







我将课后编程作业与习题放在我的GitHub上了,需要的可以自取:
GitHub - chicx1229/fluffy-computing-machine: 吴恩达2022机器学习课后编程作业与习题
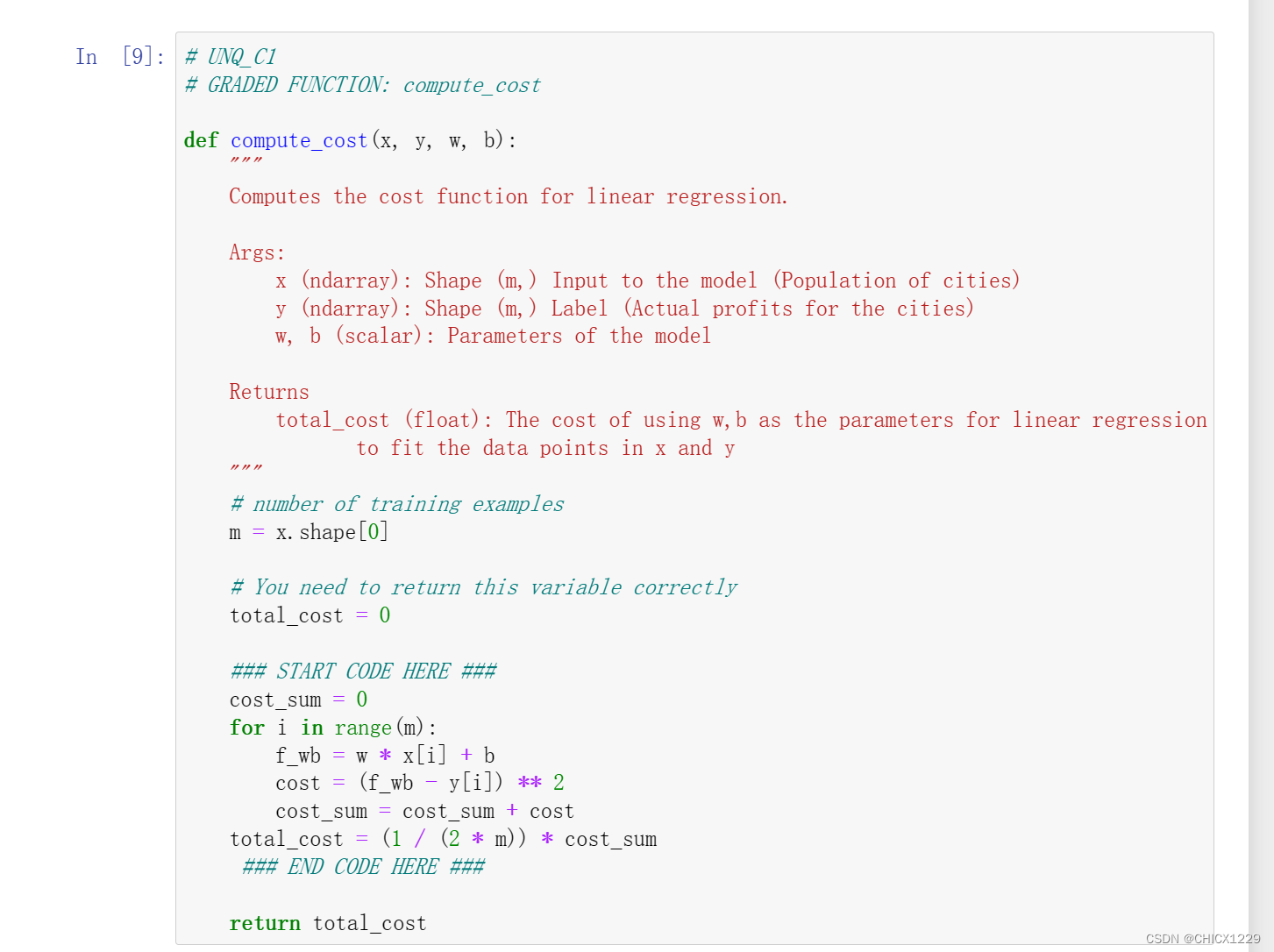
分析说明:
这个函数是计算线性回归模型的成本函数。这个函数会接受输入x和y的数据,以及模型的参数w和b。然后,它计算模型在给定参数w和b下的预测值,并计算预测值与实际标签之间的差异的平方。最后,它将所有差异的平方加总起来,并返回平均误差的一半作为成本值。
在代码中,我们首先计算训练样本的数量m,并初始化total_cost为0。然后,我们使用一个循环遍历所有的训练样本,计算每个样本的预测值和实际标签之间的差异的平方,并加总到cost_sum中。最后,我们将cost_sum除以训练样本数量的两倍,得到平均误差的一半作为成本值,并返回该值。
心得体会:
这个代码实现了一个计算线性回归模型成本函数的函数。在计算成本函数时,我们遍历每个训练样本,并计算模型预测值与实际标签之间的平方差。然后将所有差值的平方加总起来,并最终计算平均误差的一半作为成本值。这个成本函数的值越小,表示模型的拟合效果越好。
通过编写这段代码,我理解了如何计算线性回归模型的成本函数,并且理解了成本函数是用来评估模型拟合效果的重要指标。在机器学习中,我们经常需要优化模型的参数以减小成本函数的值,从而提高模型的性能。这段代码帮助我加深了对成本函数的理解,并帮助我提升了对线性回归模型的实现和评估的能力。

分析说明:
这段代码实现了一个计算线性回归模型梯度的函数。该函数接受输入x和y的数据,以及模型的参数w和b,并计算成本函数对参数w和b的梯度。通过计算梯度,我们可以确定如何调整参数值以使成本函数最小化。
在代码中,我们首先计算训练样本的数量m,并初始化梯度变量dj_dw和dj_db为0。然后,我们使用一个循环遍历所有的训练样本,计算每个样本的梯度值。对于参数w的梯度,我们计算预测值与实际标签之间差异乘以输入值x[i];对于参数b的梯度,我们计算预测值与实际标签之间的差异。最后,我们将梯度值累加到dj_dw和dj_db中,并求取平均值以得到最终的梯度值。
通过这段代码,我们可以进一步了解如何计算线性回归模型的梯度,并在优化算法中使用梯度下降来更新模型的参数以最小化成本函数。这个函数提供了一个基础框架,可以用于构建更复杂的优化算法,进而改进模型的性能和拟合能力。
心得体会:
这段代码实现了计算线性回归模型梯度的函数。通过计算梯度,我们可以确定如何调整模型的参数以最小化成本函数。在代码中,首先计算训练样本的数量m,并初始化参数梯度dj_dw和dj_db为0。然后,通过循环遍历每个训练样本,计算每个样本对参数w和b的梯度值。其中,对参数w的梯度是模型预测值与实际标签之间的差异乘以输入值x[i],对参数b的梯度是模型预测值与实际标签之间的差异。最后计算平均梯度值,并返回梯度值。
通过编写这段代码,我深入了解了如何计算线性回归模型的梯度,并在优化过程中使用梯度下降算法更新模型参数。这段代码为进一步构建机器学习模型提供了基础操作,并帮助我加深了对机器学习基本原理的理解。在实践中,理解梯度下降算法对于优化模型参数具有重要意义,可以帮助提高模型性能和拟合能力。















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









