






1. 引言
随机森林是机器学习中一种非常流行的集成学习方法(它通过构建并结合多个基学习器来完成学习任务)。它通过结合多棵决策树来提高模型的预测精度和稳定性。随机森林在分类和回归问题中都表现出色,广泛应用于各个领域。本文将详细介绍随机森林的原理、优缺点及其应用。随机森林的示意图如下:
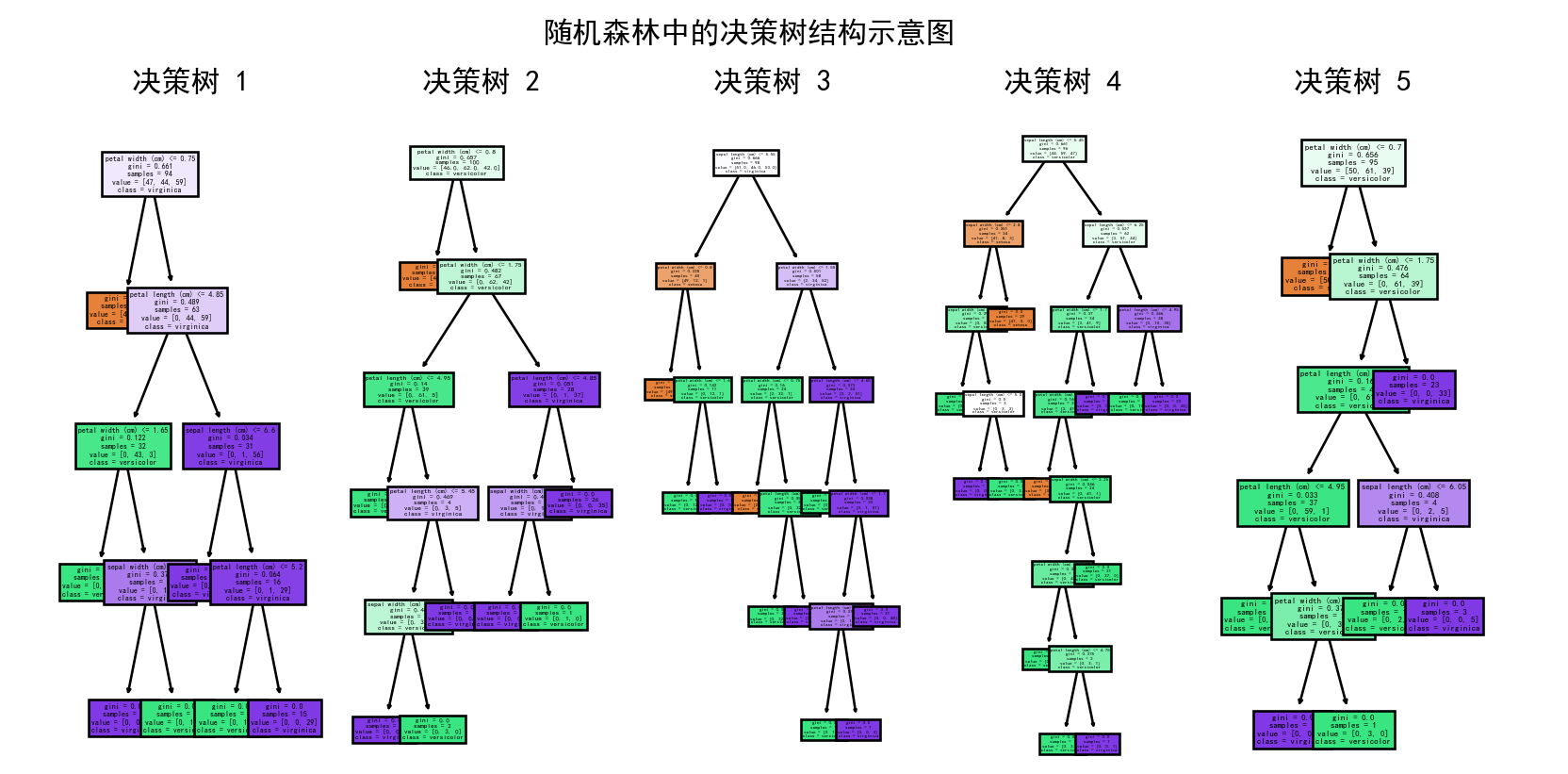
2. 随机森林的基本概念
2.1 决策树
在理解随机森林之前,首先需要了解决策树。决策树是一种树状结构的模型,通过一系列的决策规则将数据逐步分割,最终得到分类或回归的结果。决策树的构建过程是一个递归分裂的过程,每次选择一个最优的特征及其分裂点,将数据集分成若干子集,直至满足停止条件(详情可见其他博客)。
2.2 集成学习
集成学习是一种通过构建并结合多个学习器来完成学习任务的技术。其基本思想是通过多个模型的组合来提升整体性能,减少单个模型的过拟合风险。随机森林正是集成学习的一种经典方法。
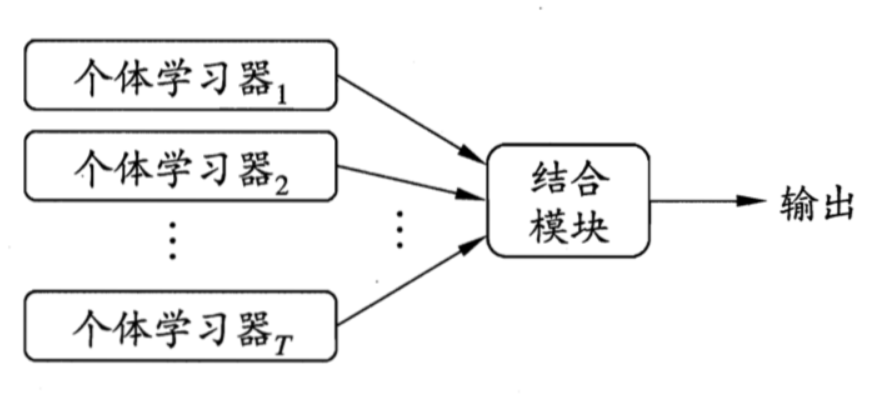
3. 随机森林的工作原理
随机森林通过集成多棵决策树来进行预测,其核心思想包括以下两个方面:
3.1 Bootstrap抽样
在构建每棵决策树时,随机森林采用了一种称为Bootstrap抽样的方法,即从原始训练集D中有放回地随机抽取多个子样本集D'。这些子样本集的大小与原始训练集相同,但由于是有放回地抽取,子样本集中可能包含重复的样本。
原始数据集: 假设我们有一个包含 n个样本的原始数据集 D={x1,x2,…,xn}。有放回抽样: 从原始数据集中进行有放回的随机抽样,生成一个新的样本集 D′。所谓有放回抽样,意味着每次抽样后,样本会被放回到原始数据集中,这样每次抽样时每个样本都有相同的概率被选中。因此,新的样本集中可能包含重复的样本。
例如,假设我们有一个包含5个样本的原始数据集 D={x1,x2,x3,x4,x5}。我们进行有放回抽样,可能得到一个新的样本集 D′={x2,x3,x2,x5,x1}其中 x2出现了两次。 重复步骤2多次(通常是数百到数千次),生成多个Bootstrap样本集 D1′,D2′,…,DB′。示意图如下:
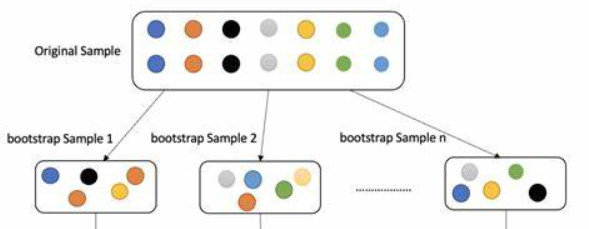
3.2 随机特征选择
在构建决策树的过程中,每次节点分裂时,随机森林不会使用所有的特征,而是从所有特征中随机选择一个特征子集,然后在这个子集中选择最优特征进行分裂。这样可以增加模型的多样性,减少过拟合。
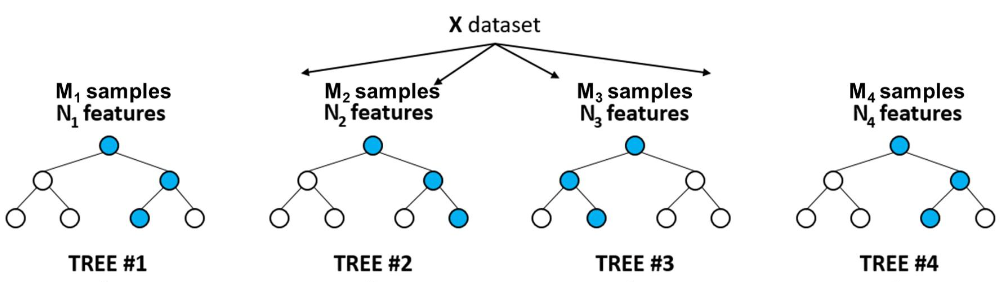
3.3 决策树的构建
每棵决策树都在一个随机抽样的子样本集上构建,并且在节点分裂时使用随机特征选择。每棵树独立生长,彼此之间没有交互。
3.4 预测
对于分类问题,随机森林通过集成所有决策树的预测结果,采用投票机制决定最终的分类结果。对于回归问题,随机森林通过平均所有决策树的预测结果,得到最终的回归值。
4. 随机森林的优缺点
4.1 优点
- 高准确率:通过集成多棵决策树,随机森林能显著提高模型的预测准确率。
- 抗过拟合:随机森林通过Bootstrap抽样和随机特征选择增加了模型的多样性,减少了单个模型的过拟合风险。
- 处理高维数据:随机森林可以处理大量特征的数据集,在高维数据上表现良好。
- 计算效率高:可以并行地构建决策树,提高了训练和预测的效率。
4.2 缺点
- 模型复杂性高:随机森林由多棵决策树组成,整体模型复杂,难以解释。
- 内存消耗大:需要存储大量的决策树,可能会占用较多内存资源。
- 对噪声敏感:虽然随机森林具有一定的抗噪性,但在处理含有大量噪声的数据时,性能可能会下降。
5. 随机森林的应用
5.1 分类问题
随机森林在分类问题中应用广泛,如文本分类、图像分类、垃圾邮件检测等。通过集成多棵决策树,随机森林能有效提高分类的准确率和稳定性。
5.2 回归问题
随机森林在回归问题中同样表现出色,如房价预测、股票价格预测等。通过平均多棵决策树的预测结果,随机森林能减少预测误差,提供更加稳定的预测值。
5.3 特征选择
随机森林还可以用于特征选择。通过计算每个特征在所有树中的重要性,可以识别出对预测结果贡献最大的特征,从而进行特征筛选和降维。
import matplotlib.pyplot as plt
from pylab import mpl
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# 加载示例数据集
data = load_iris()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target)
# 创建随机森林分类器
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 拟合模型
rf.fit(X, y)
# 获取特征重要性
importances = rf.feature_importances_
im = pd.DataFrame(importances, columns=["importances"])
clos = X.columns.values.tolist()
im['clos'] = clos
# 对特征重要性进行排序,取前10个特征
im = im.sort_values(by=['importances'], ascending=False)[:10]
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为宋体
plt.rcParams['axes.unicode_minus'] = False
# 绘制水平条形图
index = range(len(im))
plt.yticks(index, im['clos']) # 设置y轴的刻度位置和标签
plt.barh(index, im['importances']) # 创建水平条形图
plt.xlabel('特征重要性')
plt.ylabel('特征')
plt.title('随机森林中特征排名')
plt.show()
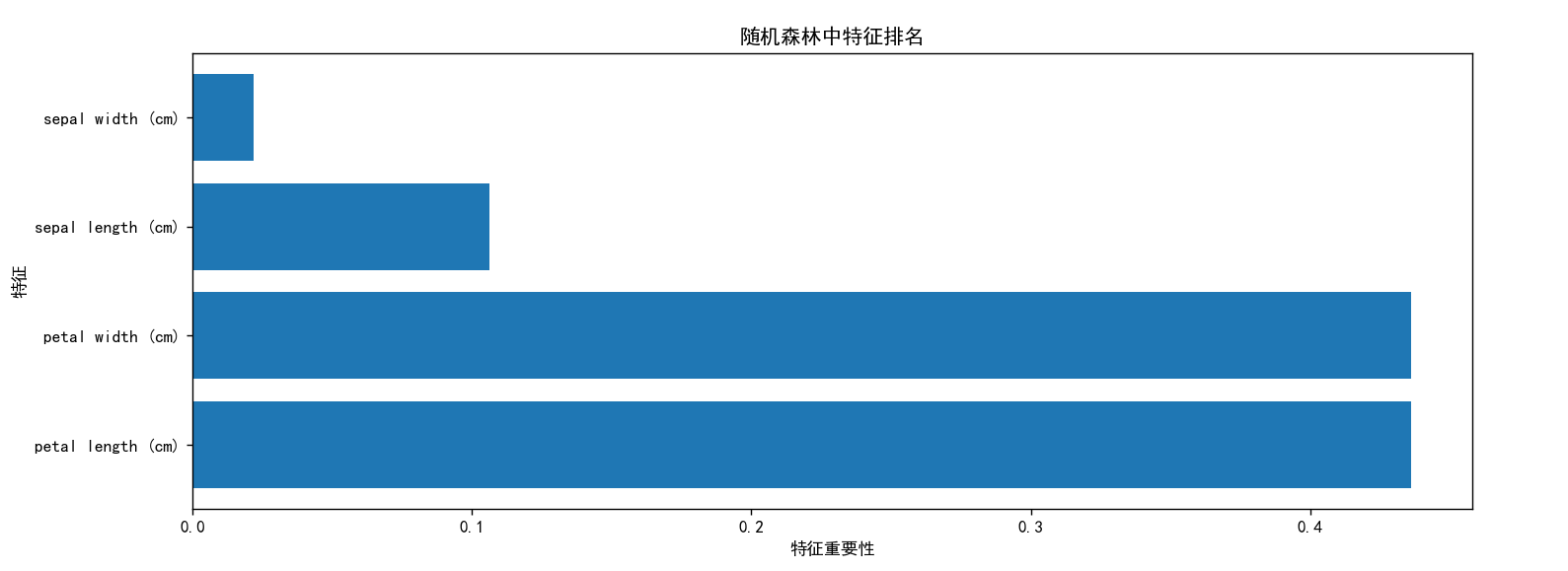

通过调试模式我们可以看到各个特征的占比并绘制出图形。
6. 总结
随机森林作为一种强大的集成学习方法,通过结合多棵决策树,实现了高准确率和稳定性的预测。其Bootstrap抽样和随机特征选择的机制,使得模型具有较强的抗过拟合能力。尽管存在模型复杂性高和内存消耗大的问题,但随机森林在分类、回归和特征选择等任务中表现出色,是一种值得应用和推广的机器学习方法。















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









