







如标题,这篇博文只是我按照github上无私的大神开源代码后,然后我在自己的环境下复现出来的实践笔记,全当自己记录踩过的坑...
paper : Detecting Oriented Text in Natural Images by Linking Segments
github地址:https://github.com/dengdan/seglink
paper实现把文本行框出来,并没有进行识别... 以下开始操作:...
1. 首先把model之类的下载好,按照大神给好的说明放到自己本地对应的位置。
2.

然后是这一步,我当时还卡了一会不知道怎么操作,可以看这里:点击打开链接
3. 然后是测试自己的图片,给出的命令说明是这样的:
./scripts/test.sh 0 ~/models/seglink/model.ckpt-217867 ~/dataset/ICDAR2015/Challenge4/ch4_training_images但其实,我们是需要在最前面再加上:sh 的...
sh ./scripts/test.sh 0 ~/modelpath.../model.ckpt-xxx /testimgpath.../然后,我遇到的问题是:points = cv2.cv.BoxPoints(bbox)这里。

这是因为opencv的版本不同问题。我的环境是3,大神开源的是2。不用急着立马去配一个2,我百度试了试这一句,改成对应3版本的形式:points = cv2.boxPoints(bbox)
然后再sh test.sh文件,通过了.. 哈哈还好只有这一个地方冲突的...
然后就生成了识别图像中的文档的坐标信息,如下:
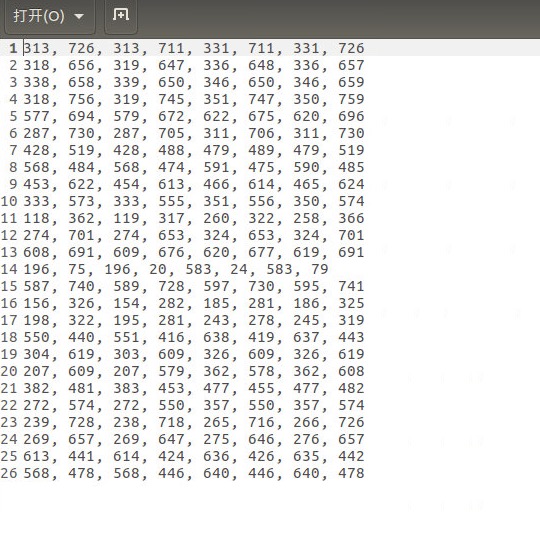
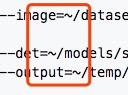
4. 可视化结果:按照大神的说明,改成自己的路径即可:
python visualize_detection_result.py \
--image=~/dataset/ICDAR2015/Challenge4/ch4_training_images/ \
--det=~/models/seglink/seglink_icdar2015_without_ignored/eval/icdar2015_train/model.ckpt-72885/seg_link_conf_th_0.900000_0.700000/txt \
--output=~/temp/no-use/seglink_result_512_train这里唯一注意的就是每一行的等号之间不要自己去加空格哈...
以上操作就完成test过程了,放一张result img:

识别结果还是蛮好的,但是比如上图蓝色框出的部分,没有正确识别完整的文本行。可能是字符之间的间隔太大,以及弯曲的文本行不太好识别吧~...
关于train自己的数据的实践,会继续补充...















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









