







 这篇博客详细介绍了K-means、K-means++、K-modes和K-prototype四种聚类算法,包括它们的步骤、遇到的问题以及解决方案。此外,还提供了相应的Python代码示例,帮助读者深入理解无监督学习中的这些聚类技术。
这篇博客详细介绍了K-means、K-means++、K-modes和K-prototype四种聚类算法,包括它们的步骤、遇到的问题以及解决方案。此外,还提供了相应的Python代码示例,帮助读者深入理解无监督学习中的这些聚类技术。
K-means
K-means属于聚类算法中最简单的一种,也是一种无监督学习的算法。
步骤:
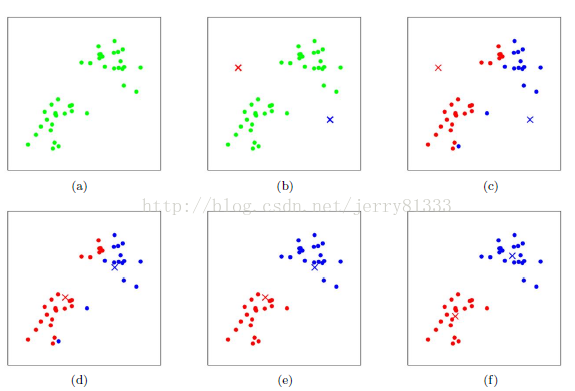
按上图所示,具体步骤如下:
1. 设定初始簇的个数,上图为2
2. 使用欧式距离对簇进行分类,与最近的簇为一类,如上图所示,分为红蓝两类
3. 对已分类的所有数据区均值,取X/Y坐标的平均值,设为新的中心点,如上图c-d的操作
4. 重新对簇进行分类(如步骤2),如上图d-c的操作
5. 迭代直到结束。
结束迭代的方法有很多,比如收敛达到一定程度后结束迭代,如无法收敛可以设置迭代次数
问题:
1. 需要先验知识,必须给定一个簇,簇多簇少效果是截然不同的。
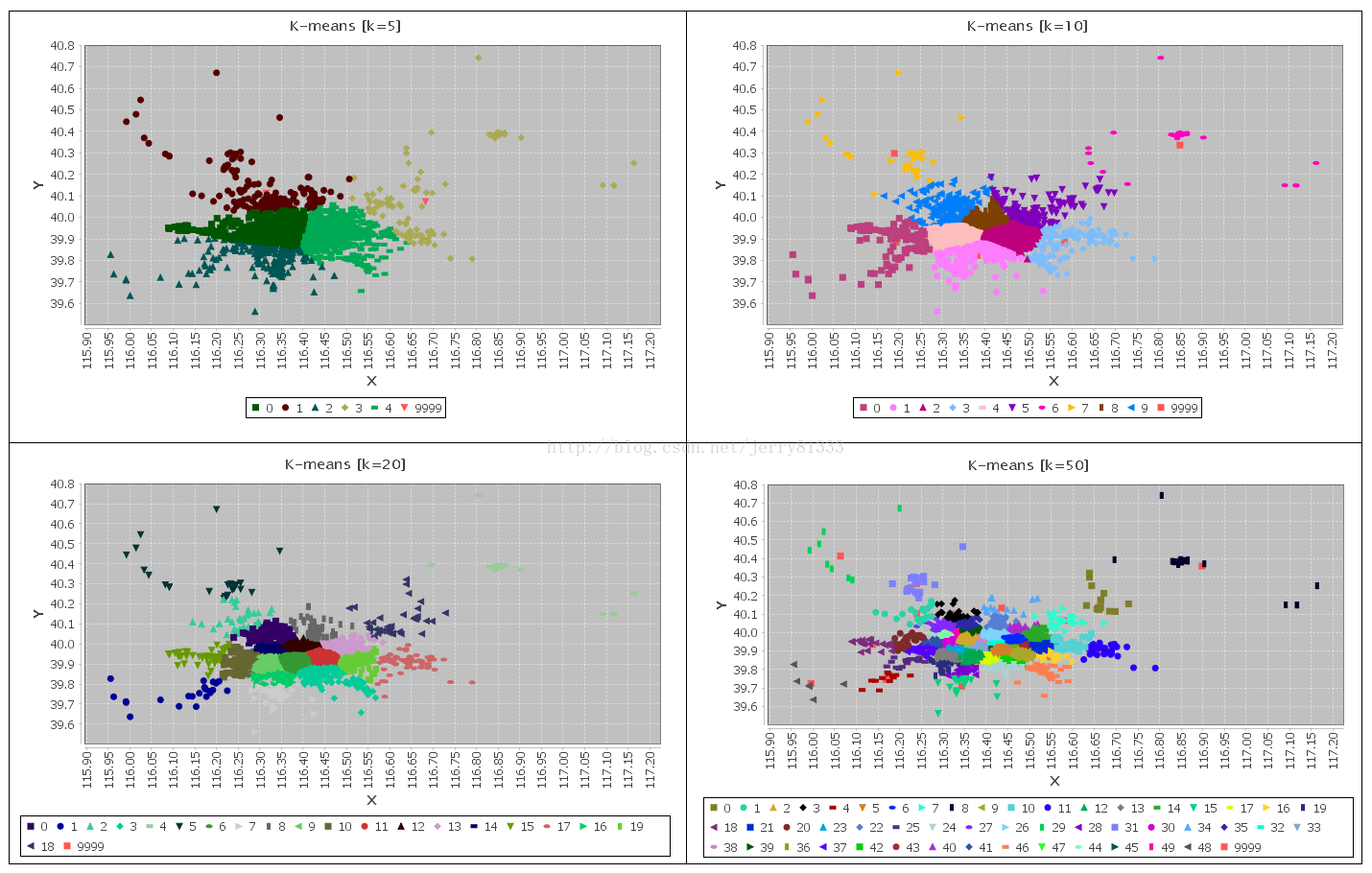
2. 初始簇中心点对算法影响较大,如果初始值不太好,可能对结果产生较大的影响。
3. 去噪点能力差,误差数据可能会对结果造成较大的影响。
4. 仅适用于球心数据分布
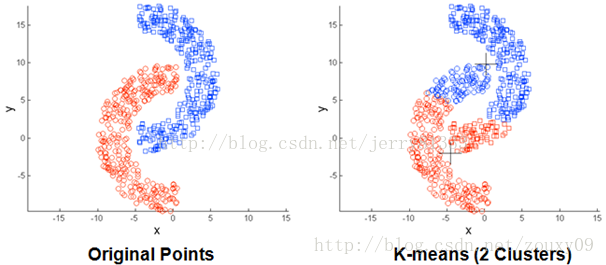
5. 数据比较大时收敛比较慢
解决:
对于中心点的收敛问题,可以使用特殊的求中心点公式:
1. Minkowski Distance 公式 —— λ 可以随意取值,可以是负数,也可以是正数,或是无穷大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









