







可供参考的链接:https://zhuanlan.zhihu.com/p/65321082
一.本文研究的主要内容
- 主要解决目前实例分割速度慢,对于重叠部分分割不准确问题
二.本文的创新点
- 提出了一个更高效的实例分割算法
- 提出的框架简单有效,有助于简化实例级识别的未来研究
- 提出了RoIAlign在mask分支上替代Faster R-CNN中的RoIpolling
三.本文的整体结构
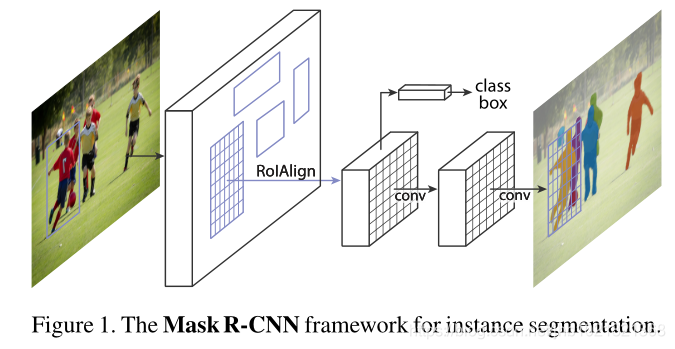
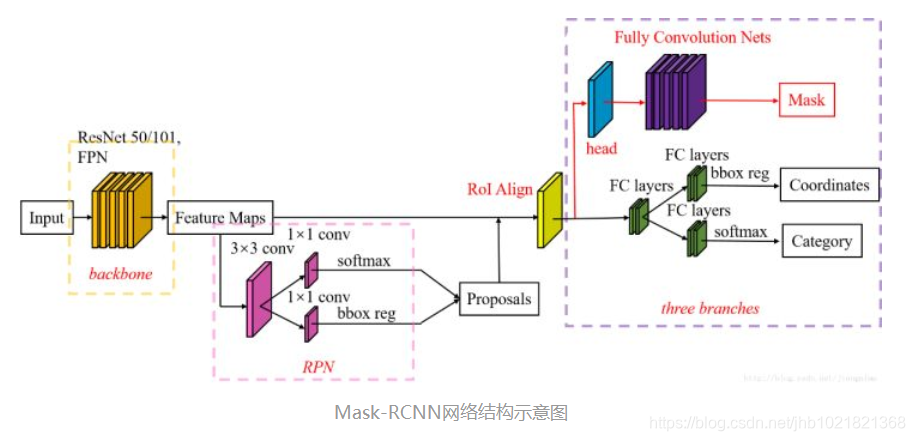
本文提出的方法是建立在Faster Rcnn的回归校正和分类分支上又并联了一个Mask分支达到像素级别的分类,同时采用RoIAlign替代了RoIpolling,同时作者在实验部分对Backbone(主干网络)的RPN(提取候选区域)网路部分的输入选择了FPN(特征金字塔模型)进行测试,如下图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DeUKedct-1589957149797)(https://i.loli.net/2020/05/19/VlqjXmWd3RPSOk2.png)]](https://img-blog.csdnimg.cn/20200520144816353.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8qUQS06B-1589957149822)(https://i.loli.net/2020/05/19/aJMy2s5WG7UxlN9.png)]](https://img-blog.csdnimg.cn/20200520144833161.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
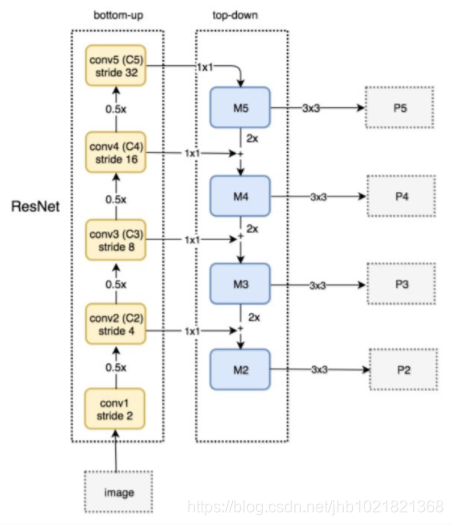
上面这个是一个FPN网络的整体设计,下面这个是具体的基于Resnet的FPN网络
四.Faster Rcnn回顾
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Adk2Lu5-1589957149834)(https://i.loli.net/2020/05/19/OMyHCvbJVLBzfRU.png)]](https://img-blog.csdnimg.cn/20200520144951834.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
链接:https://zhuanlan.zhihu.com/p/59186710
https://zhuanlan.zhihu.com/p/31426458
五.RoIAlign
原来的RoIPolling
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800800,最后一层特征图feature map大小:2525
2)假定原图中有一region proposal,大小为665665,这样,映射到特征图中的大小:665/32=20.78,即20.7820.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20*20
3)假定pooled_w=7,pooled_h=7,即pooling后固定成77大小的特征图,所以,将上面在 feature map上映射的2020的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.862.86,此时,进行第二次量化,故小区域大小变成22
4)每个22的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成77大小的feature map
总结,所以,通过上面可以看出,经过两次量化,即将浮点数取整,原本在特征图上映射的2020大小的region proposal,偏差成大小为1414的,这样的像素偏差势必会对后层的回归定位产生影响
- 注:RoIPolling 实际上进行了两次量化的过程
RoIAlign
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A08CDaJA-1589957149836)(https://i.loli.net/2020/05/19/VLjokmG1UTMnavD.png)]](https://img-blog.csdnimg.cn/20200520145011519.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800800,最后一层特征图feature map大小:2525
2)假定原图中有一region proposal,大小为665665,这样,映射到特征图中的大小:665/32=20.78,即20.7820.78,此时,没有像RoiPooling那样就行取整操作,保留浮点数
3)假定pooled_w=7,pooled_h=7,即pooling后固定成77大小的特征图,所以,将在 feature map上映射的20.7820.78的region proposal 划分成49个同等大小的小区域,每个小区域的大小20.78/7=2.97,即2.97*2.97
4)假定采样点数为4,即表示,对于每个2.97*2.97的小区域,平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,如下图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IlfHxGYP-1589957149839)(https://i.loli.net/2020/05/19/c6SIfHzXA3piJrl.png)]](https://img-blog.csdnimg.cn/20200520145025929.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mYIWDTqL-1589957149842)(https://i.loli.net/2020/05/19/wkXl1Oojr2CqTnU.png)]](https://img-blog.csdnimg.cn/20200520145040608.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2poYjEwMjE4MjEzNjg=,size_16,color_FFFFFF,t_70)
最后,取四个像素值中最大值作为这个小区域(即:2.972.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成77大小的feature map
注:
参考:https://blog.csdn.net/u013066730/article/details/84062027














 3912
3912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









