







目录
一、studentJobData_year2022.json
四、drop_duplicates()函数去重&count()函数确认是否有缺失值
一、studentJobData_year2022.json
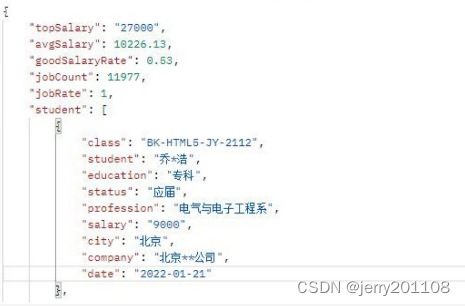
json文件下载链接: https://pan.baidu.com/s/1g08SIL2CkkEbLedEF8uJlw 提取码: aju5
二、将student主体信息提取出来
import pandas as pd
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
print(student)
print(type(student))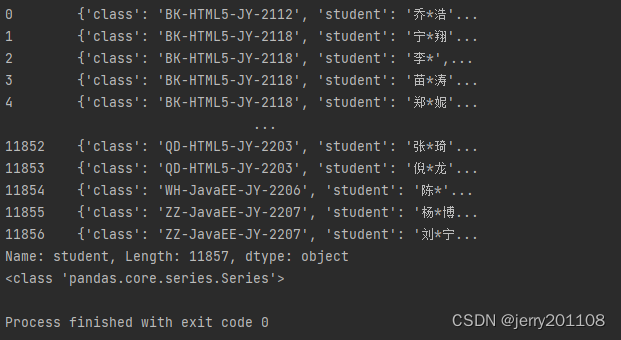
三、将数据重新整合成DataFrame类型
import pandas as pd
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
print(data)
print(type(data))
四、drop_duplicates()函数去重&count()函数确认是否有缺失值
import pandas as pd
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
print(data.count())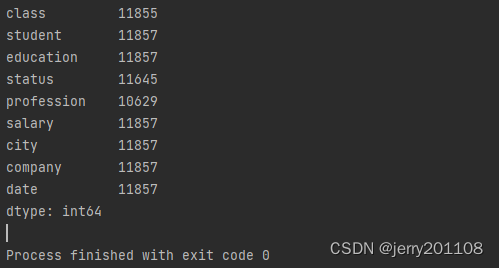
可见,每列的数据总量并不相等,所以存在缺失值
五、isnull().sum()函数统计缺失值
import pandas as pd
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
print(data.isnull().sum())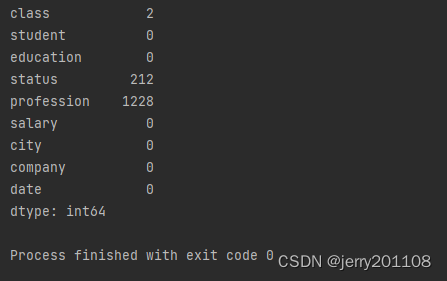
六、fillna()函数填充缺失值
import pandas as pd
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
# print(data.isnull().sum())
# 填充缺失值
data["class"]=data["class"].fillna(value="2112")
data["profession"]=data["profession"].fillna(value="非计算机专业")
data["status"]=data["status"].fillna(value="待业")
print(data.isnull().sum())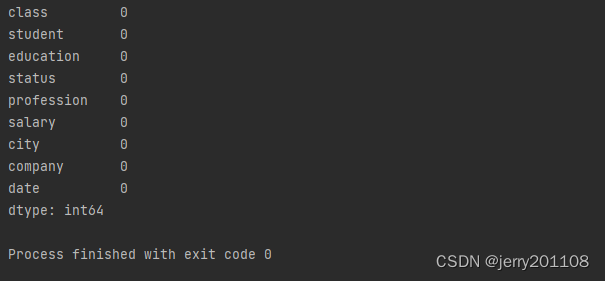
七、就业城市分布分析【单列数据分析】
import pandas as pd
from collections import Counter
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
# print(data.isnull().sum())
data["class"]=data["class"].fillna(value="2112")
data["profession"]=data["profession"].fillna(value="非计算机专业")
data["status"]=data["status"].fillna(value="待业")
# print(data.isnull().sum())
# 获取城市列表
city_list=set(data["city"])
print(city_list,"\n")
# 使用Counter直接统计每个城市的数量
data_city=Counter(data["city"])
print(data_city,"\n")
# 转换为元组列表,每个元组包含城市名和其对应的计数
data_city = [(city, count) for city, count in data_city.items()]
print(data_city,"\n")
# 按照计数进行排序
data_city_sorted = sorted(data_city, key=lambda x: x[1], reverse=True)
print(data_city_sorted)
八、就业曲线分析【单列数据分析】
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
# print(data.isnull().sum())
data["class"]=data["class"].fillna(value="2112")
data["profession"]=data["profession"].fillna(value="非计算机专业")
data["status"]=data["status"].fillna(value="待业")
# print(data.isnull().sum())
print(len(data["date"]),'\n')
# 获取日期列表
date_getjob = list(data["date"])
# 使用列表推导式截取每个日期的前7个字符,即"年-月",并排序
date_getjob_1 = sorted([date[:7] for date in date_getjob])
# 统计各个日期的次数
date_counts =Counter(date_getjob_1)
print(date_counts,'\n')
dates=[]
counts=[]
for date,count in date_counts.items():
dates.append(date)
counts.append(count)
print(dates,'\n')
print(counts)
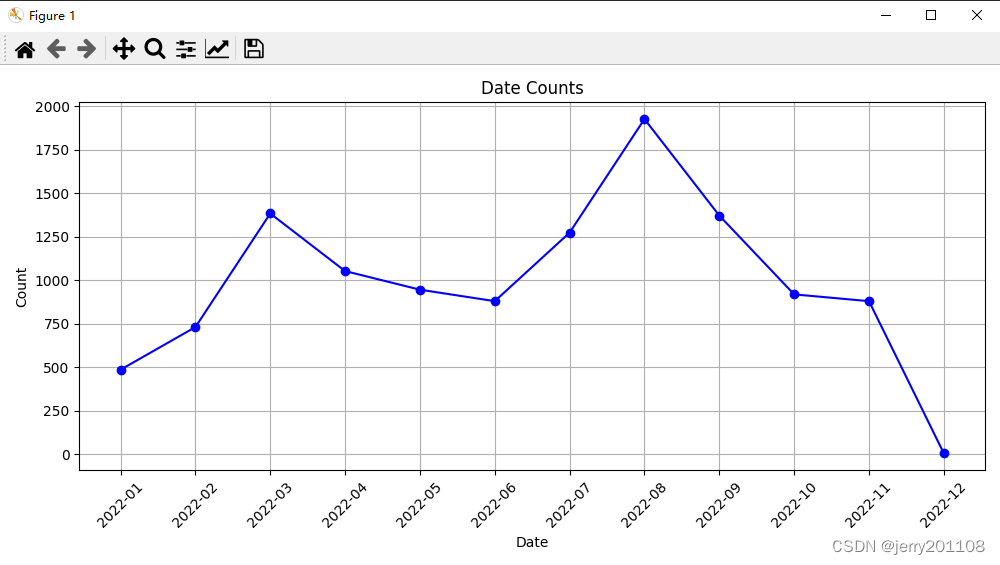
# 使用Matplotlib绘制折线图
plt.figure(figsize=(10, 5)) # 设置图形大小
plt.plot(dates, counts, marker='o', linestyle='-', color='b') # 绘制折线图
plt.title('Date Counts') # 设置图表标题
plt.xlabel('Date') # 设置x轴标签
plt.ylabel('Count') # 设置y轴标签
plt.grid(True) # 添加网格
plt.xticks(rotation=45) # 旋转x轴标签,以便更好地显示
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show() # 显示图表
九、就业状态饼图【单列数据分析】
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
# print(data.isnull().sum())
data["class"]=data["class"].fillna(value="2112")
data["profession"]=data["profession"].fillna(value="非计算机专业")
data["status"]=data["status"].fillna(value="待业")
# print(data.isnull().sum())
print(len(data["date"]),'\n')
# 获取就业状态
data_states = list(data["status"])
print(data_states)
# 统计各个日期的次数
states_counts =Counter(data_states)
print(states_counts,'\n')
states=[]
counts=[]
for state,count in states_counts.items():
states.append(state)
counts.append(count)
print(states,'\n')
print(counts)
# 设置支持中文的字体,这里使用SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图表时负号'-'显示为方块的问题
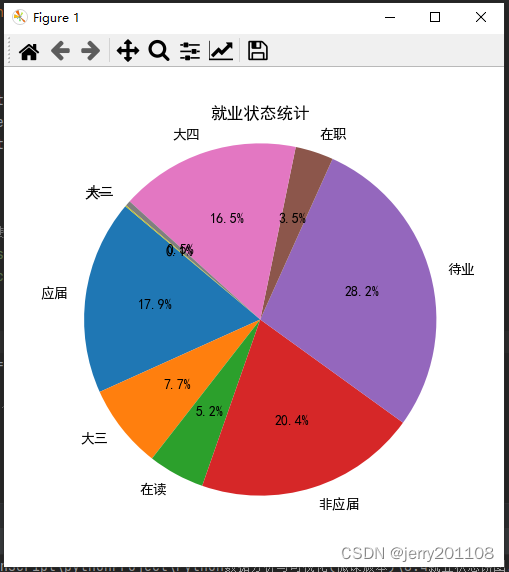
# 使用Matplotlib绘制饼图
plt.figure(figsize=(5, 5)) # 设置图形大小
plt.pie(counts, labels=states, autopct='%1.1f%%', startangle=140) # 绘制饼图
plt.title('就业状态统计') # 设置图表标题
plt.axis('equal') # 确保饼图是圆形的
plt.show() # 显示图表
十、薪资与学历关系分析箱线图【双列数据分析】
注意:这次是从整体数据中取出两列进行分析,前面的分析都是从整体数据中取出一列进行分析。
import pandas as pd
from collections import Counter
from matplotlib import pyplot as plt
data=pd.read_json("src/studentJobData_year2022.json")
# 将student主体信息提取出来
student=data["student"]
# 将数据重新整合成DataFrame类型
data=pd.DataFrame([i for i in student])
# 数据去重,删除重复数据
data.drop_duplicates()
# 先整体观察,确认是否有缺失值
# print(data.count())
# 统计缺失值
# print(data.isnull().sum())
data["class"]=data["class"].fillna(value="2112")
data["profession"]=data["profession"].fillna(value="非计算机专业")
data["status"]=data["status"].fillna(value="待业")
# print(data.isnull().sum())
print(len(data["date"]),'\n')
# 获取education列和salary列
educations = data['education'].unique()
print(educations)
salaries = [data[data['education'] == edu]['salary'].dropna().values.astype(int) for edu in educations]
# 设置支持中文的字体,这里使用SimHei(黑体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图表时负号'-'显示为方块的问题
# 创建箱线图
plt.figure(figsize=(10, 8)) # 设置图形大小
plt.boxplot(salaries, labels=educations) # 绘制箱线图
plt.title('不同教育水平的薪资分布箱线图') # 设置图表标题
plt.ylabel('薪资') # 设置y轴标签
plt.show() # 显示图表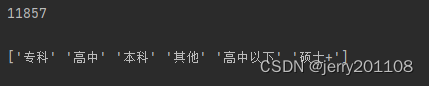

在提取salary时需要注意类型转换为int,否则会报如下的错误,解决方法就是.astype(int)
TypeError: ufunc 'divide' not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ''safe''
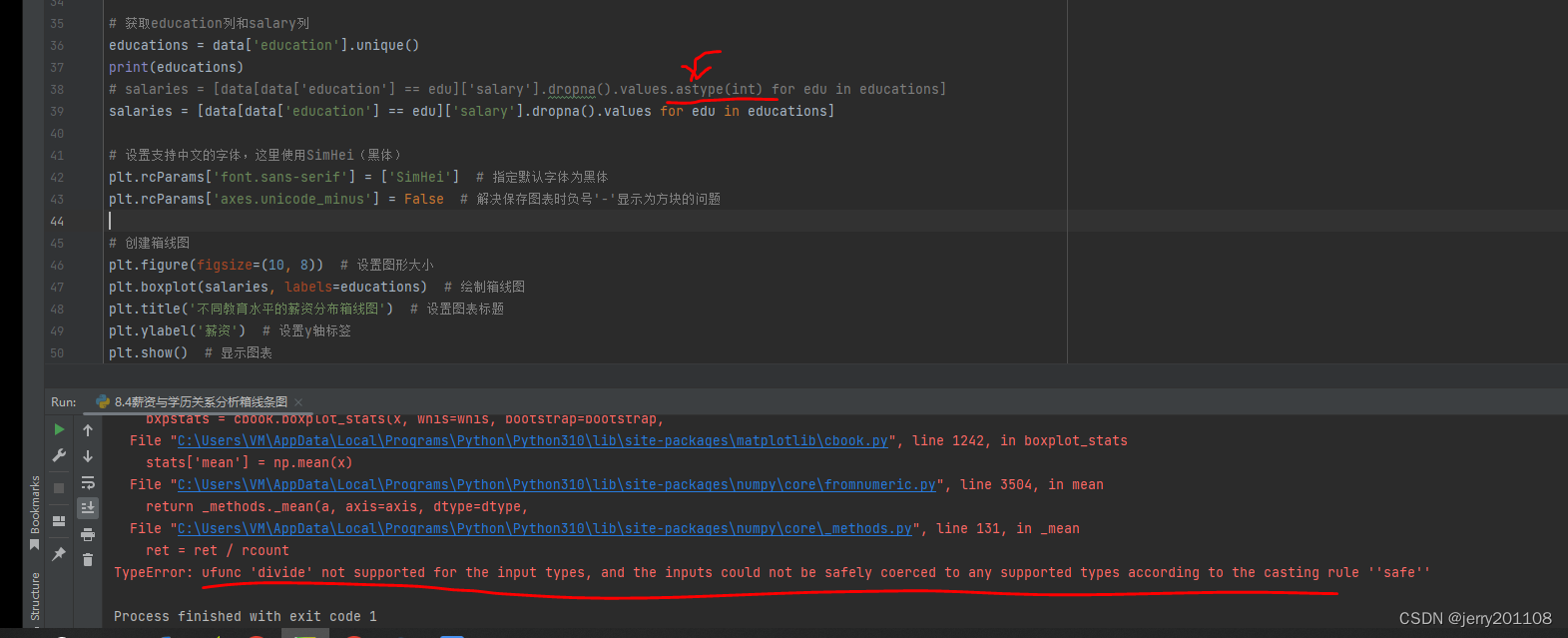
请确保
salary 列中的数据可以安全地转换为整数,否则astype(int) 可能会引发错误。如果salary 列中包含非数字字符串,你可能需要在转换之前进行数据清洗。
----------------------
学习书籍:《Python数据分析与可视化(微课版) 李俊吉 宋祥波 主编 2024-05-01》















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









