









 本文介绍了如何使用Python实现K-Prototypes聚类算法,并通过iris数据集进行示例,展示的聚类结果与原始分类高度吻合,验证了算法的有效性。
本文介绍了如何使用Python实现K-Prototypes聚类算法,并通过iris数据集进行示例,展示的聚类结果与原始分类高度吻合,验证了算法的有效性。
点击下方图片查看HappyChart专业绘图软件

k-prototypes聚类
前一篇讲述了K-Prototypes聚类的原理以及它的伪代码,本篇根据上一篇内容编写了实现K-Prototypes的Python代码。
# -*- coding: utf-8 -*-
import numpy as np
import random
from collections import Counter
def dist(x, y):
return np.sqrt(sum((x-y)**2))
def sigma(x, y):
return len(x) - sum(x == y)
def findprotos(data, k):
m, n = data.shape
num = random.sample(range(m), k)
O = []
C = []
for i in range(n):
try:
if isinstance(data[0, i], int) or isinstance(data[0, i], float):
O.append(i)
elif isinstance(data[0, i], str):
C.append(i)
else:
raise ValueError("the %d column of data is not a number or a string column" % i)
except TypeError as e:
print(e)
O_data = data[:, O]
C_data = data[:, C]
O_protos = O_data[num, :]
C_protos = C_data[num, :]
return O, C, O_data, C_data, O_protos, C_protos
def KPrototypes(data, k, max_iters=10, gamma=0):
m, n = data.shape
O, C, O_data, C_data, O_protos, C_protos = findprotos(data, k)
cluster = None
clusterShip = []
clusterCount = {}
sumInCluster = {}
freqInCluster = {}
for i in range(m):
mindistance = float('inf')
for j in range(k):
distance = dist(O_data[i,:], O_protos[j,:]) + \
gamma * sigma(C_data[i,:], C_protos[j,:])
if distance < mindistance:
mindistance = distance
cluster = j
clusterShip.append(cluster)
if clusterCount.get(cluster) == None:
clusterCount[cluster] = 1
else:
clusterCount[cluster] += 1
for j in range(len(O)):
if sumInCluster.get(cluster) == None:
sumInCluster[cluster] = [O_data[i,j]] + [0] * (len(O) - 1)
else:
sumInCluster[cluster][j] += O_data[i,j]
O_protos[cluster,j] = sumInCluster[cluster][j] / clusterCount[cluster]
for j in range(len(C)):
if freqInCluster.get(cluster) == None:
freqInCluster[cluster] = [Counter(C_data[i,j])] + [Counter()] * (len(C) - 1)
else:
freqInCluster[cluster][j] += Counter(C_data[i,j])
C_protos[cluster,j] = freqInCluster[cluster][j].most_common()[0][0]
for t in range(max_iters):
for i in range(m):
mindistance = float('inf')
for j in range(k):
distance = dist(O_data[i, :], O_protos[j, :]) + \
gamma * sigma(C_data[i, :], C_protos[j, :])
if distance < mindistance:
mindistance = distance
cluster = j
if clusterShip[i] != cluster:
oldCluster = clusterShip[i]
clusterShip[i] = cluster
clusterCount[cluster] += 1
clusterCount[oldCluster] -= 1
for j in range(len(O)):
sumInCluster[cluster][j] += O_data[i,j]
sumInCluster[oldCluster][j] -= O_data[i,j]
O_protos[cluster,j] = sumInCluster[cluster][j] / clusterCount[cluster]
O_protos[oldCluster, j] = sumInCluster[oldCluster][j] / clusterCount[oldCluster]
for j in range(len(C)):
freqInCluster[cluster][j] += Counter(C_data[i,j])
freqInCluster[oldCluster][j] -= Counter(C_data[i,j])
C_protos[cluster,j] = freqInCluster[cluster][j].most_common()[0][0]
C_protos[oldCluster,j] = freqInCluster[oldCluster][j].most_common()[0][0]
return clusterShip
if __name__ == "__main__":
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
O, C, O_data, C_data, O_protos, C_protos = findprotos(iris.data, 3)
print(O)
print("==============")
print(C)
print("==============")
print(O_data)
print("==============")
print(C_data)
print("==============")
print(O_protos)
print(O_protos[1,1])
print("==============")
print(C_protos)
cluster = KPrototypes(data=iris.data,k=3, max_iters=30)
print(cluster)
s2 = pd.DataFrame(np.concatenate([iris.data, np.array([cluster]).T], axis=1))
s2.to_csv("c:/users/ll/desktop/s2.csv")
上述代码对iris数据集进行了聚类,展现图形如下:
library(grid)
library(ggplot2)
s1 <- read.csv('s1.csv', header=T)
s2<- read.csv('s2.csv', header=T)
p1 <- ggplot(s1, aes(X0,X1, color=as.factor(X4))) + geom_point()
p2 <- ggplot(s2, aes(X0,X1, color=as.factor(X4))) + geom_point()
grid.newpage()
vp1 <- viewport(x=0, y=0.5, width=1,height=0.5, just=c('left','bottom'))
vp2 <- viewport(x=0, y=0, width=1,height=0.5, just=c('left','bottom'))
print(p1, vp=vp1)
print(p2, vp=vp2)
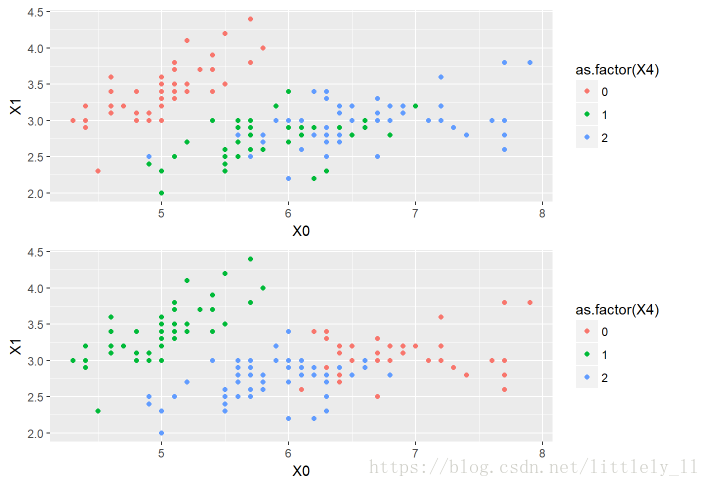
以目标变量为着色点,可以看出聚类后的分类和原始的分类非常接近,说明聚类效果比较好。
github地址: KPrototypes聚类

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









