







随机森林
随机森林(random forest)是将多个模型综合起来创建更高性能模型的方法,既可用于回归,也可用于分类。同样的算法有梯度提升(gradient boosting)等在机器学习竞赛中很受欢迎的算法。
通过学习随机森林,我们可以学到在其他算法中也适用的基础知识。
概述
随机森林的目标是利用多个决策树模型,获得比单个决策树更高的预测精度。单个决策树的性能并不一定很高,但是多个决策树汇总起来,一定能创建出泛化能力更强的模型。
随机森林既可用于回归,也可用于分类,这里以分类问题为例进行说明。图 2-30 是随机森林分类算法的示意图。该算法从每个决策树收集输出,通过多数表决得到最终的分类结果。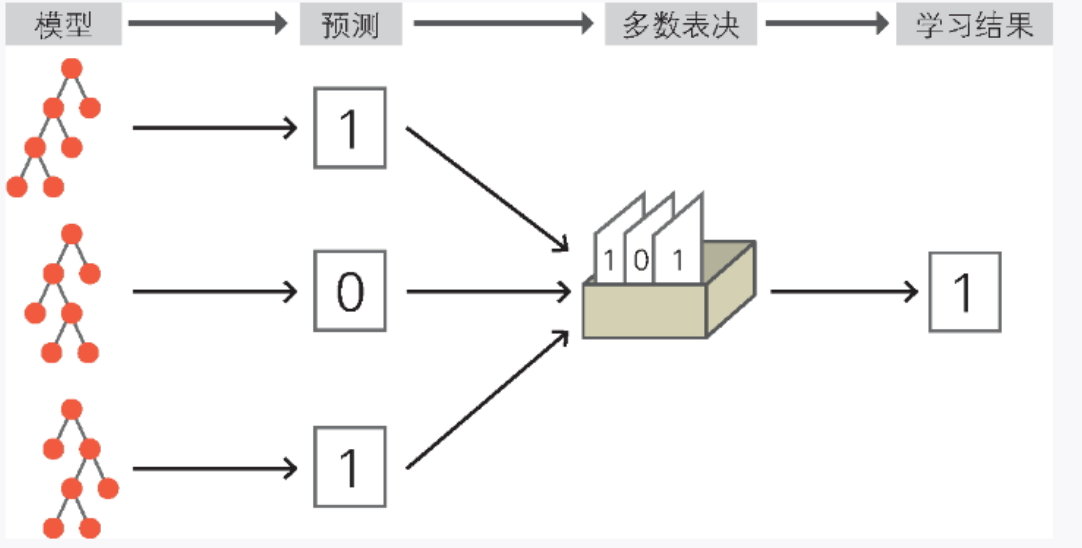
▲图 2-30 随机森林的示意图
随机森林的多数表决就像找别人商量事情一样,不只听一个人的意见,而是在听取许多人的意见之后综合判断。机器学习也一样,通过创建多个模型,采取多数表决的方式,可以期待获得更为妥当的结果。
需要注意的是,如果使用同样的学习方法创建决策树,那么输出的就都是同样的东西,也就失去了采取多数表决的意义。在随机森林中,采用的决策树要具备多样性,这一点很重要。下面的“算法说明”部分将介绍决策树的算法,以及随机森林如何使决策树具有多样性。
算法说明
随机森林是综合决策树的结果的算法。本节先介绍决策树的基本内容,再介绍如何综合决策树的结果。
决策树
决策树是通过将训练数据按条件分支进行划分来解决分类问题的方法,在分割时利用了表示数据杂乱程度(或者不均衡程度)的不纯度的数值。决策树为了使表示数据杂乱程度的不纯度变小,对数据进行分割。当分割出来的组中存在很多相同的标签时,不纯度会变小;反之,当分割出来的组中存在很多不同的标签时,不纯度会变大。
表示不纯度的具体指标有很多种,本节利用基尼系数。基尼系数的计算式如下:
基尼系数![]()
C 是标签数,pi 是某个标签的数据数量占数据总数的比例。
图 2-31 所示为使用几种不同的分割方法计算得出的加权平均基尼系数。左侧是分割前的状态,这时的基尼系数为 0.5。中间是分割后求出的基尼系数的平均值。使用分割出的每个部分的基尼系数乘以该部分所含数据的数量所占的比例,得到加权平均值。右侧是使基尼系数的平均值最小的分割方法的例子。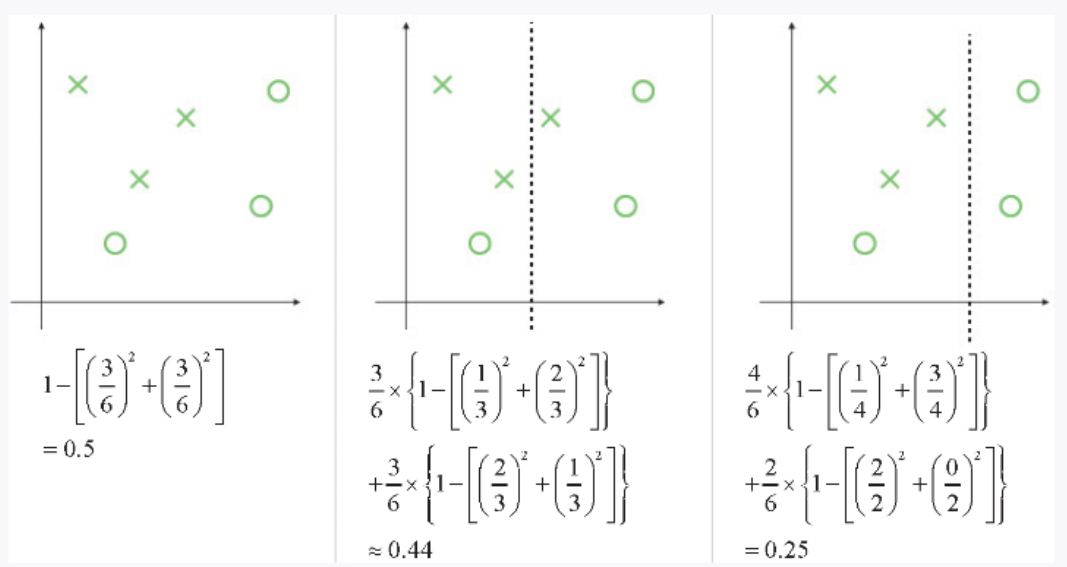
▲图 2-31 不同分割位置导致不纯度不同
决策树的学习是通过反复分割像图 2-31 那样的空间来进行的。具体来说,就是重复以下流程。
1 计算某个区域的所有特征值和候选分割的不纯度。
2 以分割时不纯度减小最多的分割方式分割区域。
3 对于分割后的区域,重复步骤 1 和步骤 2。
4 决策树学习的过程如图 2-32 所示。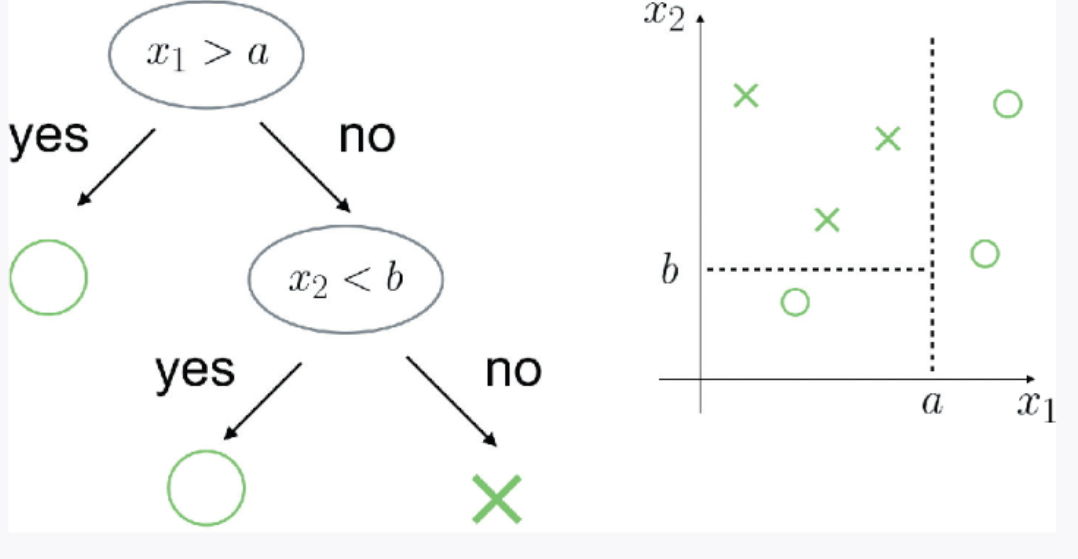
▲图 2-32 决策树学习的示意图
随机森林
随机森林是如何使用多棵决策树来提高精度的呢?假设有 3 棵独立的决策树,每棵的正确率为 0.6。此时,对每棵决策树的结果进行多数表决,并将表决结果作为预测结果,即可提高正确率。在这种情况下,预测不正确有两种情况:一种是所有的决策树都预测不正确(概率为 ![]() );另一种是 3 棵决策树中有 2 棵预测不正确(概率为
);另一种是 3 棵决策树中有 2 棵预测不正确(概率为 ![]() ),所以正确的概率是 1 - 0.064 - 0.288 = 0.648。可以看出,正确率的确变高了。
),所以正确的概率是 1 - 0.064 - 0.288 = 0.648。可以看出,正确率的确变高了。
接下来,让我们思考如何使用相同的数据训练多棵独立的决策树。这其实并不简单。机器学习从相同的数据上学习的结果基本上是一样的,即使有 100 棵决策树,如果它们的学习方法都一样,那么多数表决的结果也还是一样的。
随机森林尝试对每棵决策树的数据应用下述方法来进行训练,以使分类结果尽可能地不同。首先采用 Bootstrap 方法,根据训练数据生成多个不同内容的训练数据。所谓 Bootstrap 方法,即通过对单个训练数据进行多次随机的抽样放回,“虚增”训练数据,这样就可以为每棵决策树输入不同的训练数据。然后在根据使用 Bootstrap 方法创建的训练数据训练决策树时,只随机选取部分特征值来训练决策树。通过“Bootstrap 方法”和“随机选取特征值”这两种方法,就可以训练出具有多样性的决策树(图 2-33)。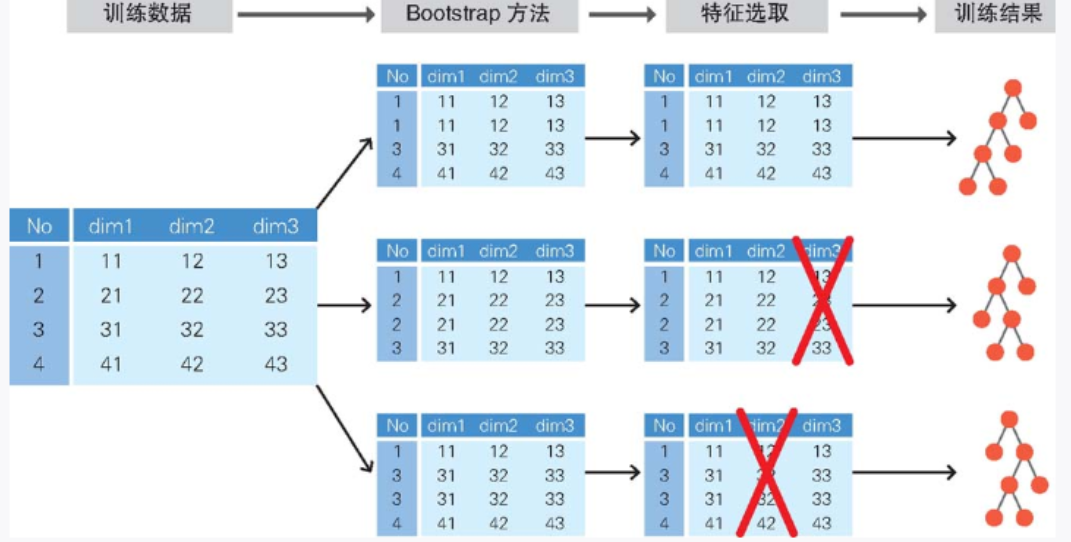
▲图 2-33 Bootstrap 方法
随机森林利用这种方式创建多棵数据集、训练多棵决策树、对预测结果进行多数表决,返回最终的分类结果。
示例代码
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_wine()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3)
model = RandomForestClassifier()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_pred, y_test)结果:
0.9629629629629629
详细说明
特征的重要度
随机森林可以让我们知道每个特征对预测结果的重要度。下面我们先了解一下特征重要度的计算方法,然后以葡萄酒分类为例,看一下各特征的重要度。首先介绍一下使用随机森林计算重要度的方法。前面讲过,每棵决策树的学习方法都是通过沿着某个值分割特征,使不纯度尽可能地小。通过对随机森林的所有决策树求在以某个特征分割时的不纯度并取平均值,可以得到特征的重要度。将重要度高的特征用于分割,有望大幅度减小不纯度。反之,重要度低的特征即使被用于分割,也无法减小不纯度,所以可以说这样的特征是非必要的。基于特征的重要度,我们可以去除非必要的特征。
接下来,我们以葡萄酒分类为例,看一下特征的重要度。图 2-34 所示为使用随机森林算出的特征重要度。图中重要度高的特征 color_intensity 表示色泽,这说明它对葡萄酒的分类非常重要,这个结论直观,让人信服。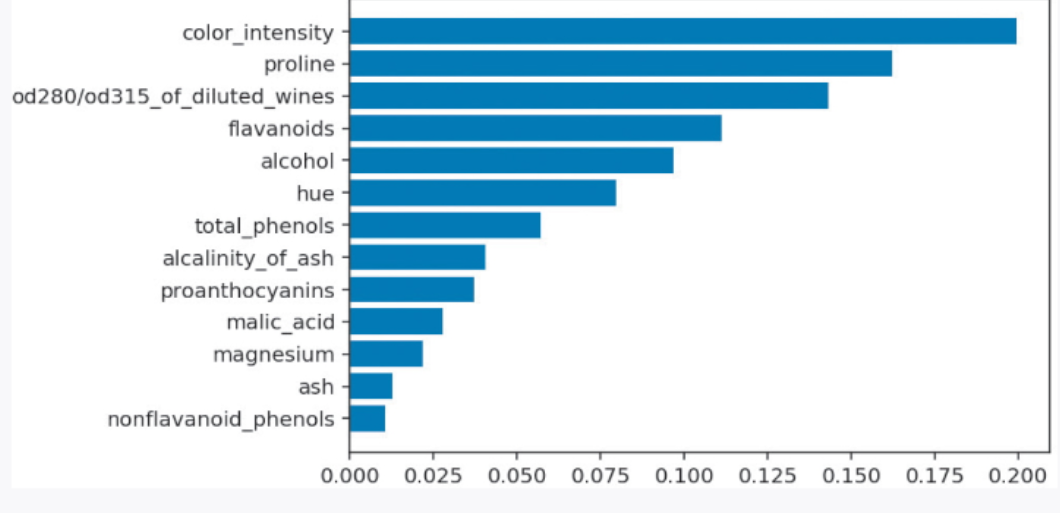
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者宫崎修一和石田保辉的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









