文章目录 一、列表 List1.1 重复统计法一法二 1.2 去重法一(利用 not in 与append)法二(利用set,顺序会乱)法三(利用set + sort,顺序不会乱) 二、DataFrame2.1 重复统计2.2 去重法一(unique,只能针对1列)法二(drop_duplicates,可针对多列) 一、列表 List list_ = ['a','b','b','c','d','d'] 1.1 重复统计 法一 dict([[i,list_.count(i)] for i in list_]) 法二 from collections import Counter Counter(list_) 1.2 去重 法一(利用 not in 与append) dup_list = [] for i in list_: if i not in dup_list: dup_list.append(i) 法二(利用set,顺序会乱) list(set(list_)) 法三(利用set + sort,顺序不会乱) dup_list = list(set(list_)) dup_list.sort(key=list_.index) 二、DataFrame df = pd.DataFrame( { 'key1':['a','a','b','b','a','a','b','b'], 'key2':['one','two','one','two','one','one','two','two'], 'key3':[1,2,3,2,1,1,2,3], } ) 2.1 重复统计 找出全部列的重复项 df[df.duplicated()] 只找出某几列相同的重复项 df[df.duplicated(['key1','key2'])] # 只找出key1, key2相同的重复项 找出每行数据重复出现的次数(≥2说明存在重复行) df.value_counts() 统计重复数据总共多少条 df[df.duplicated()].count() 2.2 去重 法一(unique,只能针对1列) df['key1'].unique() 法二(drop_duplicates,可针对多列) df.drop_duplicates( keep = first, # {first:保留第一个,last:保留最后一个} subset = [], # 默认所有列 inplace = False # 是否在原数据上修改,默认为False ) 参考:Python常用的几种去重方式参考:Python统计列表中的重复项出现的次数的方法 参考:pandas统计重复值次数







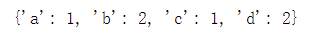
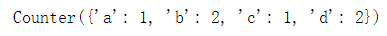















 1426
1426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









