模型并行是另一种并行计算的形式,它将模型的不同部分分布在不同的处理器上。与数据并行不同,模型并行是将模型本身分割成多个部分,每个部分在不同的处理器上运行。这对于那些太大而无法在单个处理器上完全加载的模型特别有用。模型并行需要仔细设计,以减少不同处理器之间的通信开销,并保证模型各部分的协调运作。缺点:通讯很慢。
总结来说,ZeRO提供了一种优化大规模模型训练的内存使用的方法,数据并行允许模型在多个处理器上同时训练不同数据批次,而模型并行则将模型本身分布在多个处理器上,以适应大型模型的内存需求。
(这部分没看懂,建议自己看原视频)
P-tuning v2
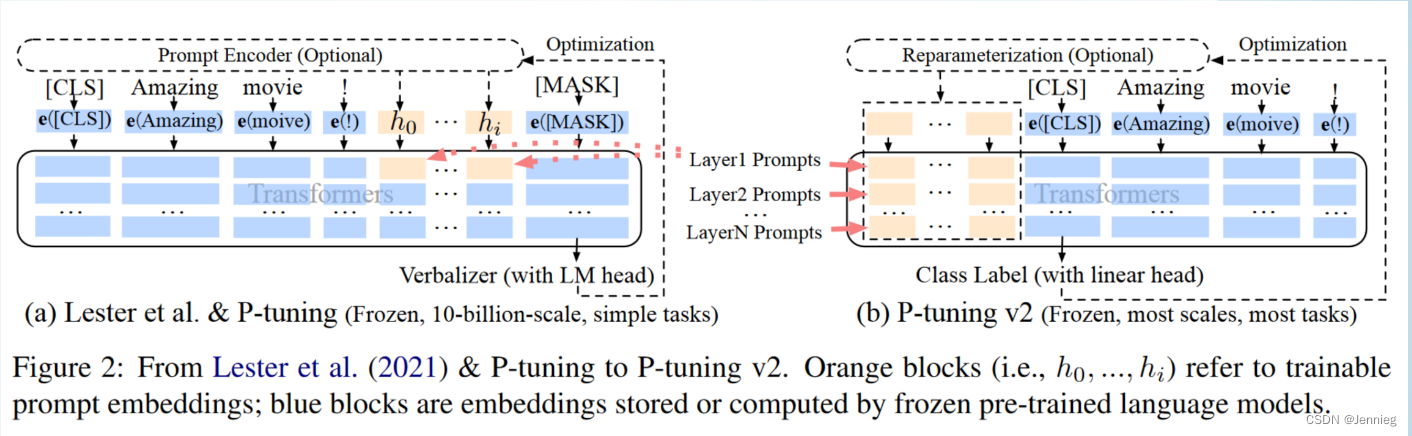
prompt-tuning与P-tuning v2:原来做法是在输入的前面或后面添加embedding,只训练这些embedding。改进时在每个层都加入prompts,能节省资源以及时间,效果接近fine-tune。
P-tuning @ ChatGLM-6B
pip install rouge_chinese nltk jieba datasets
#下载数据集并解压缩:
https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
tar -xzvf AdvertiseGen.tar.gz
然后修改ptuning文件夹下的train.sh:
CUDA_VISIBLE_DEVICES=1 python3 main.py \
--do_train \
--train_file ../AdvertiseGen/train.json \
--validation_file ../AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ../chatglm-6b \
一定要改对,…/表示向上一级
然后报错:
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'ChatGLMModel' object has no attribute 'prefix_encoder'
查了一大堆资料之后发现:
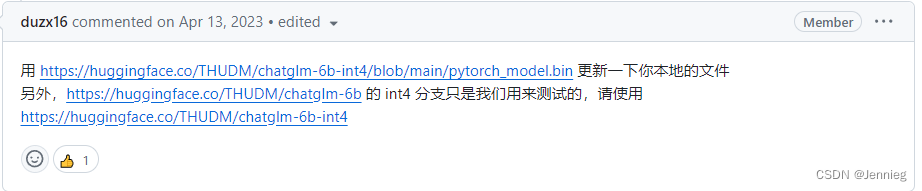
然后又是下载文件了…
遇到新的问题:
RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
参考issue成功解决
然后由于当时试图在int4分支训练,解决问题时试了很多方法,出现了新的问题:
AttributeError: 'Seq2SeqTrainer' object has no attribute 'is_deepspeed_enabled'
解决:参考issue,将transormers版本还原为4.27.1

至此成功开始训练。
第二天,训练结束:
















 4845
4845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









