







1. Kaggle数据集介绍
狗的类别识别:https://www.kaggle.com/c/dog-breed-identification
我们将识别 120 类不同品种的狗。 这个数据集实际上是著名的 ImageNet 的数据集子集。

数据分布:
2. 下载数据和数据整理(kaggle官网即可)
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
import numpy as np
# 如果使用测试数据:
# d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip',
# '0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d'
demo = False
if demo:
data_dir = d2l.download_extract('dog_tiny')
else:
data_dir = os.path.join('..', 'data', 'dog-breed-identification')
# 数据分为训练数据集、验证数据集、测试数据集,并分别复制到对应的文件夹之中
"""如果数据量不大(对于我个人的主机,几个G的数据还是可以这样做),但是数据太大就不建议了,这样数据会被复制两次"""
def reorg_dog_data(data_dir, valid_ratio):
labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))
d2l.reorg_train_valid(data_dir, labels, valid_ratio)
d2l.reorg_test(data_dir)
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_dog_data(data_dir, valid_ratio)
3. 图像增广
ImageNet的图片大小是要大于CIFAR-10的,对图片进行裁减可以提高训练效率,同时减小误差
transform_train = torchvision.transforms.Compose([
# 随机裁剪图像,所得图像为原始面积的0.08到1之间,高宽比在3/4和4/3之间。
# 然后,缩放图像以创建224 x 224的新图像
torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0),
ratio=(3.0 / 4.0, 4.0 / 3.0)),
torchvision.transforms.RandomHorizontalFlip(),
# 随机更改亮度,对比度和饱和度
torchvision.transforms.ColorJitter(brightness=0.4, contrast=0.4,
saturation=0.4),
# 添加随机噪声
torchvision.transforms.ToTensor(),
# 标准化图像的每个通道
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
4. 加载数据
# 注意四个datasets:train_valid_ds 是train_ds和valid_ds的集合(通常我们是根据这个数据集来划分train和valid的)
train_ds, train_valid_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [
torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
train_iter, train_valid_iter = [
torch.utils.data.DataLoader(dataset, batch_size, shuffle=True,
drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = torch.utils.data.DataLoader(valid_ds, batch_size, shuffle=False,
drop_last=True)
test_iter = torch.utils.data.DataLoader(test_ds, batch_size, shuffle=False,
drop_last=False)
查看一下增强之后的数据:查看一下增强之后的数据:
from mpl_toolkits.axes_grid1 import ImageGrid
def imshow(axis, inp):
"""Denormalize and show"""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
axis.imshow(inp)
img, label = next(iter(train_iter))
print(img.size(), label.size())
fig = plt.figure(1, figsize=(16, 4))
grid = ImageGrid(fig, 111, nrows_ncols=(3, 4), axes_pad=0.05)
for i in range(12):
ax = grid[i]
img_data = img[i]
imshow(ax, img_data)
torch.Size([128, 3, 224, 224]) torch.Size([128]

5.微调模型
深度学习框架的高级API提供了在ImageNet数据集上预训练的各种模型。在这里我们选择ResNet-34模型,重构其输出层即可
def get_net(devices):
finetune_net = nn.Sequential()
finetune_net.features = torchvision.models.resnet50(pretrained=True)
# 定义一个新的输出网络,共有120个输出类别
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 512), nn.ReLU(),
nn.Linear(512, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices[0])
# 冻结参数
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
"""计算损失之前,首先获取预训练模型的输出层之前的输出,然后使用这个输出作为我们自定义的输出层的输入,进行损失计算"""
loss = nn.CrossEntropyLoss(reduction='none')
def evaluate_loss(data_iter, net, devices):
l_sum, n = 0.0, 0
for features, labels in data_iter:
features, labels = features.to(devices[0]), labels.to(devices[0])
outputs = net(features)
l = loss(outputs, labels)
l_sum += l.sum()
n += labels.numel()
return l_sum / n
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
# 只训练小型自定义输出网络
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 注意这里进行训练的部分是都可以求解梯度的部分(即我们自定义的部分)
trainer = torch.optim.SGD(
(param for param in net.parameters() if param.requires_grad), lr=lr,
momentum=0.9, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss']
if valid_iter is not None:
legend.append('valid loss')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
for epoch in range(num_epochs):
metric = d2l.Accumulator(2)
for i, (features, labels) in enumerate(train_iter):
timer.start()
features, labels = features.to(devices[0]), labels.to(devices[0])
trainer.zero_grad()
output = net(features)
l = loss(output, labels).sum()
l.backward()
trainer.step()
metric.add(l, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1], None))
measures = f'train loss {metric[0] / metric[1]:.3f}'
if valid_iter is not None:
valid_loss = evaluate_loss(valid_iter, net, devices)
animator.add(epoch + 1, (None, valid_loss.detach()))
scheduler.step()
if valid_iter is not None:
measures += f', valid loss {valid_loss:.3f}'
print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
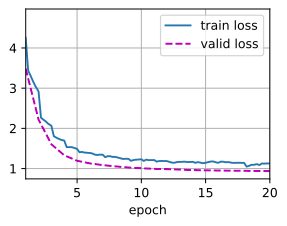
Resnet35+Adam优化
# Adam的结果太丝滑了
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 1e-4, 1e-4
lr_period, lr_decay, net = 5, 0.5, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay)
train loss 1.130, valid loss 0.936
461.9 examples/sec on [device(type='cuda', index=0)]
resnet50 + SGD
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 1e-4, 1e-4
lr_period, lr_decay, net = 2, 0.75, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,lr_decay)
train loss 0.751, valid loss 0.734
228.5 examples/sec on [device(type='cuda', index=0)]

6.可视化validation数据
def visualize_model(valid_iter, net, devices, num_images=16):
cnt = 0
fig = plt.figure(1, figsize=(16, 16))
grid = ImageGrid(fig, 111, nrows_ncols=(4, 4), axes_pad=0.05)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for i, (inputs, labels) in enumerate(valid_iter):
outputs = net(inputs.to(devices[0]))
_, preds = torch.max(outputs.data, 1)
for j in range(inputs.size()[0]):
ax = grid[cnt]
imshow(ax, inputs.cpu().data[j])
ax.text(10, 210, '{}/{}'.format(preds[j], labels.data[j]),
color='k', backgroundcolor='w', alpha=0.8)
cnt += 1
if cnt == num_images:
return
visualize_model(valid_iter,net ,devices)

7. 输出测试结果并提交kaggle
preds = []
for data, label in test_iter:
output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=0)
preds.extend(output.cpu().detach().numpy())
ids = sorted(
os.listdir(os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))
with open('./kaggle_submission/dog/submission4.csv', 'w') as f:
f.write('id,' + ','.join(train_valid_ds.classes) + '\n')
for i, output in zip(ids, preds):
f.write(
i.split('.')[0] + ',' + ','.join([str(num)
for num in output]) + '\n')
最后看看成绩(只使用ResNet-35模型,调参只是lr和LRStep在变化):

这个排名在四年前大概800名左右,仔细调参应该可以排到700名左右,score达到0.7?【炼丹吧大师!!!】



















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











