







1、在MR程序中,我们认为一个MR程序就是一个Job,Job会分为两个阶段执行,第一个阶段会分成很多的mapTask,第二个阶段会分成很多的reduceTask。Task是两个阶段当中的小任务。
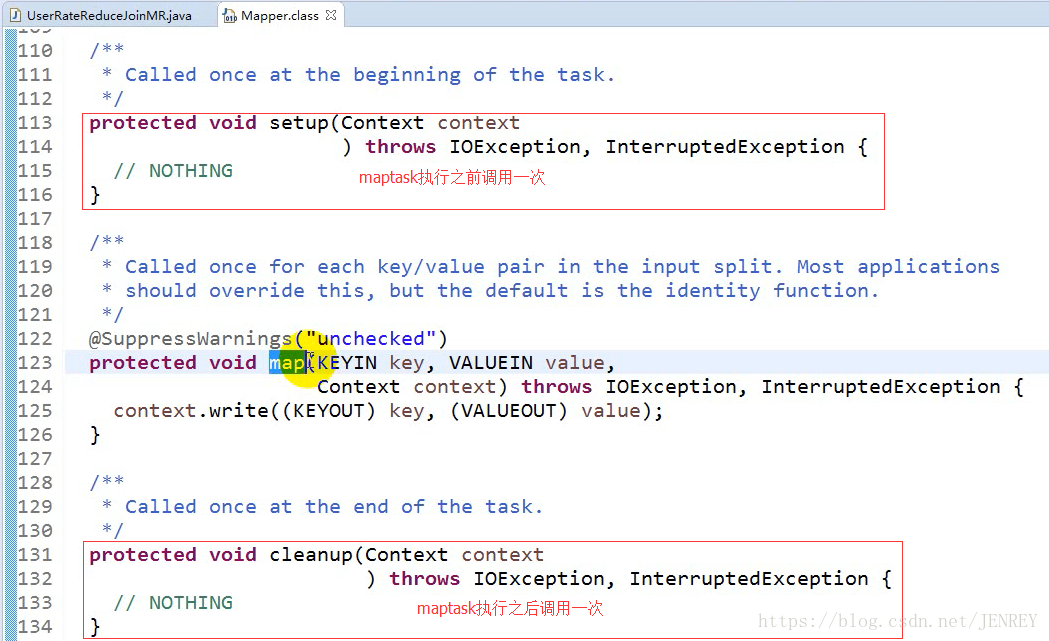
2、在编写Mapper组件的时候,要使用继承的方式去继承Mapper这个普通类,同时要用自己的逻辑改写里面的map方法(默认的是原样输出)
3、map()方法中的value就是读取到的一行数据,所以要读取很多行就需要调用多次map()方法,Mapper类里面有个run()方法,会一直调用map()方法。

key就是value在这个文件中的起始偏移量。
4、MR编程框架中的所有存储数据的类必须都是Writable借口的类。必须要实现序列化的功能。Text相当于就是String可序列化的一个类型。
5、在编写Reducer组件的时候,要使用继承的方式去继承Reducer这个普通类,同时要用自己的逻辑改写里面的reduce方法(默认的是原样输出),参数的意义就是接收到的key相同的一组keyvalue中的key,也就是reduce方法中的第一个参数。
reduce方法每次被调用一次的时候都会被传入一组key-value(都是key相同)。
values就是key相同的一组key-value中的value的集合,并且提前帮你变成了迭代器。
reduce方法的调用次数:就是mapper阶段输出的key-value中的不同的key的个数。
map方法的调用次数:就是这个输入的文件有多少行就调用多少次。
6、MR的内部有一个默认的规则就是hash散列,用来帮你在shuffle阶段把key相同的key-value全部拿到一起来。

7、在默认情况下,输入数据的组件是使用默认的数据读取组件,所以数据输入类型已经被固定了。LongWritable,Text
map()方法的context就是全局的上下文变量(容器对象,包含了,任何你想在编程中获取的数据信息);
8、reduce方法的参数:key就是key相同的一组key-value的key,values就是key相同的一组key-value中的value的集合。context就是上下文容器对象。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
*
* 自己写的单词计数MR程序
*
*/
public class MyWordCount {
/**
* 程序的入口
* @throws Exception
*/
public static void main(String[] args) throws Exception {
/**
* 解析main的参数
*/
if(args.length < 2){
System.out.println("sssssss");
System.exit(1);
}
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
Job job = Job.getInstance(conf);
// 设置jar包相关的信息,系统会自动帮你把jar发送到别的节点
job.setJarByClass(MyWordCount.class);
// 设置mapper和reducer组件
job.setMapperClass(MyWCMapper.class);
job.setReducerClass(MyWCReducer.class);
// job.setCombinerClass(MyWCReducer.class); //用于提高效率的,任务量比较小可以不写
// 设置mapper和reducer的输出key-value类型
// 泛型是JDK在后期版本中提供的一个新特性,只在编译时生效,运行时没有泛型这个概念。 泛型擦除
// 为什么不用设置输入的key-value类型? mapper的输入由数据输入组件定
//Map输出类型和Reduce输出类型一样就可以不用写Map的输出类型
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 默认的数据输入组件: TextInputFormat
job.setInputFormatClass(TextInputFormat.class);
/***
* 设置输入输出路径
*/
String inputPath = args[0];
String outputPath = args[1];
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
/**
* 提高任务,等待完成
*/
boolean isDone = job.waitForCompletion(true);
System.exit(isDone ? 0 : 1);
}
/**
*
* MyWCMapper它是一个组件
*
* 该组件有输入数据和输出数据
*
* 它的输入和输出都是key-value形式
*
*
* 在默认情况下,输入数据的组件是使用默认的数据读取组件。所以这个类型已经被固定了。
*
* KYEIN : long LongWritable
* VALUEIN : string Text
*
* KEYOUT : string Text
* VALUEOUT : int IntWritable
*
* 但是要记住。 在mapreduce编程模型中,所有参与序列化的类,必须是Writable接口的子类
*/
public static class MyWCMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
/**
* key : 当前读取到的value在文件中的起始偏移量
* value : 读取到的一行数据
* context : 全局的上下文变量(容器对象,包含了,任何你想在编程中获取的数据信息)
*
* map方法接收一个key-value
* 输出0或者多个key-value
*/
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
/**
* 核心作用: 就是把map方法的第二个参数,就是读取到的一行数据,按照业务逻辑进行处理,然后写出key-value
*/
String[] words = value.toString().split(" ");
for(String word: words){
context.write(new Text(word), new IntWritable(1));
}
}
}
public static class MyWCReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
/**
* key ;key相同的一组key-value的key
*
* values : key相同的一组key-value中的value的集合
*
* context : 上下文容器对象
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for(IntWritable intValue :values){
sum += intValue.get();
}
/**
* 最终需要输出的key-value是 : 某个单词出现了几次
*
* 某个单词: key
* 几次: sum
*/
context.write(key, new IntWritable(sum));
}
}
}

import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ModelMR {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
// System.setProperty("HADOOP_USER_NAME", "hadoop");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(ModelMR.class);
job.setMapperClass(MR_Mapper.class);
job.setReducerClass(MR_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path inputPath = new Path("/");
Path outputPath = new Path("/");
FileInputFormat.setInputPaths(job, inputPath);
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean isDone = job.waitForCompletion(true);
System.exit(isDone ? 0 : 1);
}
public static class MR_Mapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
}
}
public static class MR_Reducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
}
}
}
ReduceJoin:
package com.ghgj.mr.exercise.join;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 需求:select users.*, ratings.* from users join ratings on users.userid = ratings.userid;
*/
public class UserRateReduceJoinMR {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
// System.setProperty("HADOOP_USER_NAME", "hadoop");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(UserRateReduceJoinMR.class);
job.setMapperClass(UserRateReduceJoinMR_Mapper.class);
job.setReducerClass(UserRateReduceJoinMR_Reducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
Path inputPath = new Path("E:\\bigdata\\user_rate\\input");
Path outputPath = new Path("E:\\bigdata\\user_rate\\output_reduce_1");
FileInputFormat.setInputPaths(job, inputPath);
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean isDone = job.waitForCompletion(true);
System.exit(isDone ? 0 : 1);
}
public static class UserRateReduceJoinMR_Mapper extends Mapper<LongWritable, Text, Text, Text>{
/**
* 怎么获取文件名?
* 如果有一个初始化方法,并且这个初始化方法还会给我们传一个参数: context 那就完美了。
*/
String fileName = "";
/**
* 对应关系: InputSplit = FileSplit = 一个container == 一个JVM进程 -- 一个MapTask
*/
protected void setup(Context context) throws IOException ,InterruptedException {
InputSplit inputSplit = context.getInputSplit();
FileSplit fss = (FileSplit)inputSplit;
fileName = fss.getPath().getName();
};
/**
* value 的值有两种情况:
*
* ratings 1::1193::5::978300760
* users 1::M::35::1::06810
*
* 现有如此三份数据:
1、users.dat 数据格式为: 2::M::56::16::70072
对应字段为:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
对应字段中文解释:用户id,性别,年龄,职业,邮政编码
3、ratings.dat 数据格式为: 1::1193::5::978300760
对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
对应字段中文解释:用户ID,电影ID,评分,评分时间戳
用户ID,电影ID,评分,评分时间戳,性别,年龄,职业,邮政编码,电影名字,电影类型
userid, movieId, rate, ts, gender, age, occupation, zipcode, movieName, movieType
*
*/
Text keyOut = new Text();
Text valueOut = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("::");
if(fileName.equals("users.dat")){
String keyStr = split[0];
String valueStr = "1-"+split[1] + "::" + split[2] + "::" + split[3] + "::" + split[4];
keyOut.set(keyStr);
valueOut.set(valueStr);
context.write(keyOut, valueOut);
}else if(fileName.equals("ratings.dat")){
String keyStr = split[0];
String valueStr = "2-"+split[1] + "::" + split[2] + "::" + split[3];
keyOut.set(keyStr);
valueOut.set(valueStr);
context.write(keyOut, valueOut);
}
}
}
public static class UserRateReduceJoinMR_Reducer extends Reducer<Text, Text, NullWritable, Text>{
/**
* 这两个容器分别是用来存储对应文件的key_value的
*
* 如果两张表连接不上。那么就有可能其中一个容器为空
*
* 不可能出现两张表都是空的情况
*
* 只有在两个容器都不为空的情况下,才能出现连接
*/
private List<String> userinfoList = new ArrayList<String>(); // 1
private List<String> ratinginfoList = new ArrayList<String>(); // 2
Text valueOut = new Text();
/**
* values:
*
* 2-1193::5::978300760
* 1-M::35::1::06810
*/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text t : values){
String[] split = t.toString().split("-");
String flag = split[0];
if(flag.equals("1")){
userinfoList.add(split[1]);
}else{
ratinginfoList.add(split[1]);
}
}
int usersize = userinfoList.size();
int ratesize = ratinginfoList.size();
// 根据分析,这是处理能链接的情况 内连接的结果
if(usersize != 0 && ratesize != 0){
for(int i=0; i<usersize; i++){
for(int j=0; j<ratesize; j++){
String valueOutStr = key.toString()+"::"+ userinfoList.get(i) + "::" + ratinginfoList.get(j);
valueOut.set(valueOutStr);
context.write(NullWritable.get(), valueOut);
}
}
}
/**
* 做外链接: 内连接 + 左表中没有连接上的所有数据
*/
if(usersize != 0 && ratesize == 0){
for(int i=0; i<usersize; i++){
String leftValue = userinfoList.get(i);
// 1 user name age null null null
String rightValue = "::0::-::0";
String outValue = key.toString() + "::" + leftValue + rightValue;
}
}
userinfoList.clear();
ratinginfoList.clear();
}
}
}

package com.ghgj.mr.exercise.join;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 使用 MapJoin的方式来实现以下SQL语句:
*
* select users.*, ratings.* from users join ratings on users.userid = ratings.userid;
*
*
* hadoop jar mapjoin.jar com.ghgj.mr.exercise.join.UserRateMapJoinMR /user_rate/input/ratings.dat /user_rate/output /user_rate/input/users.dat
*/
public class UserRateMapJoinMR {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
System.setProperty("HADOOP_USER_NAME", "hadoop");
FileSystem fs = FileSystem.get(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(UserRateMapJoinMR.class);
job.setMapperClass(UserRateMapJoinMR_Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
/**
* DistributedCache 分布式缓存组件
*
* 作用:就是往对应的mapreduce程序中的mapper阶段中的所有mapTask节点中分发文件
* 因为我们要把小文件放在mapTask节点中,所以需要要用这个,
* 只有这样才能放在hdfs中然后通过流的方式把小文件加载到MapTask的内存(hashMap)中
* 缓存的小文件所在hdfs的目录为/home/hadoop/data/hadoopdata/nm-local-dir/filecache/10
* URI类的构造参数就是对应的要进行分发的小文件的存储路径
* 一般来说MapTask是启动在数据块所在的节点的。但是不排除AppMaster会把任务分配在别的节点中。
*
* mapjoin没法在本地调试。!!!!!必须在集群中运行,所以最后我们打成jar包在集群中执行
*/
job.addCacheFile(new URI(args[2]));
Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
FileInputFormat.setInputPaths(job, inputPath);
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean isDone = job.waitForCompletion(true);
System.exit(isDone ? 0 : 1);
}
/**
* 实现 MapJoin
*
* 问题: 核心业务 是 实现连接
*
* 应该从左表找某个id,然后从右表找该id, 如果都找到,证明该id能链接
*/
public static class UserRateMapJoinMR_Mapper extends Mapper<LongWritable, Text, Text, NullWritable>{
// 存在于内存中的,用来装 users.dat的一个容器
private Map<String, String> userMap = new HashMap<>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
Path[] localCacheFiles = context.getLocalCacheFiles();
Path userFile = localCacheFiles[0];
String userFileStrPath = userFile.toUri().toString();
BufferedReader br = new BufferedReader(new FileReader(new File(userFileStrPath)));
String line = null;
while((line = br.readLine()) != null){
// line ===== 10::F::35::1::95370
String[] split = line.toString().split("::");
String mapKey = split[0];
String mapValue = split[1] + "::" + split[2] + "::" + split[3] + "::" + split[4];
userMap.put(mapKey, mapValue);
}
br.close();
}
Text outKey = new Text();
/**
* value是来自于ratings.dat文件中的一行数据
*
* map方法每调用一次,就意味着从ratings.dat中拿到了一行数据。 如果不及时做链接,下一次map方法再调用时。上一个value就已经丢失
*
* map方法每次运行时,就应该吧拿到的一行数据 和 小表 users.dat 做链接操作
*
* value的格式: 1::595::5::978824268
*/
// @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("::");
// 这是能链接的key
String outKeyStr = split[0];
// 这是能链接的大表中的value
String leftValue = split[1] + "::" + split[2] + "::" + split[3];
// 最终的结果由三部分组成: key, leftValue, rightValue
if(userMap.containsKey(outKeyStr)){
String rightValue = userMap.get(outKeyStr);
String lastValue = outKeyStr + "::" + leftValue + "::" + rightValue;
outKey.set(lastValue);
context.write(outKey, NullWritable.get());
}else{
// 是连不上的情况,所以在内连接场景中, 不用做任何处理
}
}
}
}
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.MRJobConfig;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
*
* 描述:CombineTextInputFormat组件是系统提供的一个用来合并小文件的输入读取组件,也是按行读取。需要设置最大合并后的InputSplit大小
CombineFileInputFormat抽象类的一个实现类CombineTextInputFormat的测试类
*/
public class CombineTextInputFormatTest extends Configured implements Tool {
private static final Log LOG = LogFactory.getLog(CombineTextInputFormat.class);
private static final long ONE_MB = 1024 * 1024L;
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new CombineTextInputFormatTest(), args);
System.exit(exitCode);
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration(getConf());
// 用来设置每一个InputSplit的最大大小为: 256Byte
conf.setLong("mapreduce.input.fileinputformat.split.maxsize", 256);
conf.addResource("hadoop_ha_config/core-site.xml");
conf.addResource("hadoop_ha_config/hdfs-site.xml");
System.setProperty("HADOOP_USER_NAME", "hadoop");
Job job = Job.getInstance(conf);
job.setJarByClass(CombineTextInputFormatTest.class);
// 设置输入输出组件
job.setInputFormatClass(CombineTextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapperClass(TextFileMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// FileInputFormat.setInputPaths(job, args[0]);
// FileOutputFormat.setOutputPath(job, new Path(args[1]));
FileInputFormat.setInputPaths(job, new Path("/smallfiles/input/"));
FileOutputFormat.setOutputPath(job, new Path("/smallfiles/output_2"));
return job.waitForCompletion(true) ? 0 : 1;
}
private static class TextFileMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Configuration configuration = context.getConfiguration();
LOG.warn("#######################" + configuration.get(MRJobConfig.MAP_INPUT_FILE));
Text filenameKey = new Text(configuration.get(MRJobConfig.MAP_INPUT_FILE));
context.write(filenameKey, value);
}
}
}
package com.ghgj.mazh.pojo;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
/**
* MR读数据库的案例:
* 描述: 此类的作用就是用来自定义封装从数据库读取到的一条记录成为一个对应的java对象
* 提供了序列化和反序列化方法
* 提供了sql语句的设置参数方法 和 结果集检索的对象封装方法
*/
public class Student implements WritableComparable<Student>, DBWritable{
private int id;
private String name;
private String sex;
private int age;
private String department;
public Student(int id, String name, String sex, int age, String department) {
super();
this.id = id;
this.name = name;
this.sex = sex;
this.age = age;
this.department = department;
}
public Student() {
super();
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
@Override
public String toString() {
return id + "\t" + name + "\t" + sex + "\t" + age + "\t" + department;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(name);
out.writeUTF(sex);
out.writeInt(age);
out.writeUTF(department);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = in.readUTF();
this.sex = in.readUTF();
this.age = in.readInt();
this.department = in.readUTF();
}
/**
* 排序规则。同时 也是分组规则
*/
@Override
public int compareTo(Student o) {
return this.id - o.getId();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setInt(1, id);
statement.setString(2, name);
statement.setString(3, sex);
statement.setInt(4, age);
statement.setString(5, department);
// statement.setString(1, name);
// statement.setString(2, sex);
// statement.setInt(3, age);
// statement.setString(4, department);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getInt(1);
this.name = resultSet.getString(2);
this.sex = resultSet.getString(3);
this.age = resultSet.getInt(4);
this.department = resultSet.getString(5);
// this.name = resultSet.getString(1);
// this.sex = resultSet.getString(2);
// this.age = resultSet.getInt(3);
// this.department = resultSet.getString(4);
}
}
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.ghgj.mazh.pojo.Student;
/**
*
* 描述: 从数据库中读取数据到HDFS
*/
public class MyDBInputFormatMR {
private static final String driverClass = "com.mysql.jdbc.Driver";
private static final String dbUrl = "jdbc:mysql://hadoop02:3306/jdbc_test?characterEncoding=utf-8";
private static final String username = "root";
private static final String password = "root";
public static void main(String[] args) throws Exception {
// 在本地环境中 运行
Configuration conf = new Configuration();
// 在获取job对象之前,一定要先指定数据库的链接信息
DBConfiguration.configureDB(conf, driverClass, dbUrl, username, password);
Job job = Job.getInstance(conf);
// 不带任何条件, 查询所有字段
// String[] fieldNames = new String[] { "id", "name", "sex", "age", "department" };
// DBInputFormat.setInput(job, Student.class, "student", null, "id", fieldNames);
// 不带任何条件,查询部分字段, 注意:一定要更改Student.class的sql相关方法。sql设置的字段类型一定要和下面的查询字段参数匹配
// String[] fieldNamesPart = new String[] { "id", "name", "sex" };
// DBInputFormat.setInput(job, Student.class, "student", null, "id", fieldNamesPart);
// 带条件,查询所有字段值
// String[] fieldNames = new String[] { "id", "name", "sex", "age", "department" };
// DBInputFormat.setInput(job, Student.class, "student", "department = \"CS\"", "id", fieldNames);
// 自定义SQL语句,注意字段名要和student类的成员名和顺序一样,字段不一样需要用as 别名
String inputQuery = "select id, name, sex, age, department from student where age > 18";
String inputCountQuery = "select count(*) from student where age > 18";
DBInputFormat.setInput(job, Student.class, inputQuery, inputCountQuery);
job.setJarByClass(MyDBInputFormatMR.class);
job.setMapperClass(MyDBInputFormatMRMapper.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Student.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(DBInputFormat.class);
String path = "D:\\bigdata\\dbtest\\db_output";
FileSystem fs = FileSystem.get(conf);
Path p = new Path(path);
if (fs.exists(p)) {
fs.delete(p, true);
System.out.println("输出路径存在,已删除!");
}
FileOutputFormat.setOutputPath(job, p);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class MyDBInputFormatMRMapper extends Mapper<LongWritable, Student, NullWritable, Student> {
@Override
protected void map(LongWritable key, Student value, Context context) throws IOException, InterruptedException {
context.write(NullWritable.get(), value);
}
}
}--------------------------MR写入数据库---------------------------
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
/**
* 描述: 此类的作用就是用来自定义封装从数据库读取到的一条记录成为一个对应的java对象
* 提供了序列化和反序列化方法
* 提供了sql语句的设置参数方法 和 结果集检索的对象封装方法
*/
public class Student implements WritableComparable<Student>, DBWritable{
private int id;
private String name;
private String sex;
private int age;
private String department;
public Student(int id, String name, String sex, int age, String department) {
super();
this.id = id;
this.name = name;
this.sex = sex;
this.age = age;
this.department = department;
}
public Student() {
super();
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
@Override
public String toString() {
return id + "\t" + name + "\t" + sex + "\t" + age + "\t" + department;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(id);
out.writeUTF(name);
out.writeUTF(sex);
out.writeInt(age);
out.writeUTF(department);
}
@Override
public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = in.readUTF();
this.sex = in.readUTF();
this.age = in.readInt();
this.department = in.readUTF();
}
/**
* 排序规则。同时 也是分组规则
*/
@Override
public int compareTo(Student o) {
return this.id - o.getId();
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setInt(1, id);
statement.setString(2, name);
statement.setString(3, sex);
statement.setInt(4, age);
statement.setString(5, department);
// statement.setString(1, name);
// statement.setString(2, sex);
// statement.setInt(3, age);
// statement.setString(4, department);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.id = resultSet.getInt(1);
this.name = resultSet.getString(2);
this.sex = resultSet.getString(3);
this.age = resultSet.getInt(4);
this.department = resultSet.getString(5);
// this.name = resultSet.getString(1);
// this.sex = resultSet.getString(2);
// this.age = resultSet.getInt(3);
// this.department = resultSet.getString(4);
}
}import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import com.ghgj.mazh.pojo.Student;
/**
*
* 描述: 读取文件的数据往 mysql数据库表中写出
*/
public class MyDBOutputFormatMR {
private static final String driverClass = "com.mysql.jdbc.Driver";
private static final String dbUrl = "jdbc:mysql://hadoop02:3306/jdbc_test?characterEncoding=utf-8";
private static final String username = "root";
private static final String password = "root";
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set(DBConfiguration.DRIVER_CLASS_PROPERTY, driverClass);
// conf.set(DBConfiguration.URL_PROPERTY, dbUrl);
// conf.set(DBConfiguration.USERNAME_PROPERTY, username);
// conf.set(DBConfiguration.PASSWORD_PROPERTY, password);
DBConfiguration.configureDB(conf, driverClass, dbUrl, username, password);
Job job = Job.getInstance(conf);
job.setJarByClass(MyDBOutputFormatMR.class);
job.setMapperClass(MyDBOutputFormatMR_Mapper.class);
job.setMapOutputKeyClass(Student.class);
job.setMapOutputValueClass(NullWritable.class);
// job.setReducerClass(MyDBOutputFormatMR_Redcuer.class);
// job.setMapOutputKeyClass(Student.class);
// job.setMapOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TextInputFormat.class);
/**
* 指定数据输出目的地:那张表
*/
job.setOutputFormatClass(DBOutputFormat.class);
// 此处给 出的 字段名称约束 一定要和 Student 类中 描述读进或者写出的字段名称个数一直
DBOutputFormat.setOutput(job, "student_copy", new String[]{"id","name","sex","age","department"});
Path inputPath = new Path("D:\\bigdata\\dbtest\\db_input");
FileInputFormat.setInputPaths(job, inputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class MyDBOutputFormatMR_Mapper extends Mapper<LongWritable, Text, Student, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
Student student = new Student();
student.setId(Integer.parseInt(split[0]));
student.setName(split[1]);
student.setSex(split[2]);
student.setAge(Integer.parseInt(split[3]));
student.setDepartment(split[4]);
context.write(student, NullWritable.get());
}
}
static class MyDBOutputFormatMR_Redcuer extends Reducer<Student, NullWritable, Student, NullWritable> {
@Override
protected void reduce(Student key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for(NullWritable nvl : values){
context.write(key, NullWritable.get());
}
}
}
}














 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









