







NMF
NMF(Non-negative Matrix Factorization,非负矩阵分解)是一种降维算法,它的特点是输入数据和输出数据的值都是非负的。
这个特点在处理图像等数据时有一个优点,那就是模型的可解释性强。
概述
NMF 是一种矩阵分解方法,在计算机视觉、文本挖掘、推荐等各个领域都有应用。与 LSA 一样,它也可以找到矩阵的潜在变量,但 NMF 只适用于原始矩阵的所有元素都是非负数(即大于等于 0)的情况。NMF 具有以下特点。
- 原始矩阵的元素是非负数。
- 分解后矩阵的元素是非负数。
- 没有“潜在语义空间的每一个维度都是正交的”这一约束条件。
在将 NMF 应用于真实数据时,这些特点会带来几个优点。一个优点是分析结果的可解释性强。例如,在将 NMF 应用于文本数据时,由于文本能够以潜在变量的加法来表示,所以可以使用 NMF 对文本进行降维,然后将潜在变量视为主题,这样就能使用“某个文本的主题 A 为 0.5、主题 B 为 0.3……”的方式描述文本的信息。由于实际的文本(如新闻文章和论文)也可能包含多个主题,这就使得它们的文本建模结果的可解释性更强。但如果潜在变量为负值,比如主题 A 为 -0.3、主题 B 为 0.6……就比较难解释。
另外,NMF 没有“潜在变量必须正交”的约束条件,所以各个潜在变量可能有一定程度的信息重复。
拿前面的文本主题的例子来说,这就意味着各个主题有一定程度的信息重复。这也是符合真实数据情况的建模。
图 3-8 所示为对二维数据分别应用 NMF 和 PCA 的结果。从图中可以看出,NMF 的潜在空间的每个轴都有重复信息。这一特性使得我们可以捕捉到多个数据块的特征。而 PCA 等算法则由于其潜在空间的维度是正交的,所以无法找到所有数据块的特征。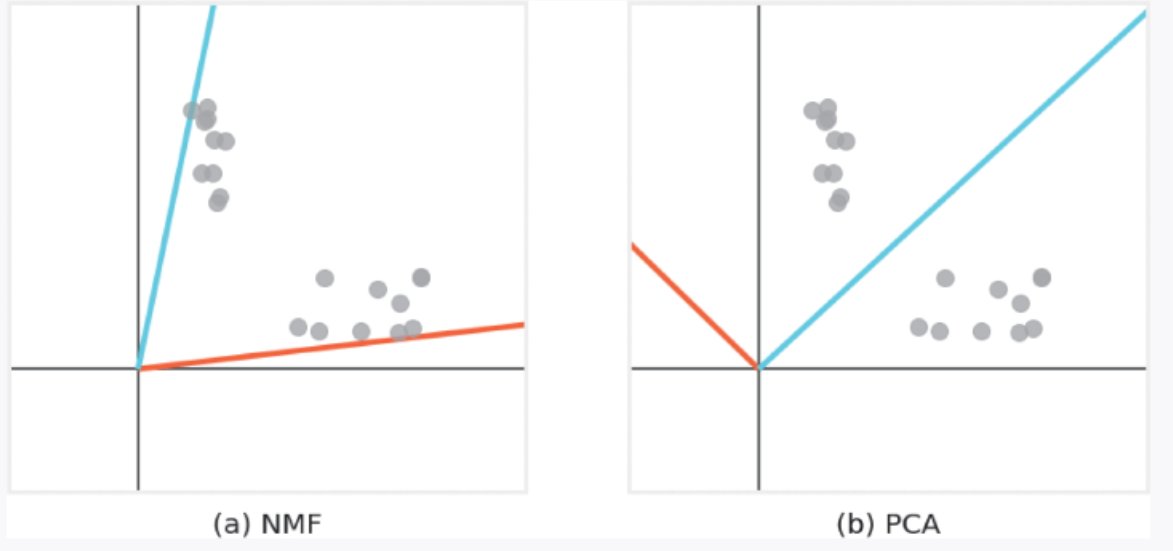
▲图 3-8 对二维数据分别应用 NMF 和 PCA 的结果
算法说明
NMF 作为一种矩阵分解方法,通过将原始数据分解为两个矩阵来降维(图 3-9)。设原始数据为 n 行 d列的矩阵 V,将其表示为两个矩阵 W 和 H 的乘积。W 是 n 行 r 列的矩阵,W 是 r 行 d 列的矩阵, WH 是原始矩阵 V 的近似,选择比 d 小的 r 就可以进行降维。这时,W 的每一行都是对 V 的每一行降维后的结果。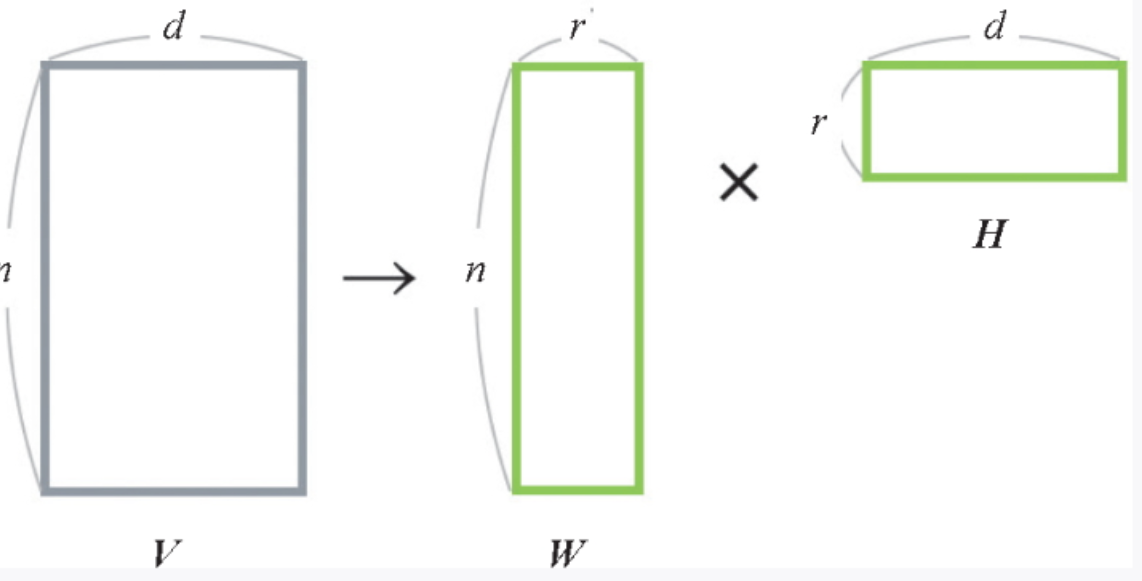
▲图 3-9 对 n 行 d 列的 V 进行矩阵分解的示意图(在降维到 r 个特征时,使用 W)
在求 W 和 H 的过程中,NMF 在 ![]() 的条件下,使 WH 接近 V。
的条件下,使 WH 接近 V。
NMF 采取“将 H 视为常数,更新 W” “将 W 视为常数,更新 H” 的方式交替更新 W 和 H。
下面对 NMF 计算过程中的每一步进行可视化。
灰色的点为原始矩阵 V,绿色的点为近似矩阵 WH。随着计算的进行,我们可以看到近似矩阵越来越接近原始矩阵。此外,红线和蓝线是潜在空间的轴,所有近似矩阵的图形都能在潜在空间(二维空间)的轴上表示出来(图 3-10)。
- 将 W 和 H 初始化为正值。
- 将 W 视为常数,更新 H。
- 将 H 视为常数,更新 W。
- 当 W 和 H 收敛时,停止计算。
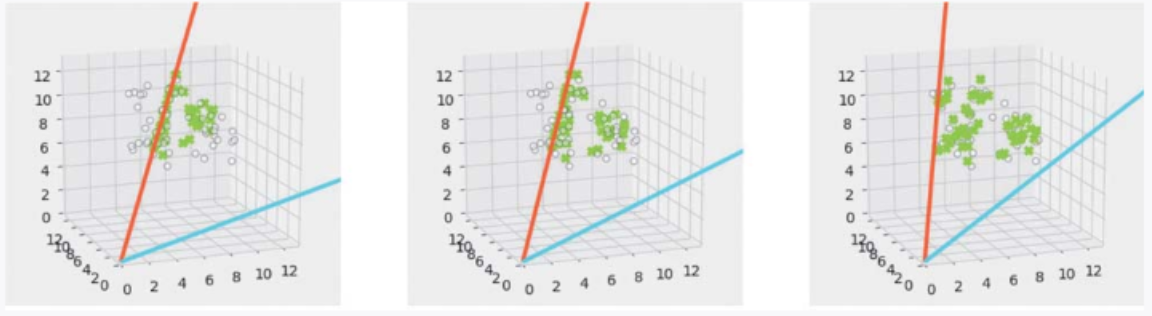
▲图 3-10 对三维数据应用 NMF 时参数更新的示意图
示例代码
下面是使用 scikit-learn 运行 NMF 算法的示例代码。
# NMF代表非负矩阵分解(Non-Negative Matrix Factorization),它是一种用于降维、源分离或主题提取等任务的方法[1]。NMF通过找到两个非负矩阵(W和H)的乘积来近似表示一个非负矩阵X。在NMF中,W被称为“字典”,H被称为“组件矩阵”[1]。
from sklearn.decomposition import NMF
# make_blobs模块用于生成具有指定特征和中心的随机数据集[2]。在这个例子中,使用make_blobs生成了一个包含4个簇的随机数据集,每个簇的数据点服从正态分布。
from sklearn.datasets import make_blobs
# 每个子列表中的三个数字分别代表一个数据点在三个维度上的坐标。
centers = [[5, 10, 5], [10, 4, 10], [6, 8, 8]]
# 使用make_blobs函数生成一个数据集。centers参数指定了数据集的中心点,V是生成的数据集。
V, _ = make_blobs(centers=centers)
# 表示我们希望将数据集分解成的成分数量。
n_components = 2
model = NMF(n_components=n_components)
model.fit(V) # 使用NMF模型对数据集进行拟合,即学习数据集的成分。
# 使用拟合后的模型对数据集进行转换,得到数据集在新的表示空间中的表示。
W = model.transform(V)
# 获取NMF模型的成分矩阵。
H = model.components_
print(W)
print("****************************************")
print(H)结果:
[0.664726 0.5614122 ] [0.11634004 1.20914268] [0.36125835 1.10819665] [0.16482784 1.05033326] ~略~ [0.81497999 0. ] [0.5262973 0.71158678]] **************************************** [[ 3.61350932 12.26164153 5.01605527] [ 8.05079602 1.42453523 8.43322906]]
详细说明
NMF 和 PCA 的比较
现在我们已经了解了 NMF 算法,下面尝试将 NMF 应用到一个具体的数据集上。使用的数据是人脸图像数据(19 像素×19 像素,2429 张),图 3-11 是其中一张图像。为了进行比较,我们同时使用 PCA 进行降维。不管使用哪种算法,都假定降维后由 49 个变量表示数据。由于原始图像数据有 361 个特征(= 19 像素×19 像素),所以我们的任务是将 361 个特征变换为 49 个潜在变量。
▲图 3-11 人脸图像
不管是 PCA 还是 NMF,潜在变量都是根据原始特征计算出来的,所以每个潜在变量与 361 个原始特征有关(该特征在 NMF 算法中是矩阵 H 的某一行)。将 49 个潜在变量的这种关系可视化,得到图 3-12 和图 3-13。在可视化时,为了便于查看,我们使用每个变量的最小值和最大值进行了缩放。在恢复原始图像时,我们使用变换后的数据点(NMF 中矩阵 W 的某一行)和可视化数据的乘积(图 3-14)。这相当于计算 1 行 49 列的矩阵和 49 行 361 列矩阵的乘积,得到 1 行 361 列的矩阵。
▲图 3-12 对人脸图像应用 PCA 的结果
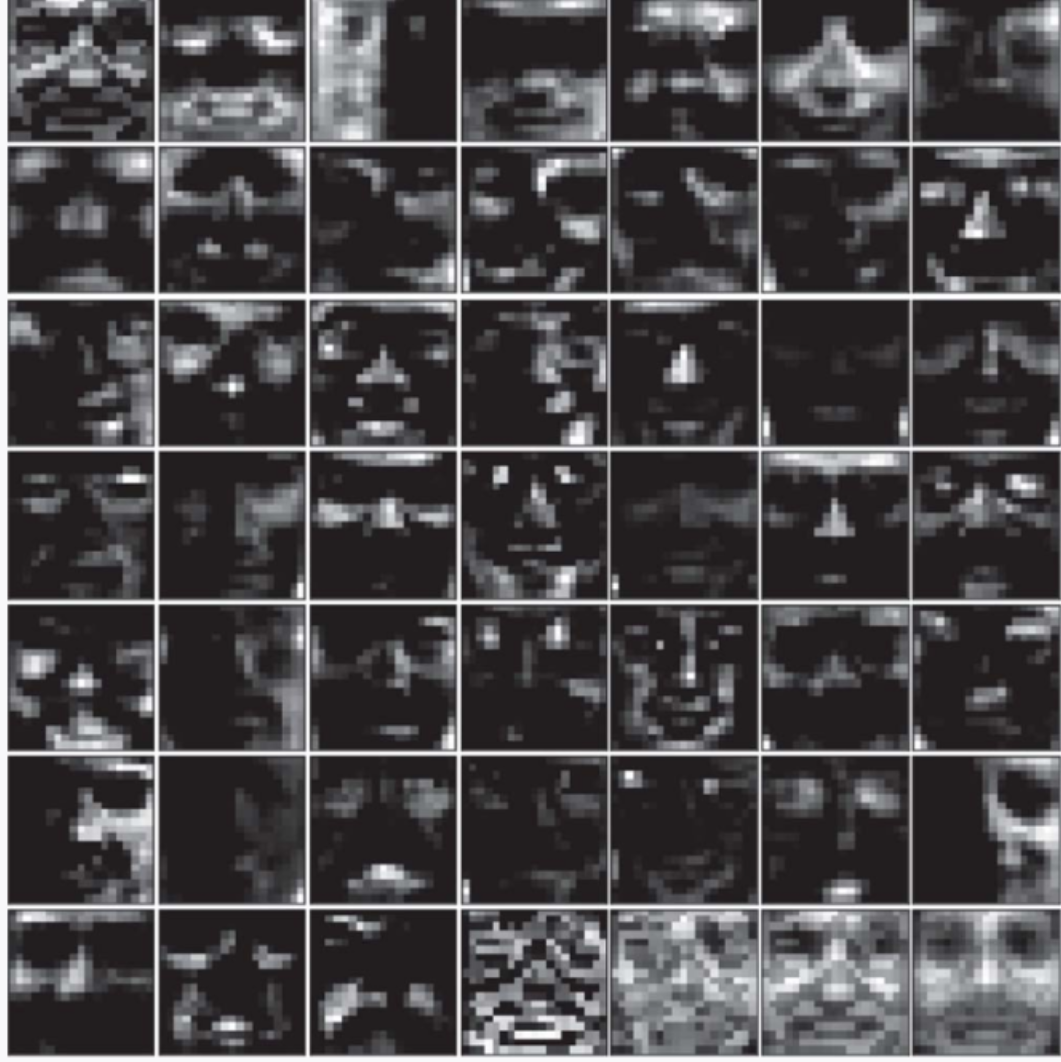
▲图 3-13 对人脸图像应用 NMF 的结果
▲图 3-14 根据降维数据恢复图像的结果
图 3-12 是 PCA 的结果,图像中负值看起来暗,正值看起来亮。图像从左上角开始按特征贡献度从高到低的顺序排列。可以看出,每张图像都表示了人的整个面部。图 3-13 是 NMF 的结果,图像中暗的区域较多,但这些区域的值为 0。我们还可以看出,每个潜在变量都代表了人脸的一部分特征。通过还原原始图像,可以明确两种方法的不同特点。PCA 通过将不同的脸(负的脸和正的脸。听上去是不是有些奇怪?)加在一起来恢复原始图像。NMF 则通过组合具有人脸部分特征的图像来恢复原始图像。NMF 的潜在变量的含义(在本例中就是人脸的部分特征)的可解释性更强。
———————————————————————————————————————————
文章来源:书籍《图解机器学习算法》
作者:秋庭伸也 杉山阿圣 寺田学
出版社:人民邮电出版社
ISBN:9787115563569
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《图解机器学习算法》的内容旨在分享知识和启发思考,尊重原著作者秋庭伸也 杉山阿圣 寺田学的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









