






把具体公式怎么推导的整理了一下
Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束。
基本的Mean Shift算法
给定d维空间Rd的n个样本点 ,i=1,…,n,在空间中任选一点x,那么Mean Shift向量的基本形式定义为:
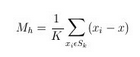
Sh是一个半径为h的高维球区域,满足以下关系的y点的集合:
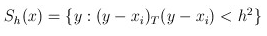
k表示在这n个样本点xi中,有k个点落入Sk区域中
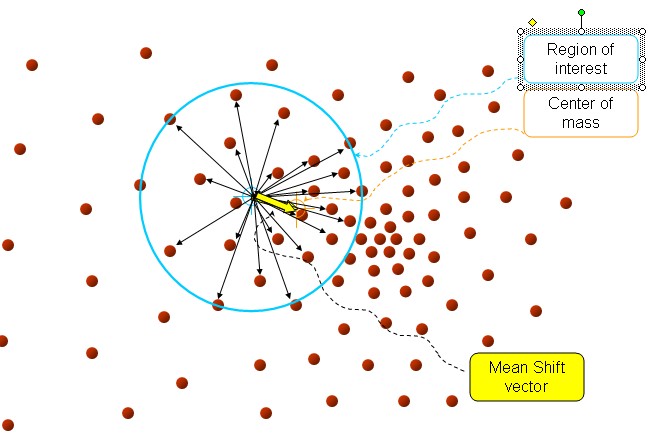
也就是,在d维空间中,任选一个点,然后以这个点为圆心,h为半径做一个高维球,因为有d维,d可能大于2,所以是高维球。落在这个球内的所有点和圆心都会产生一个向量,向量是以圆心为起点落在球内的点位终点。然后把这些向量都相加。相加的结果就是Meanshift向量。图中黄色箭头即为Meanshift向量。再以meanshift向量的终点为圆心,再做一个高维的球。如下图所以,重复以上步骤,就可得到一个meanshift向量。如此重复下去,meanshift算法可以收敛到概率密度最大得地方。也就是最稠密的地方。
以上是基本的Meanshift向量,可以看出只要是落入球内的点无论离x远近最后的作用效果是一样的,但是,一般来说离x越近的采样点对x的估计越有效,因此引入核函数概念。即对每个样本引入权重系数。
扩展的Meanshift
首先介绍核密度估计
核心思想是通过统计概率P来估计概率密度函数p(x)
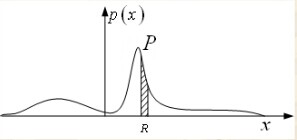
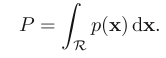
假设N个样本数据点的集合X={x1,x2……xn}是根据概率密度函数p(x)的分布独立抽取得到,那么有K个样本落入区域R内的概率服从二项分布
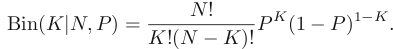
K的期望为E(K)=NP,对P的估计为P’=K/N(当N足够大,该估计有一定准确性)
假设概率密度函数p(x)连续,R足够小使得R内p(x)几乎不变,R的体积为V则 P=p(x)*V
因为P’=K/N 代入得:
p(x)=K/(NV)…………………………(1)
当V不变,通过K估算密度函数。
假设区域R是一个以x为中心,边长为h的极小立方体
定义核函数
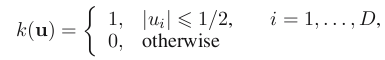
数据维数为D维,当样本数据点落入小立方体时,函数值为1,其他情况下为0。所以落入立方提数据点的总个数K就可以表示为
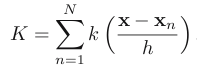
将(2)代入(1)得:
对于径向对称核函数,核函数K(x)满足:
Ck,d是一个归一化的常量,能够保证K(x)积分为一
径向基函数通常定义空间中一点x到某一中心点xc的欧氏距离的单调函数为K(||x-xc||)其作用往往是局部的,即x远离xc时取值很小。
代入(3)得
要使得上式f得到最大,最容易想到的就是对上式进行求导,得
令g(x)=—k'(x)也就是求导的负方向(5)式可以表示为:
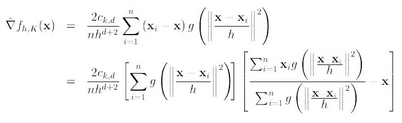
x点处基于核函数g(x)的非参数密度估计,也就是上式第一项为
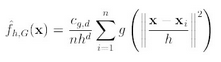
第二项就相当于一个meanshift向量的式子
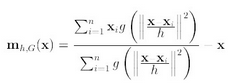
(6)式即可表示为
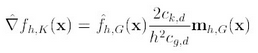
要使(9)式等于0,当且仅当(8)式等于0,即可得新的圆心坐标
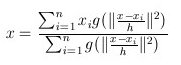
具体的算法流程:
- 选择空间中x为圆心,以h为半径为半径,做一个高维球,落在所有球内的所有点xi
- 计算
 ,如果<ε(人工设定),推出程序。如果>ε, 则利用(10)计算x,返回1.
,如果<ε(人工设定),推出程序。如果>ε, 则利用(10)计算x,返回1.















 7651
7651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









