






系列文章目录
大模型论文阅读系列-GLM: General Language Model Pretraining with Autoregressive Blank Infilling
文章目录
前言
论文地址:ICCV2023
Segment Anything,分割一切,Meta团队2023年引起巨大反响的工作,将预训练语言模型的思想与架构引入视觉领域。
一、摘要与简介

论文入目能看到的这张图简单的概括了 What is SAM:任务,模型以及数据。其中任务部分最重要的是,如何将分割设计成像NLP一样的能通过使用prompt进行的任务。
摘要:介绍本文的贡献,建立了至今最大的分割数据集(果然大模型时代,data is all you need.),数据集包含超过十亿个掩码。模型通过设计能进行zero-shot任务,代码在GitHub上已开源:SAM代码。
介绍:主要讲预训练大模型对NLP领域的重要性,并回顾大模型目前在视觉领域的探索:CLIP在多模态任务中的作用,以及DALLE在图像生成中的影响。受此影响,本文的目的是设计一个能通过prompt进行操作的模型,解决下游各种分割任务。为此,需要一个多样化的大规模数据源,并需要一个支持灵活提示的模型,能够实时输出分割掩码以支持交互式使用。
SAM设计
任务:提出可提示的分割任务,其目标是给定任何分割提示返回有效的分割掩码,提示可以是点,目标框,掩码或文字信息。要求是当prompt指向不明确,即可能对应多个对象时,输出至少应该是这些可能对象之一。
模型:通过图像编码器计算图像嵌入,提示编码器计算prompt对应embedding,以及一个轻量mask解码器将两种信息进行融合,实现分割掩码的预测。可以重复使用相同的图像嵌入与不同的提示,实现成本分摊。对应任务要求,SAM模型设计为单个提示预测多个掩码。
数据工程与数据集:与语言任务能简单的在线获取数据不同,SAM的解决方案是构建一种数据工程,与模型在循环中实现数据集注释。工程包括三部分:辅助手动,半自动以及全自动。在第一阶段,SAM协助标注者标注掩码。在第二阶段,SAM可以通过提示可能的对象位置自动生成一部分对象的掩码,标注者标注剩余的对象,帮助增加掩码的多样性。在最后阶段,我们用规则网格的前景点提示SAM,平均每张图片产生约100个高质量掩码。最终数据集SA-1B包含超过10亿个掩码,1100万张图像。

文章中展示的图像即使包括大于500个mask,也有不错的表现。
二、Segment Anything Task
灵感来源于NLP模型中预测下一个token的预训练任务。任务前边讲过了,这里写下预训练以及zero-shot。
预训练:模拟了每个训练样本的一系列提示(例如,点、边框、掩模),并将模型的掩模预测与真实标签进行比较。交互式分割是在用户输入足够多的mask之后预测最终mask,本任务是需要始终预测。
zero-shot transfer:理论上通过适当的prompt设计能够实现下游任务。例如,目标检测结果可以作为模型的prompt输入。
三、Segment Anything Model
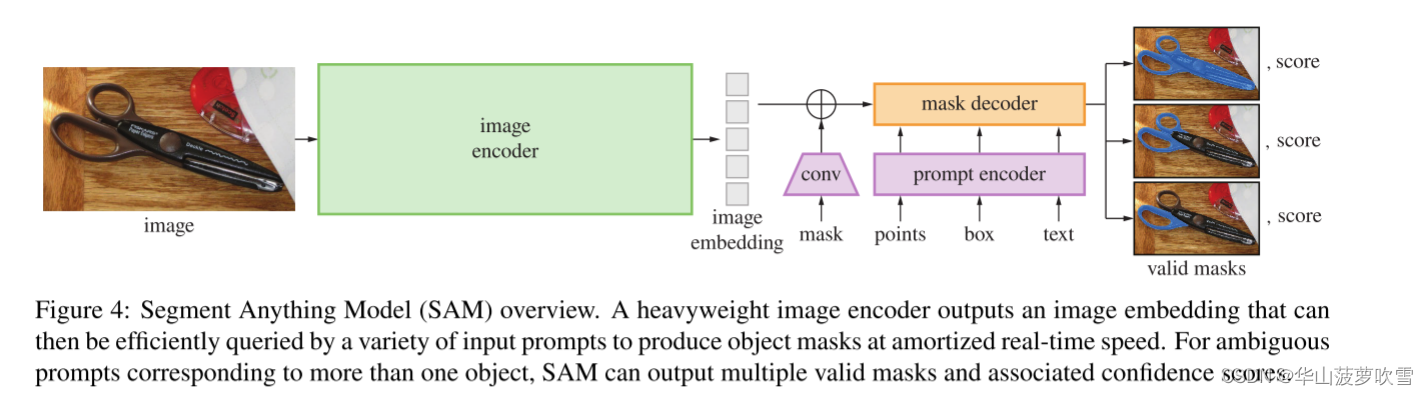
模型如前所述,主要包括三个部分:图像编码器(绿色部分),提示编码器(粉色)以及掩码解码器(橙色)。模型建立在视觉transformer基础上。图像编码器使用的是预训练ViT。提示编码器使用CLIP处理文本,位置编码处理点和框,掩膜提示使用卷积嵌入。掩码解码器使用transformer的decoder块的修改版本等,最后通过MLP将token映射到动态线性分类器,并计算概率。
此外为了解决提示具有的模糊与歧义,发现设计输出三个掩码能解决绝大部分问题。
四、Segment Anything Data Engine
主要包括之前说的三个阶段:
**辅助手动标注阶段:**专业标注员使用基于浏览器的交互式分割工具手动标注掩模,这个工具由SAM模型支持。标注过程中,标注员可以使用精确的“画笔”和“橡皮擦”工具进行微调。这个阶段没有对标注对象施加语义限制,标注员自由地标注了“物体”和“事物”。初始时,SAM使用公共分割数据集进行训练,后来仅使用新标注的掩模进行再训练,模型经过多次(6次)迭代更新。
**半自动阶段:**目的是增加掩模的多样性,提高模型的分割能力。首先自动检测高置信度掩模,然后要求标注员补充未标注的物体。通过这种方式,收集了更多多样性的掩模,总共获得了约1020万个掩模。
**全自动阶段:**最后阶段完全自动化。使用一个规则网格对模型进行提示,为每个点预测可能对应的有效掩模集。利用模型的IoU预测模块选择置信掩模,并通过非最大抑制(NMS)过滤重复掩模。最终,通过这种全自动方法,在整个数据集的1100万张图片上生成了11亿个高质量掩模。
五、讨论与总结
(实验结果部分我没写)
SAM在总体上表现良好,但可能会错过细小结构,或虚构出微小部分(大概是大模型幻觉)。虽然SAM能执行许多任务,如何设计简单的提示实现语义和全景分割仍不明确。















 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









