






这些东西可以讲很深,但今天只会带大家看些简单的LLVM IR跟 组合语言,并且举一些例子来讲 编译器”优化” 在做些什么。今天的示例会以Rust 为主,因为Rust 编译器的核心是建立在LLVM 之上,所以也支持编译成LLVM IR。虽然如此,就算你完全不了解LLVM 跟Rust 也还是可以读,因为今天会从LLVM 是啥开始讲,而且用到的Rust 语法也超超简单。
LLVM
LLVM 的命名源自于Low Level Virtual Machine 的缩写,但随着专案发展,现在的LLVM 跟虚拟机已经没太大的关系,而是变成一系列编译器工具链的组合,其中也包含今天的LLVM IR 跟各种IR Optimizer
LLVM IR
LLVM IR(Intermediate Representation) 直翻是「中间表达式」,说白话点他就是一种比较低阶的程式语言(大概介于C 跟组合语言之间)。一个简单的add function 用LLVM IR 写起来就像这样,语法稍微啰嗦了点,但还算好读(分号后面是我的注解)

从这范例可以看出LLVM IR 有个特点,就是IR 会把每个步骤切得很细,而且也没有任何语法糖。像我们平常会直接写return x + y,但因为在LLVM IR 中相加跟return 是两个步骤,所以一定要写成两行。
Rust 的编译过程
接着来说说Rust 是怎么编译的:因为Rust 是高阶语言,要直接编译成最低阶的Assembly 并不容易,所以Rust 编译会分成两个阶段,首先是「把原始码编译成IR」,接着才是「从IR 产生Assembly」
把原始码编译成LLVM IR
下了指令 cargo build --release 之后,Rust 编译器会把代码,经过第一阶段编译,生成比较低阶的LLVM IR

此外,Rust 也会在这个阶段进行第一次 优化,像上图原始码中的 let (x, y) = (10, 20) 其实是不需要的,直接呼叫 let z = add(10, 20) 就可以了,所以编译器就会生出%z = call i32 @add(i32 10, i32 20)
从LLVM IR 产生Assembly
有了第一阶段产生的LLVM IR,编译器接着会把IR 转成更低阶的组合语言。在组合语言(汇编)中,除了一个指令只能一个动作之外,就连变量、函式要放在什么位址都必须清楚的写出来,所以会比IR 更啰唆一些
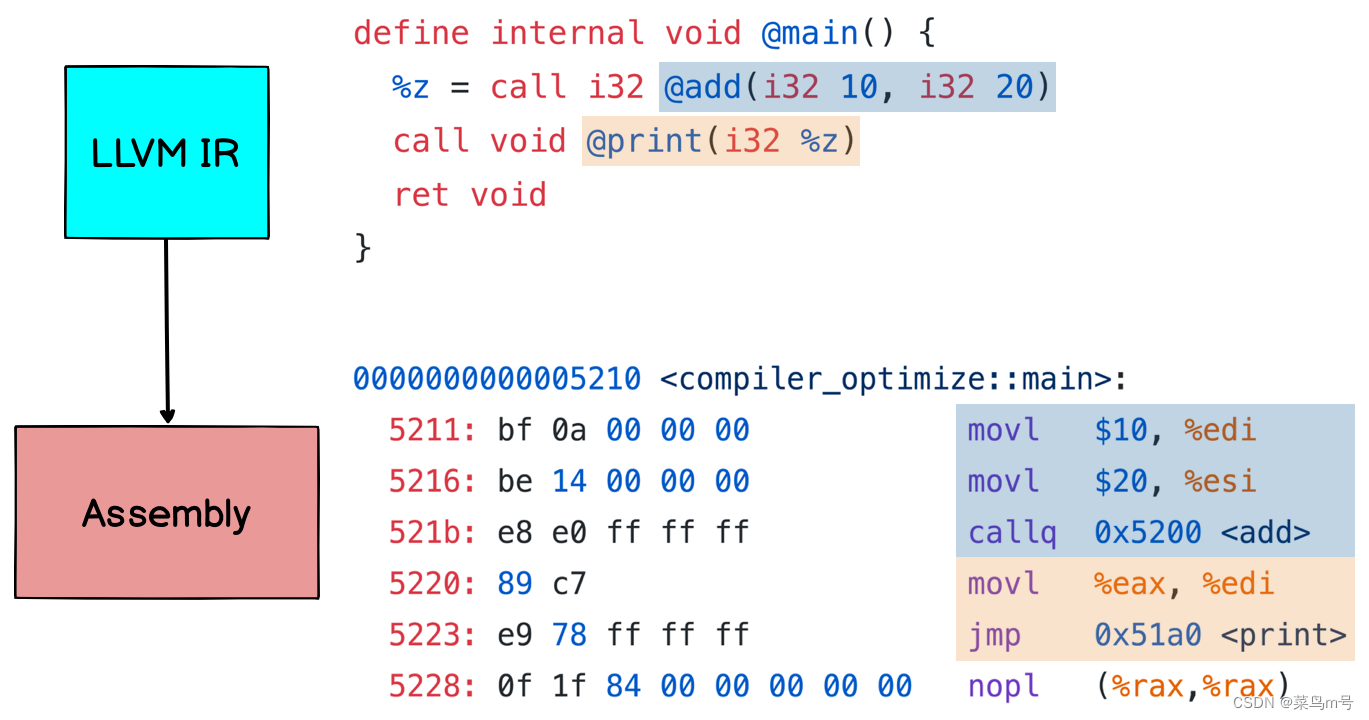
像上图中数字10 跟20 就是放在 EDI 跟 ESI 两个register 里面,add 跟print 两个函式则是在 0x5200 及0x51a0
编译器”优化”在做些什么?
对LLVM IR 有初步的了解后,接着就要进入今天的主题:介绍几种常见的编译器”优化”方法
所谓的”优化”就是在不影响结果的前提下,尽量减少所需的资源(运算时间、变量空间等等),像先前提到的删掉不需要的 let (x, y) = (10, 20) 就是一例
1. Constant Folding
平常写程式时,程式码中多少会有一些常数运算,而Constant Folding 就是在编译期间先把常数算好。
像下图的 const_fold 就是固定回传20 * 50 + 80,这时如果是用开发模式编译的话,编译器就会照你写的程式码产生IR:先是把 20 * 50 存到变量%1,接着再算出b = %1 + 10。整个过程需要 两个变量 以及 两次运算

但 20 * 50 + 80 开源直接算出来啊,有必要每次呼叫function 都算一次吗?所以如果用release 模式编译的话,生出来的IR 就会直接回传1080,这就是Constant Folding

以上是整数运算的情况,若像下面小数的例子,常数值 5.8/π² 算出来大约是0.5876628651255591。那编译器也会帮你算好,并且转成IEEE 754 浮点数格式 存在内存里面,程式执行时就会直接拿来用

有了Constant Folding 后,程式中的常数运算写得多复杂都没差,反正编译器会预先帮你算出来,程式执行时也不用再另外花时间。
2. Constant Propagation
单纯的Constant Folding 大家可能觉得没什么,但接着要讲的Constant Propagation 真的很猛,他会把常数一直往下推到后续的程式码,并且尽可能地简化判断式
光用讲的有点抽象,直接看例子吧!
这边的例子 f(x: i32) 是一个函数,他接受一个整数x,经过一连串运算后输出另一个整数。值得一提的是这函数里面有用到 循环 还有if,所以分析起来会比较复杂
经过编译器的”优化”(因为b 跟c 都是常数可以一直往下推),最后左边那一大串程式码会变成右边的IR

不对啊这IR 也太短了吧!而且读一下会发现他不就是在算 222x + 282 吗?你说这会跟原本那么长的f(x) 一样?
没错,编译器的意思就是:「不管你输入的x 是多少,f(x)的值一定就是222x + 282」,虽然看起来有点神奇,但反正我是信了
仔细分析一下,原本的程式码需要很多变量空间还有一大堆运算(毕竟还有循环),但”优化”后变成只需要 三个变量,进行 一次乘法、一次加法,整个过程可能快了十倍有吧
3. Multiplication and Division Optimization
大家应该多少听过,因为电脑在储存整数时是采用二进制,所以 乘2 跟除2 可以用左移跟右移一格 来取代,而且shift 对CPU 来讲很简单,所以做起来会比乘法快很多
看下图,因为左边例子中的8 是2³,而16 是2⁴,所以 x * 8 会被”优化”成x << 3,而 x / 16 则是变成x >> 4

但想也知道哪有运气那么好的,每次乘数跟除数的都是2 的次方。如果遇到乘30,或是除以3 这类的整数该怎么办呢?
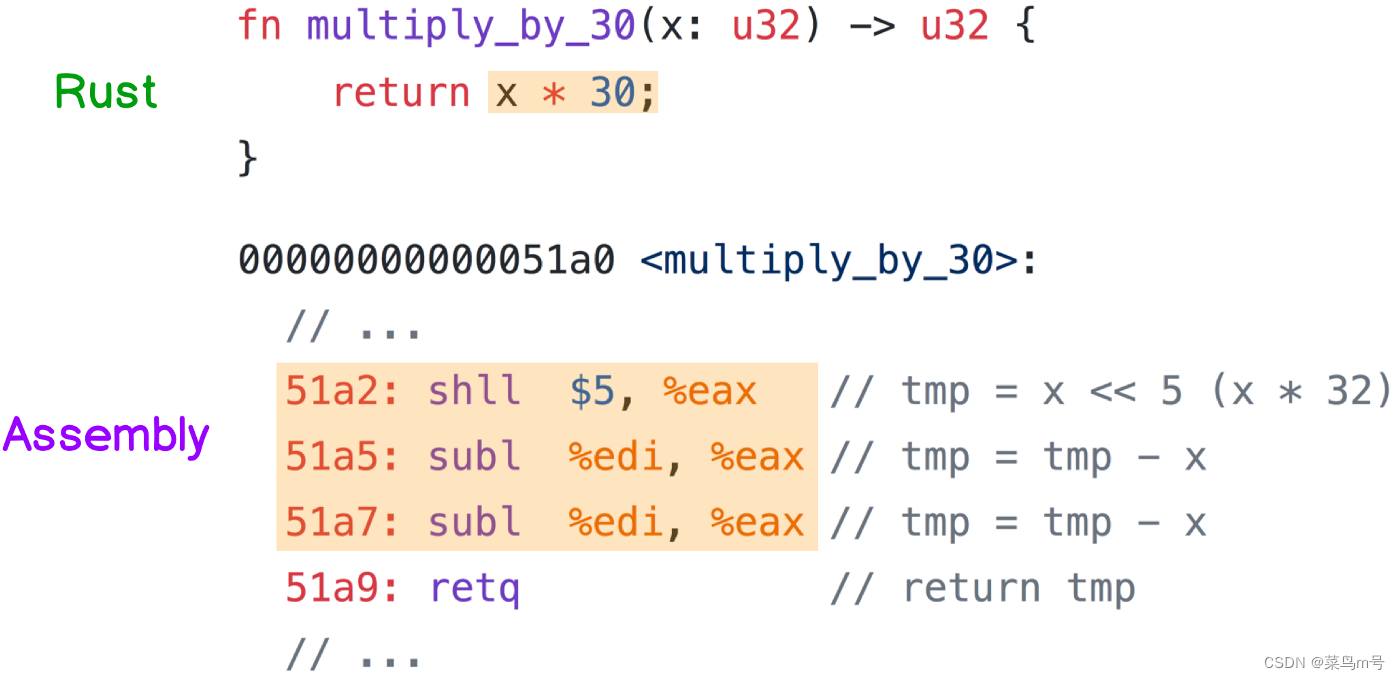
像乘30 这种情况,因为30 离32(=2⁵) 很近,所以编译器会把 x * 30 改成(x << 5) — x — x(下图的组语),虽然步骤多了点,但因为 左移 跟 减法 的速度都很快,所以还是比直接乘30 来得快
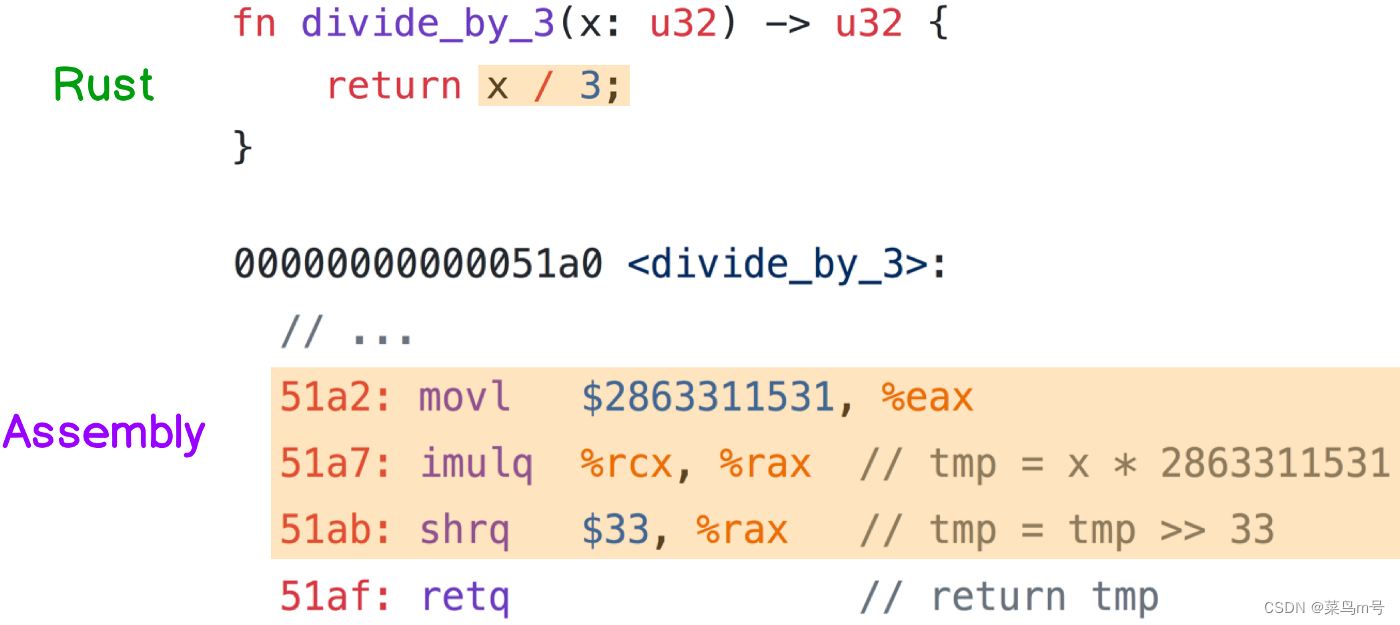
除以3 的话,因为 除法比乘法慢非常非常多,所以编译器会把 x / 3 改成(x * 2863311531) >> 33(下图的组语)
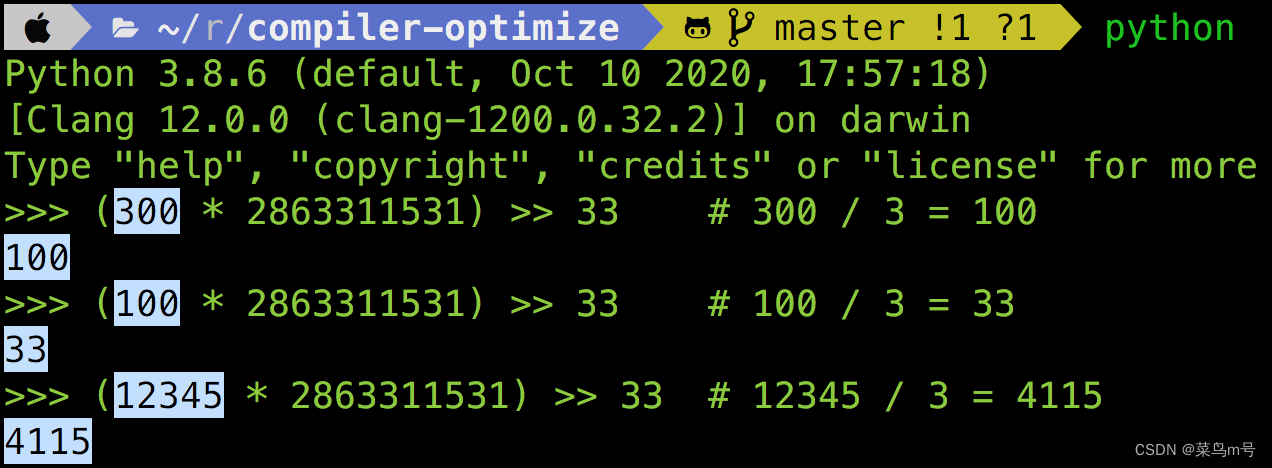
我知道一定会有人觉得2863311531 这数字是什么鬼,怎么可能这样算一算刚好就是x / 3,所以下图我用Python 试了几个数字,给大家看看 (x * 2863311531) >> 33 确实等于x / 3
其实不光是3,任何整数除法 都可以被转换成 乘法再右移,不过怎么转的有点复杂,总之交给编译器就是了~
4. Function Inlining
平常coding 时,一般会将各个功能独立成一个个function。但对CPU 来说,每次呼叫function 都需要额外的开销(复制参数、建立Stack 等等),所以若是function 的内容不长,就会直接被编译器展开
以下面的例子来说,左边Rust 的 sub(x, y) 是借着 add(x, -y) 做到的,所以从生出来的IR 也可以看出 sub(x, y) 中确实呼叫了add(x, 0-y)

但经过”优化”后,因为 add 的内容太短,所以编译器会直接把 add 展开成一个加号,于是 sub 的内容就变成x + (-y),再简化一下就x — y

从这例子可以知道,虽然在 sub 里面呼叫 add 表面上会花比较多时间,但因为编译器很聪明,所以”优化”后完全不影响效能,只要可读性ok 的话这样写也没什么不好
5. Strength reduction
接下来四个都是有关循环的优化,毕竟写程式不能没有循环,如果哪个语言没有循环,那我还真的不知道他能做什么XD
而这边的Strength reduction 说白话点就是 把循环中的运算强度降低,譬如说乘法变成加法、除法变成乘法,虽然每一圈的速度可能只会提升一点点,但因为循环都会执行很多次,累积起来的效能提升也是不少
像下面这个 loop_print 总共会跑一百次print(i * 500)(看不习惯Rust 可以看右边的JS,两边是等价的),也就是说,CPU 跑完整个循环总共需要做100 次i * 500,也就是100 次乘法

但因为CPU 做加法比做乘法快,所以编译器会把这段程式码编译成下图左边的LLVM IR,翻译成JS 的话就长成右边那样。

比较一下优化前后的JS,会发现优化之后(下图右边)就没有 i * 500 了,取而代之的是每圈结束后都要执行的i = i + 500,那这样真的会跟原本的循环一样吗?

大家可以自己在脑袋里跑跑看,就会发现两边都是先执行print(0),接着就是print(500)、print(1000)一直到最后的print(49500),所以他们真的是一样的。
6. Canonicalize Induction Variables
除了上面提到可以加快每一圈的速度之外,编译器也会进行一些推理帮你 简化判断条件
譬如下面这个例子(左边Rust、右边JS,看你习惯看哪边),x 会从0 开始往上加,如果x 满足x * x < 10000,那就会继续执行print(x),否则就跳出循环

聪明的你应该马上就会想到 x * x < 10000 不就是 x < 100 吗?
是的,所以编译器产生出来的IR 也是只判断x < 100,这样就可以少做好几次乘法啦

如果把上面的IR 翻成JS,那就长得像下图右边那样,循环跑一百次的话,跟原本的JS 比起来就省了一百次的乘法运算,超棒的

7. Loop Unrolling
Loop Unrolling 是一种牺牲程式大小以换取效率的一种”优化”方式,简单来说就是把loop 展开
下面这个例子是从 print(0) 跑到print(99),非常简单。但如果程式照着循环跑的话,就要一直重复做 i++ 跟确认 i < 100 有没有满足,累积起来也是要花不少时间

所以如果次数不多的话,编译器就会直接帮你把循环展开,你要一百次,我就给你一百次!最后生出来的IR 就长这样

Loop Unrolling 除了可以省去 i++ 跟判断 i < 100 的时间之外,也可以降低CPU 在branch prediction出错的次数。虽然把程式码都展开会让编译出来的执行档很肥大,但反正储存空间很便宜,程式跑起来的效能才是重点
8. Sum-Product Optimization
最后一个Sum-Product 是我觉得最厉害的”优化”技术之一,平常在写 1 + 2 + 3 + ... + x 时,我们可能会这样写(左右边等价)

这样写起来简单,读起来也满直观的。但有个缺点,就是假如x 是1000,那CPU 为了要把sum 算出来就要做1000 次加法,更不用说x 值更大的情况了
为了减少这种 有规律性的大量运算,编译器会自动进行公式推导,像 sum_to_x 经过编译后会变成return x(x-1)/2 + x,再稍微简化一下就会变成小学教的梯形面积公式x(x+1)/2
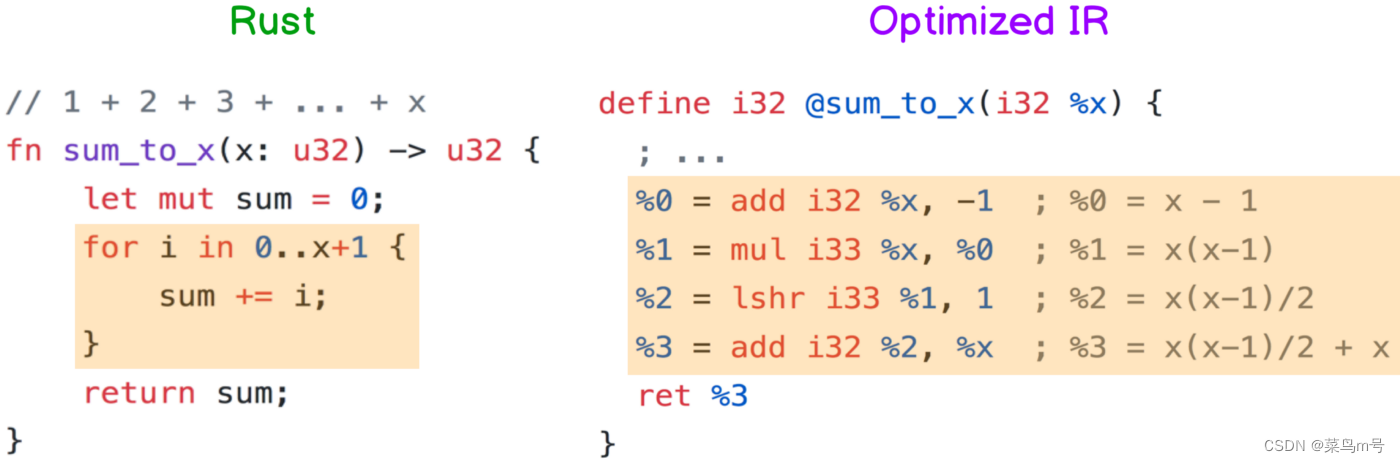
虽然编译器推导出的 sum_to_x(x) = x(x-1)/2 + x 还有进步空间,但比起用循环整个跑过一遍,x(x+1)/2 + x只需要2 个加法、1 个右移跟1 个乘法,而且不管x 多大都是如此,(x 够大的话甚至可以省下数万次加法运算),所以已经进步超多了
除了 sum_to_x 这种等差数列之外,其他只要有规律性的运算也都可以,像下面这个 square_sum_to_x 就是做1²+2²+3²+…+x²,虽然他推导出来的IR 也比较长(我懒得简化他了),但可以确定的是里面只会用到加法、乘法跟右移,而且跟 sum_to_x 一样不会因为x 变大而增加运算量

我觉得这个”优化”很厉害的原因是:我甚至不用告诉编译器我的数列有什么规律,他就会自己想办法导出一个公式来,虽然这个公式还有进步空间,但编译器已经把时间复杂度从O(n) 降到O(1),这代表以后写循环不用再担心因为x 很大而跑很久,只要放心写就可以了
总结
看到这边,我想大家都对编译器”优化”有些认识了,若大家有兴趣我以后再补充一些更进阶的。
另外,虽然这篇文章是以Rust 跟LLVM 为主,但编译器”优化”并非LLVM Compiler 的专利,现在各个语言只要发展够成熟了一定都会有类似的机制,所以即便不是LLVM based 的编译器也能享有这些”优化”技术
直译式语言方面,现在的Python、NodeJS runtime 也都有所谓的JIT(Just In Time) Compilation 了,JIT 会在程式执行的期间进行即时”优化”,虽然速度可能还是比不上编译式语言,但比起以前也是很大的进步了。
更多内容开可以关注博主公众号内容:
”TIPFactory情报工厂“
或进入知识星球,获取更多红蓝对抗,逆向,APT情报技术等:
















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









