







逻辑回归
逻辑回归是一种用于有监督学习的分类任务的简单算法。虽然算法的名字中包含“回归”二字,但其实它是用于分类问题的算法。逻辑回归通过计算数据属于各类别的概率来进行分类。
概述
逻辑回归是一种学习某个事件发生概率的算法。利用这个概率,可以对某个事件发生或不发生进行二元分类。
虽然逻辑回归本来是二元分类的算法,但也可以用于三种类别以上的分类问题。
为了理解这个算法,请思考以下例子。
你在回家的路上发现下雪了。如果明天积雪,你就必须从鞋柜里翻出雪天穿的靴子做好准备。现在的气温是 2 ℃。请问明天不积雪,你可以穿平时的鞋子出门的概率是多少呢?
这里使用虚构的 100 天的数据,通过逻辑回归求出可以穿平时的鞋子出门的概率。以气温为横轴 x,当出现积雪而需要穿着雪天穿的靴子出门时,纵轴 y 的值为 0;当雪已经融化、可以穿着平时的鞋子外出时,纵轴 y 的值为 1,绘制得到的数据散点图如图 2-12 所示。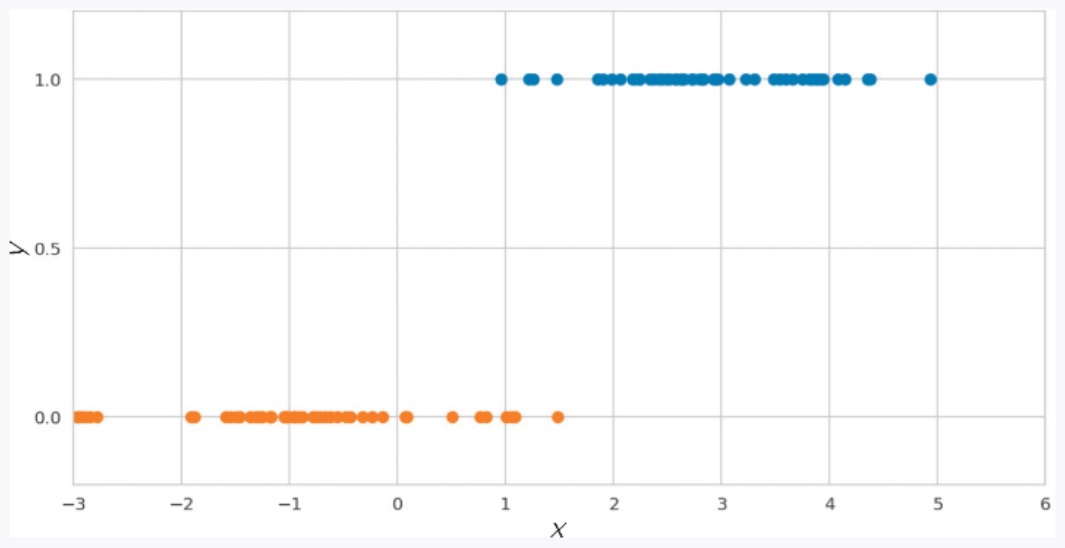
▲图 2-12 使用 100 天的数据绘制的散点图
在这里使用逻辑回归,我们就可以得到如图 2-13 中的绿线所示的曲线,并利用该曲线求出在不同的气温下,雪已经融化、可以穿着平时的鞋子外出的概率。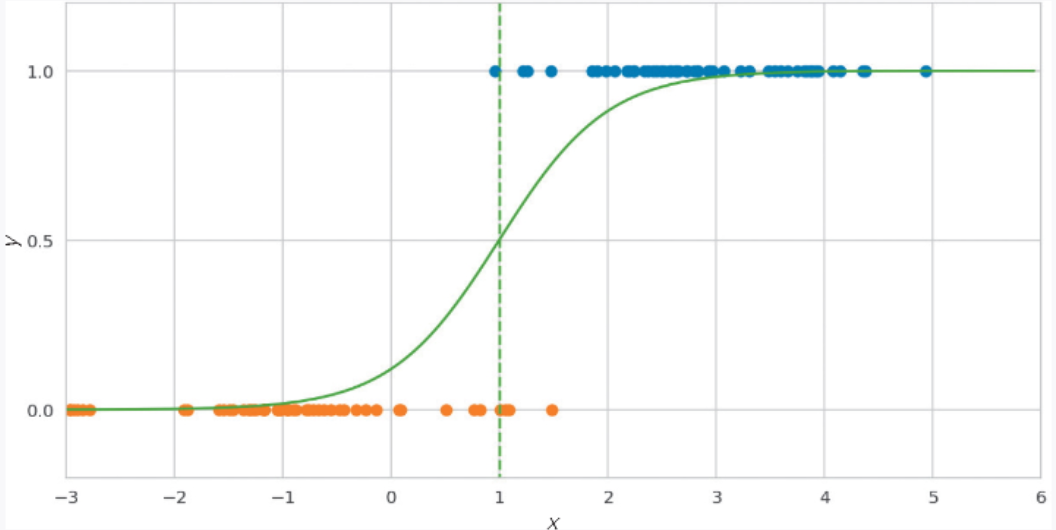
▲图 2-13 逻辑回归
具体来说,计算得到的概率分别是:气温为 0 ℃时的概率为 14%,为 1 ℃时的概率为 63%,为 2 ℃时的概率为 94%。看起来明天可以穿平时的鞋子外出。
算法说明
如前所述,逻辑回归根据数据 x 和表示其所属类别的标签y 进行学习,计算概率。数据 x 可以当作由特征值组成的向量处理。如果标签是二元分类,则可以使用前面的 y = 0,1 这种二元数值表示。
逻辑回归的基本思想与线性回归一样,对数据 x 乘以权重向量 w,再加上偏置 w0,计算 ![]() 的值。逻辑回归和线性回归在从数据中学习权重 w 和偏置 w0 这一点上是相同的。
的值。逻辑回归和线性回归在从数据中学习权重 w 和偏置 w0 这一点上是相同的。
与线性回归不同的是,为了计算概率,逻辑回归的输出范围必须限制在 0 和 1 之间。逻辑回归使用 Sigmoid 函数![]() ,返回 0 和 1 之间的数值。Sigmoid 函数的图形如图 2-14 所示。
,返回 0 和 1 之间的数值。Sigmoid 函数的图形如图 2-14 所示。
▲图 2-14 Sigmoid 函数
我们对输入数据 x 使用 Sigmoid 函数![]() ,即使用
,即使用 ![]() 计算标签为 y 的概率 p。二元分类通常将预测概率 0.5 作为阈值进行分类。例如,当概率小于 0.5 时,将 y 的预测值分类为 0;当概率大于 0.5 时,将 y 的预测值分类为 1。根据问题的不同,有时会将阈值设置为大于或小于 0.5 的值。
计算标签为 y 的概率 p。二元分类通常将预测概率 0.5 作为阈值进行分类。例如,当概率小于 0.5 时,将 y 的预测值分类为 0;当概率大于 0.5 时,将 y 的预测值分类为 1。根据问题的不同,有时会将阈值设置为大于或小于 0.5 的值。
在学习过程中,我们使用逻辑损失作为误差函数进行最小化。与其他误差函数一样,逻辑损失是在分类失败时返回大值,在分类成功时返回小值的函数。与在误差回归中引入的均方误差不同的是,我们无法通过式子变形来计算逻辑损失的最小值,因此需要采用梯度下降法通过数值计算来求解。
对于无法通过式子变形严密求解的情况,机器学习中经常会通过数值计算来近似求解。
示例代码
下面使用与前面的“概述”部分相同的数据,计算在 0 ℃、1 ℃、2 ℃时积雪的概率。由于数据是使用随机数生成的,所以每次执行时结果都有所不同。
import numpy as np
from sklearn.linear_model import LogisticRegression
# 创建两个 50 个样本的一维数组,这些样本来自于具有均值为 3 和标准差为 1 的正态分布,以及具有均值为-1 和标准差为 1 的正态分布。然后,将这两个数组在垂直方向上连接起来,形成一个 100 行、1 列的二维数组。这样,X_train 就变成了一个包含 100 个样本的训练数据,每个样本是一个数字。
X_train = np.r_[np.random.normal(3, 1, size=50), np.random.normal(-1, 1 , size=50)].reshape((100, -1))
# 创建一个包含 50 个 1 的一维数组和一个包含 50 个 0 的一维数组,然后将它们在垂直方向上连接起来,形成一个 100 维的数组。这个数组的前 50 个元素都是 1,后 50 个元素都是 0。
y_train = np.r_[np.ones(50), np.zeros(50)]
model = LogisticRegression()
model.fit(X_train, y_train)
# 使用模型来预测输入数据的概率分布。[[0], [1], [2]] 是输入数据的三个样本,模型会对每个样本生成一个概率分布。[:, 1]表示在一般情况下,概率分布通常是一个二维数组,其中第一列表示一个类别,第二列表示该类别对应的概率。通过 [:, 1],只选择了第二列,即概率值。
model.predict_proba([[0], [1], [2]])[:, 1]array([0.1411774 , 0.63543147, 0.94866702])
计算可知,在 0 ℃、1 ℃、2 ℃时概率的值(保留小数点后两位)分别约为 0.14、0.63、0.94。
详细说明
决策边界
在解决分类问题时,如果让学习后的模型对未知数据分类,模型就会以某个地方为边界来区分分类结果,这个边界就叫作决策边界。逻辑回归的决策边界是计算出的概率正好为 50% 的地方。
下面看一下在平面的情况下的决策边界的图形。使用逻辑回归学习时的训练数据和决策边界如图 2-15 所示。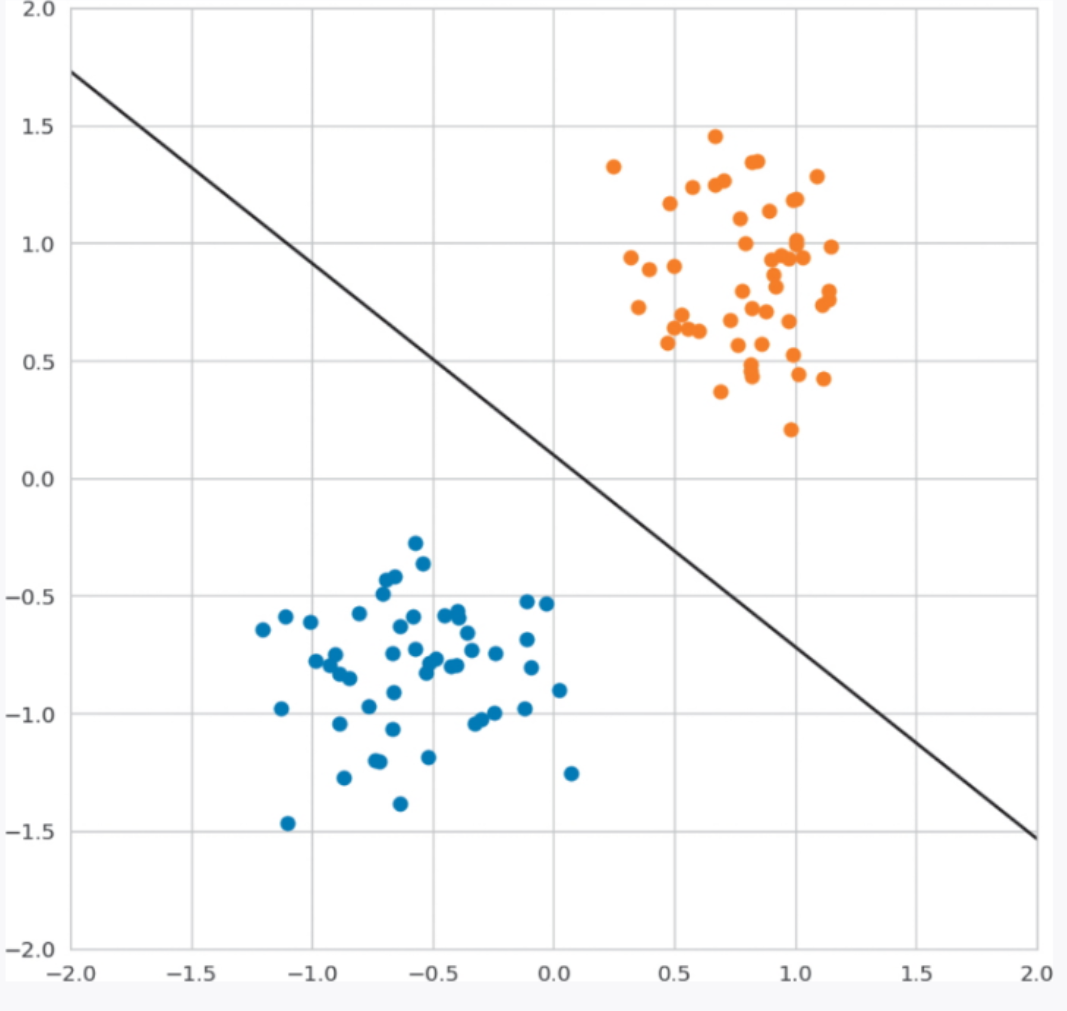
▲图 2-15 决策边界的图形
决策边界的形状因使用的算法不同而有很大的不同。在平面的情况下,逻辑回归的决策边界是直线。在其他算法中,比如 KNN 和神经网络,决策边界是更复杂的形式。详细内容将在介绍相应算法时进行说明。
对特征的解释
我们可以查看逻辑回归中每个特征的系数。通过查看每个特征的系数的符号,可以知道它对概率是正影响还是负影响。这里以第 1 章的鸢尾花数据为例,只使用其中的 setosa(山鸢尾)和 versicolor(杂色鸢尾)这两种鸢尾花的数据来确认这一点。表 2-9 所示为逻辑回归学习得到的每个特征的权重的结果。对应于 versicolor 和 setosa 的目标变量分别为 1 和 0。
▼表 2-9 每个特征的权重
这些值表示在特征值发生变化时,特征值对模型将数据标签分类为 versicolor 的概率的影响程度。下面使用 sepal width 和 petal length 两个特征绘制散点图,来查看训练数据的分布。绘制结果如图 2-16 所示。
▲图 2-16 对特征的解释
一方面,由于纵轴的 petal length 的权重是正值,所以结合权重来看,如果 petal length 变大,数据被分类为 versicolor 的比例会变大。总的来看,在图 2-16 中的上方的数据被分类为 versicolor 的比例大,而下方的数据被分类为 setosa 的比例大。
另一方面,由于 sepal width 的权重是负值,所以如果 sepal width 变小,数据被分类为 versicolor 的比例会变大。我们可以得出如下结论:在图 2-16 中偏左的地方分布着 versicolor,在偏右的地方分布着 setosa。
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者宫崎修一和石田保辉的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









