







引言
智能问答系统广泛用于回答人们以自然语言形式提出的问题,经典应用场景包括:智能语音交互、在线客服、知识获取、情感类聊天等。根据QA任务,可以将QA大致分为5大类,分别为:
文本问答(text-based QA,TBQA)
知识库问答(Knowledge Base Question Answering,KBQA),
社区问答(Community Question Answering,CQA)
表格问答(Table Question Answering,TQA),
视觉问答(Visual Question Answering,VQA)
下面分别从任务(回答是什么),方法(回答怎么做,只梳理deeplearning部分,传统算法略过),示例工程(实操或者在线体验),结论(个人思考与衡量)4方面展开。
文本问答(text-based QA,TBQA)
一:任务
基于给定文本,生成问题对应的答案,也可叫机器阅读理解(MRC)。
处理流程:
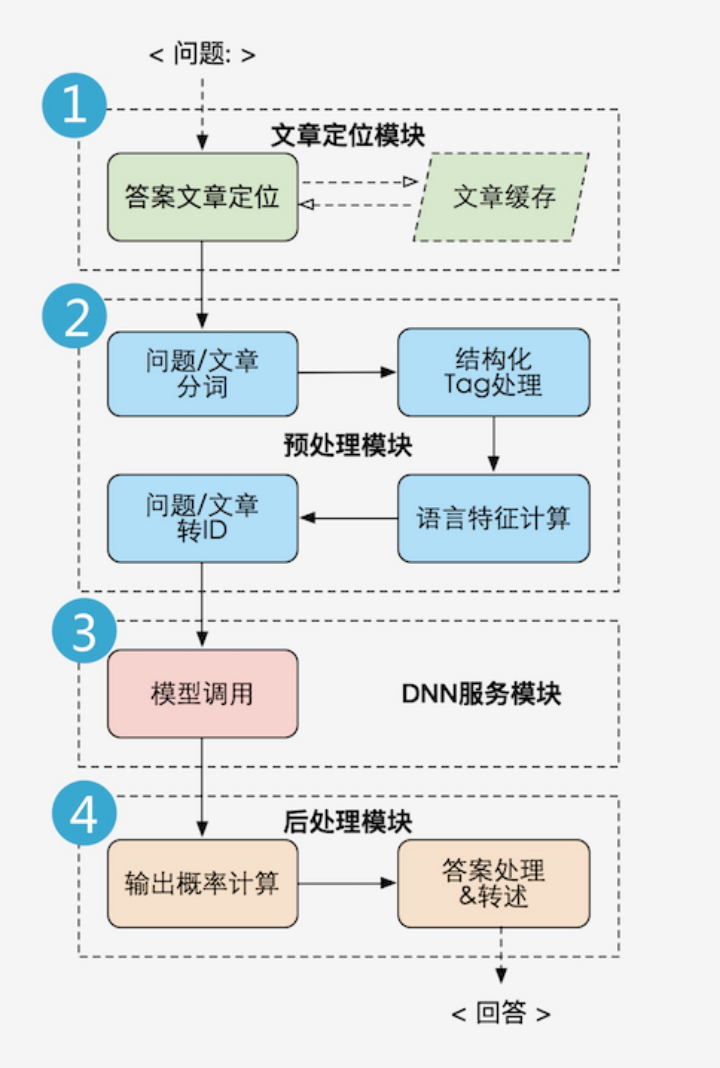
1)文章定位模块
文本读取
根据用户问题,借助文本分类,检索等算法获取概率较大的段落集合
2)预处理模块
句子向量化,格式归一,特征计算等
3)DNN服务模块
加载深度学习模型,预测答案得分
4)后处理模块
基于动态规划选取最佳答案输出
根据任务的不同,可分为以下几种情况:
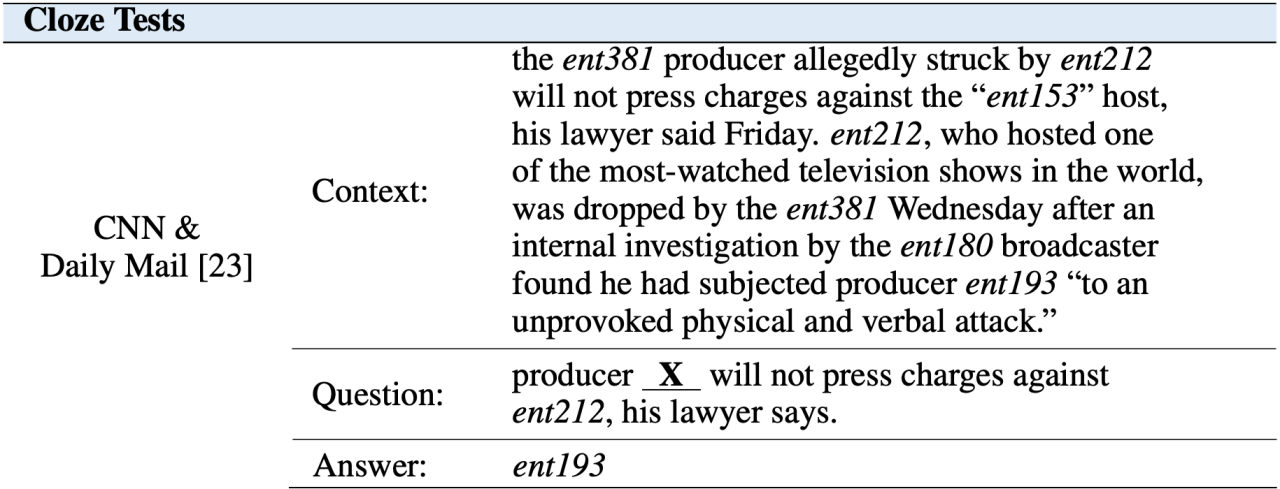
答案填空,类似完形填空。
给定文本内容,预测问题中缺失的单词或短语。这类问题的数据集形态,大多是【背景,问题,答案】三元组,比如:
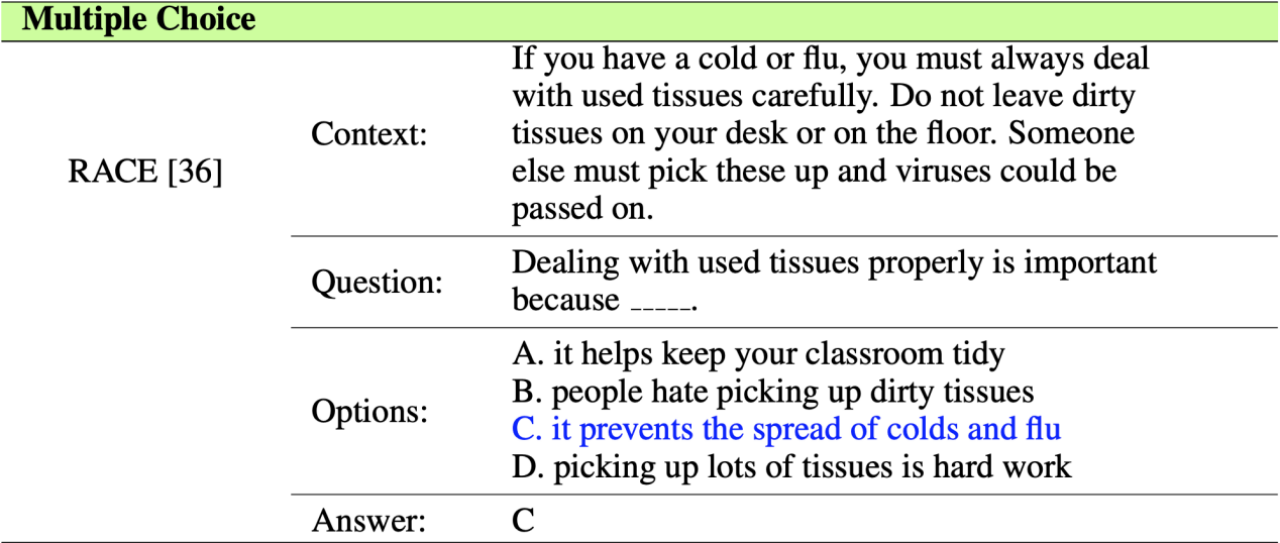
答案选择,类似做选择题。
给定文本内容,并给定问题对应的若干答案候选,对这些答案候选进行排序并选出可能性最大的答案候选.这类问题的数据集,通常是英语考试阅读理解,比如:
3)答案抽取,片段抽取。
根据给定的问题从文本中抽取答案。这里的答案可能是文本中的任意片段。这类问题的数据集形态大多数为【原文,问题,答案】三元组。

答案摘要,自由问答。
根据给定问题和文本,生成一段可以回答问题的摘要,这里的答案片段可能并没有出现在对应的文本中。这类问题的数据集形态大多数为: ID 文本 ID 文本 ID 问题 [标签] 答案 [标签]

基于知识的机器阅读理解(Knowledge-Based MRC)
需要借助外部知识才能获取到的答案。这里问题的数据集形态通常为:一个领域若干条文本概述,围绕给出的文本进行对话问答,对话比较短,通常只有一两对对话。比如:

不可答问题的机器阅读理解(MRC with Unanswerable Questions)
根据上下文以及外部知识也无法获得的答案。

对话型问题回答(Conversational Question Answering)
给定一个问答,A提问题,B回复答案,然后A根据答案继续提问题。这个方式有点类似多轮对话。

总之,不管哪一种任务,都是需要阅读和理解给定的文本段落,然后根据其回答问题。
二:方法
基于预训练模型的方法
(1)近年来NLP领域通过大量通用领域数据进行训练,诞生了一批如ELMO、GPT、BERT、ENRIE等优秀的预训练语言模型。在具体的阅读理解任务时,可以通过进行领域微调、数据微调、任务微调,来把学到的句子特征信息应用到具体的任务。(BERT:结合 GPT 与 ELMO 的优势, 引入 Transformer 编码模型, 采用双向的语言模型, 训练时增加了掩码语言模型以及判 断 句 子 顺 序 的 任 务 , 可 以 获 取 更 多 的 语 言 表 征 )
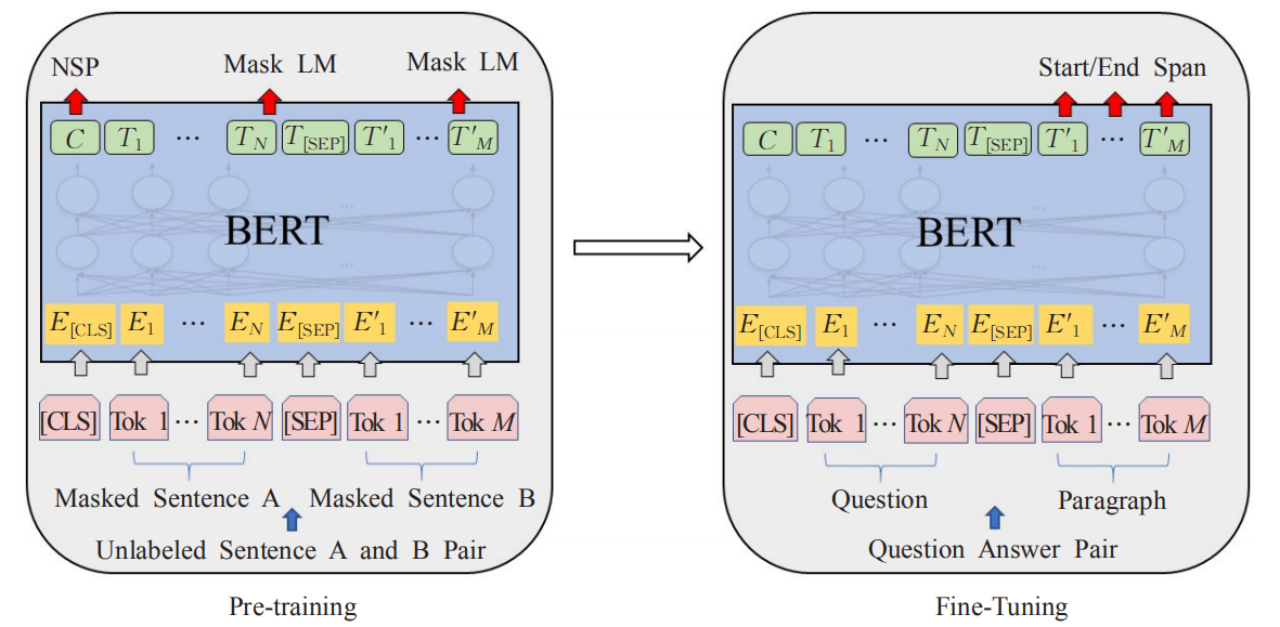
query和context concat后输入bert中获取每个token的向量表示,输入形式: CLS “query” SEP context ,经过BERT训练,找到需要抽取的span.
(2)基于知识增强的对比提示调整框架(KECP)是一种小样本学习算法,采用Prompt-Tuning作为基础学习范式,在仅需要标注极少训练数据的情况下,在给定文章中抽取满足要求的文本作为答案。
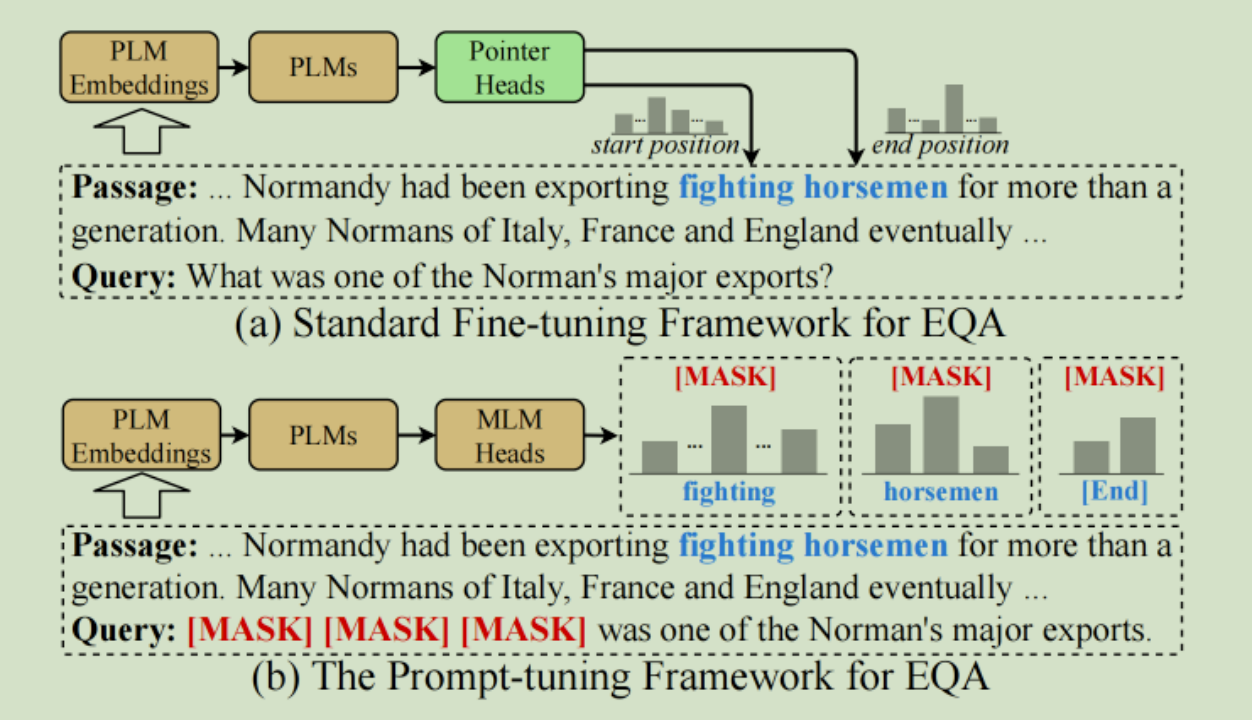

三:示例工程
1:easyNLP
工程地址:https://github.com/alibaba/EasyNLP
工程描述:收藏 1.4K,clone 179,并且一直有人维护,几小时前还有更新,是阿里云团队曾经被顶会EMNLP2022收录的工程。
论文:KECP: Knowledge-Enhanced Contrastive Prompting for Few-shot Extractive Question Answering https://arxiv.org/abs/2205.03071
讲解:算法 KECP 被顶会 EMNLP 收录,极少训练数据就能实现机器阅读理解
https://zhuanlan.zhihu.com/p/590024650
2:DuReader
工程地址:https://github.com/baidu/DuReader/tree/master/DuReader-2.0
工程收藏 998,clone 312,是百度团队曾经被顶会ACL2022收录的工程。但是这是一种开放域问答系统,数据集形态复杂,数据集噪声多,需要的数据量较大。
论文:DuReadervis: A Chinese Dataset for Open-domain Document Visual Question Answering https://aclanthology.org/2022.findings-acl.105/
讲解:ACL2022 | 面向中文真实搜索场景的开放域文档视觉问答数据集
https://blog.csdn.net/qq_27590277/article/details/125326071
该工程已经落地应用与汽车行业:《汽车说明书跨模态智能问答》
地址:https://aistudio.baidu.com/aistudio/projectdetail/4049663
四.结论
机器阅读理解问答(MRCQA)是一种给出文章,然后根据文章提问并解答作为标签,去训练。在训练过程中,
首先,为了获得更准确的与问题相关的词与句子,很多Attention机制被提出,这块是很值得研究的一个点。
其次,从任务细分的几种情况来看,大多是的MRC解决方案都是从原文档中匹配检索答案,这其实与人的阅读理解不一样的(人或多或少会用上先验知识),所以,如何使得模型获得先验知识也是我们值得研究的地方。
切入到我们目前实际的问答任务,个人认为:
数据集形态的确定,我们借鉴kecp,输入不是常规的Q+P,而是Qprompt +P,这里的Qprompt
相对于Q,已经可以看作是在数据层面做了Attention。
知识图谱问答(Knowledge Base Question Answering,KBQA)
一:任务
知识图谱(Knowledge Base / Knowledge Graph)中包括三类元素:实体(entity)、关系(relation),以及属性(literal)。实体代表一些人或事物,关系用于连接两个实体,表征它们之间的一些联系。KBQA,就是将问题解析、转换成在知识图谱中的查询,查询得到结果之后进行筛选、翻译成答案输出。
应用场景:多应用于结构化数据场景,比如电商,医药等,最具有代表性的知识图谱问答系统是各种搜索引擎,比如百度,谷歌等。
下面是一个简单的例子:
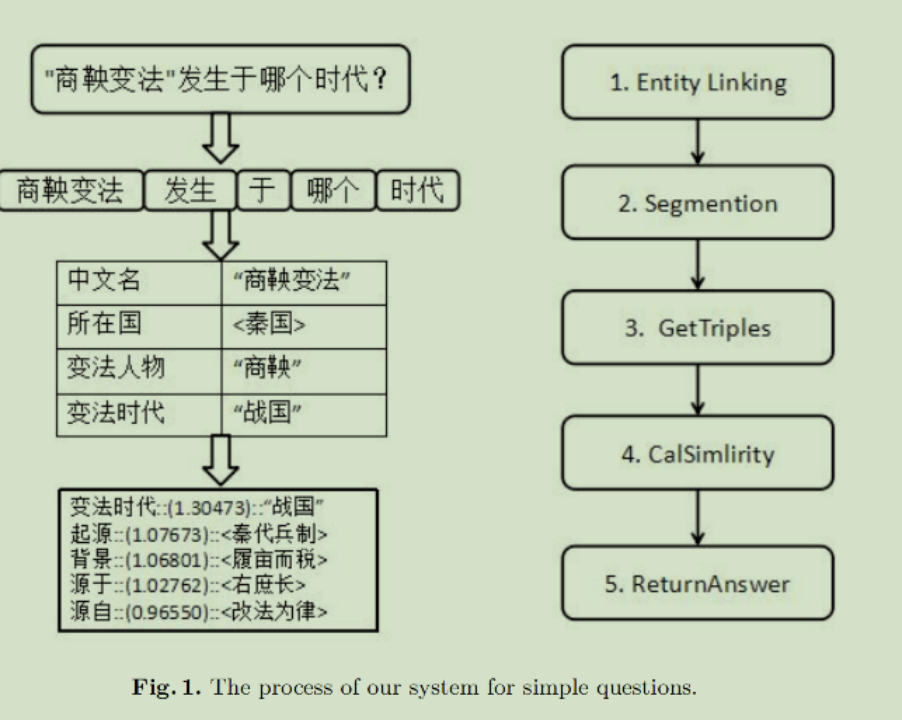
问题:”商鞅变法”发生在哪个朝代?
知识图谱问答系统分5步得出答案:
1:确定问题中提到的实体;2:将问题的其他部分分段;3:通过web接口获取包含该实体的所有三元组;4,计算“关系”和分割词之间的相似度,5:基于相似性结果对那些三元组进行排序以返回正确答案;
二:方法
1:知识图谱的构建
What:KBQA,首先在知识图谱的构建,也就是数据集构建上,是非常重要的过程。根据不同领域,构建不同领域的知识图谱,比如阿里巴巴商品知识图谱,zego元宇宙知识图谱等,数据集构建好之后,为其增加一个 QA 系统,就成了一个能解答XX相关问题的机器人。
How: (1)可以通过Neo4j简单构建自己的知识图谱数据集
具体实操过程,可参考:https://blog.csdn.net/jesseyule/article/details/110453709
(2)通过OpenNRE构建
实操参考:http://pelhans.com/2019/01/04/kg_from_0_note9/
ccks2019_sample subset:结构化三元组形态,是目前应用最广的。

2:所提问题到图谱查询的转化
这一步可以通过语义分析,从而构建这个问题的图谱查询,得到答案;也可以基于信息抽取,从问题中抽取实体,再去已有的知识图谱中匹配问题,最后排序选择结果。
这里有一篇美团知识图谱问答解析:https://tech.meituan.com/2021/11/03/knowledge-based-question-answering-in-meituan.html
三:示例工程
一:NBA 相关问题的问答系统:https://github.com/wey-gu/nebula-siwi/
二:KBQA-BERT
工程地址:https://github.com/WenRichard/KBQA-BERT
工程收藏 1.3K,clone 342,最近更新在4年前,用bert做文档特征提取与句子相似度计算。比较老的方法。
三:基于医药知识图谱的智能问答系统QASystemOnMedicalKG
工程地址:https://github.com/liuhuanyong/QASystemOnMedicalKG
工程收藏 4.7K,clone 1.8K,最近更新在3年前。类似的,还有基于犯罪知识图谱的智能问答系统,基于军事知识图谱的智能问答系统等,这些比较冷门,工程热度较低。
四:haystack
工程地址:https://github.com/deepset-ai/haystack
工程收藏 6.9K,clone 1K,并且一直有人维护,几小时前还有更新,实现基于文档的语义分析和问答,可以快速构建类似Chatgpt的问题答案,语义搜索,文本生成等,是一种端到端的框架。参考文档:https://docs.haystack.deepset.ai/docs/knowledge_graph
五:intelligent_question_answering_v2
工程地址:https://github.com/milvus-io/bootcamp/tree/master/solutions/nlp/question_answering_system
工程收藏 1.1K,clone 442,最近更新在3个月前。用Milvus做相似度计算和搜索,找到所问问题与数据集中相似问题,然后匹配相似问题的答案,fastAPI做交互式界面,搭建比较简单。
四 结论:
(1)KBQA与MRC相比,MRC的语料是一问一答式,容易获取,KBQA需要有结构化的知识库,获取比较难。
(2)KBQA流程是识别出问题的实体,然后构建图谱查询,而MRC需要理解一堆非结构化的语料,两者不管是在速率还是效率上,都是KBQA优于MRC。
(3)切入到我们目前实际的问答任务,个人认为:
①如果想算法快速落地,推荐使用MRC,因为其数据集容易获取且清洗。
②如果想追求响应时间快,准确率高,推荐使用KBQA,那构建我们自己的知识图谱尤为重要,后面模型出的答案是否准确,跟知识图谱有很大关系。
社区问答(Community Question Answering,CQA)
一:任务
技术点在于语义文本匹配问题,计算文本与文本之间的相似度和关联度的问题。根据任务划分,可以将CQA还分为:
1.FAQ
用户频繁会问到的业务知识类问题的自动解答。
https://github.com/Bennu-Li/ChineseNlpCorpus
例如法律文书匹配样例:

2.CQA
问答对来自于社区论坛中用户的提问和回答,较为容易获取,没有人工标注,相对质量较低。
二:方法
常用孪生网络,比较两个输入的相似度
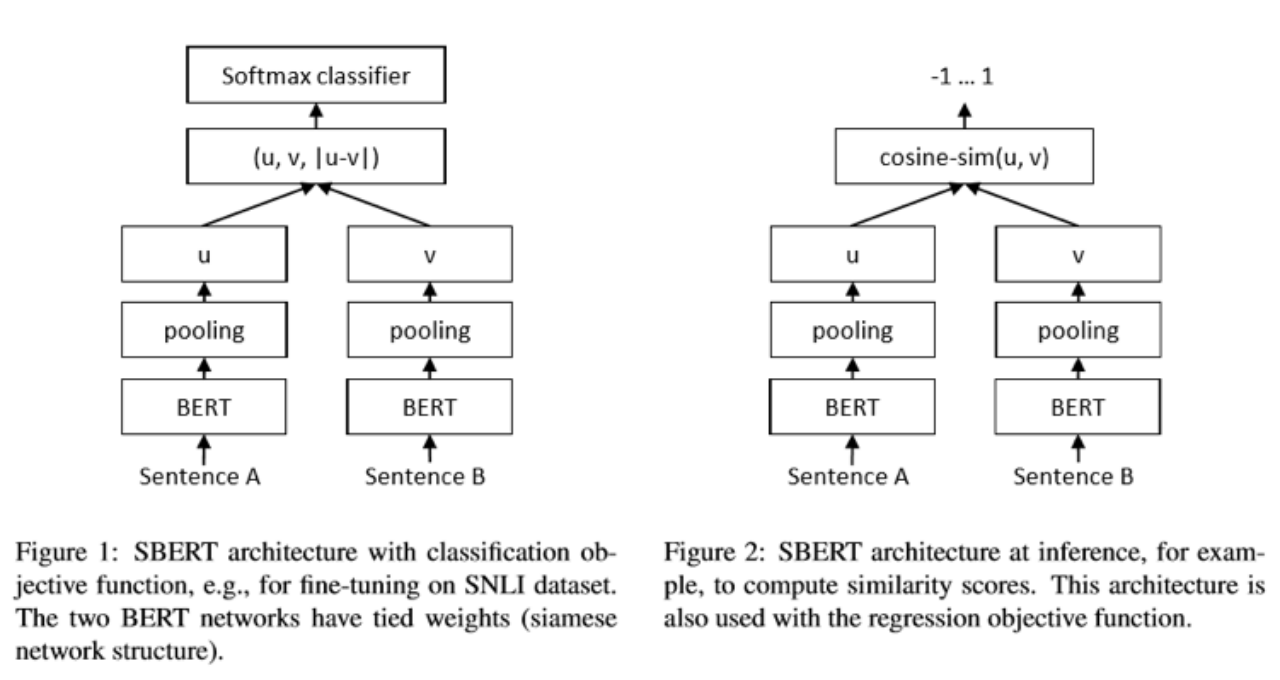
可以当分类任务,输出sentenceA 与sentenceB是否相似,也可以当回归任务,输出sentenceA 与sentenceB相似的程度。
四 结论:
CQA主要用于语义相似度匹配,比如医疗问答匹配,某某客服问题匹配,某某需求与成果匹配等,跟我们目前实际问答任务相关性较弱,没有过多调研。
表格问答(Table Question Answering,TQA)
一:任务:
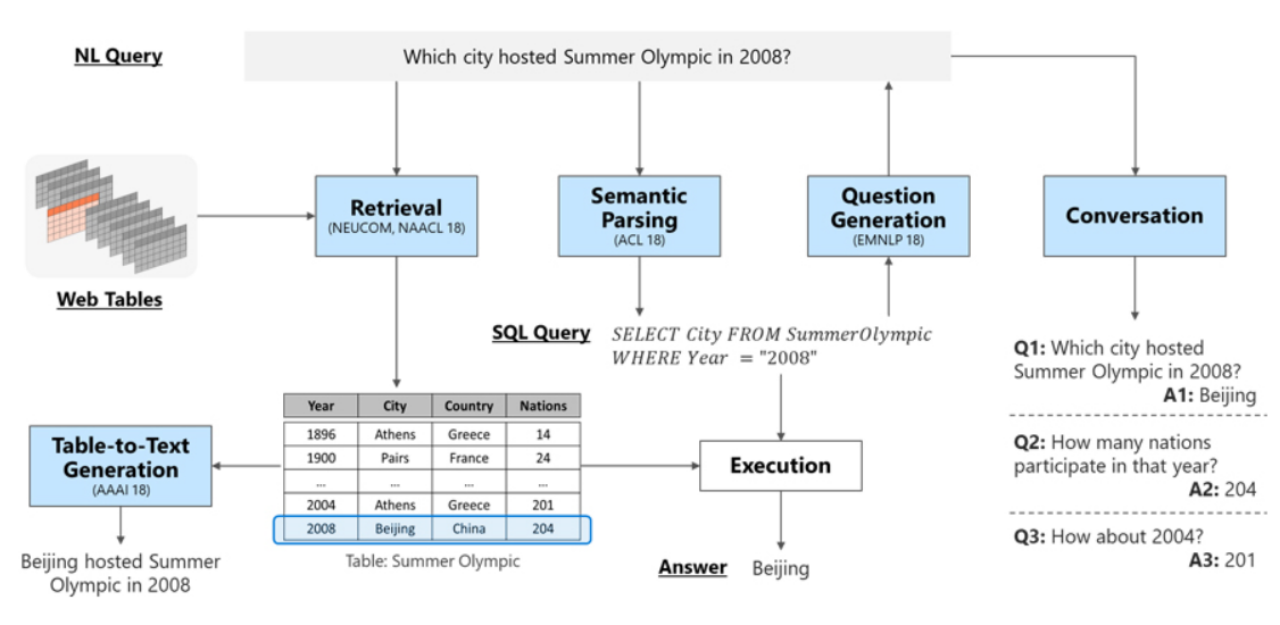
TQA任务流程分为以上5步,分别为:
(1)表格检索:从一堆表格中检索出跟问题相关性较大的表格
(2)语义解析:将非结构化的文本问题,转化为SQL语句
(3)问题生成:围绕上述语义解析,产生相关问题输出。同时对这些问题与所提问题做相似度排序。
(4)对话:对上述产生的问题进行解答。
(5)文本生成:将上述排列最考前的问题与答案,用自然语言描述出来,作为答案输出。
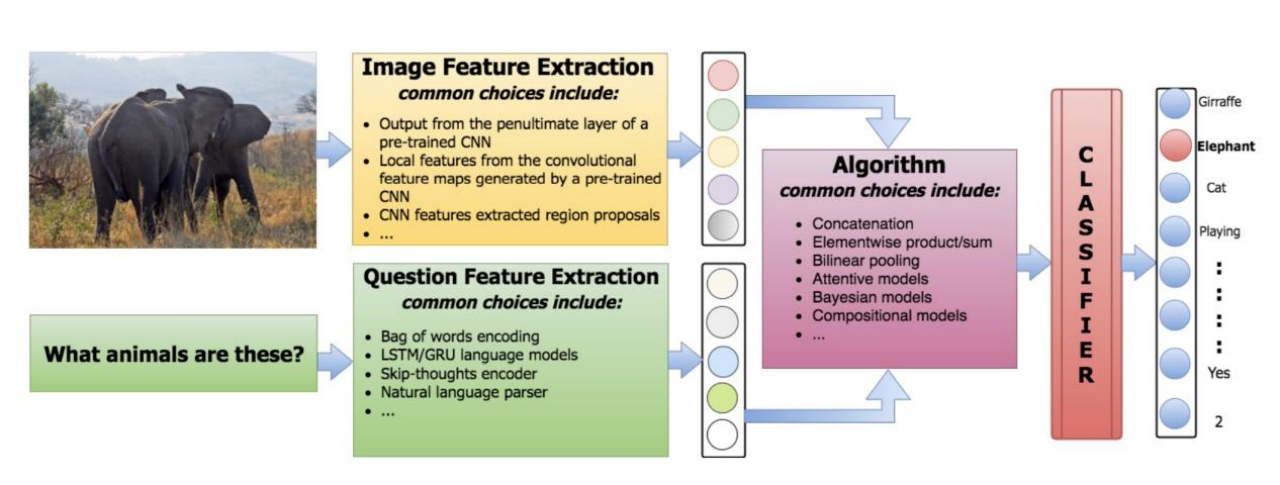
视觉问答(Visual Question Answering,VQA)
一:任务
VQA(Visual Question Answering)指的是,给机器一张图片和一个开放式的的自然语言问题,要求机器输出自然语言答案。这是目前比较新也比较火的方向。VQA细分,还可以分为图片问答,视频问答,图片文本问答,图表问答等。
三:示例工程
一:ERNIE-Layout:版面知识增强的文档理解预训练
1:论文地址:https://arxiv.org/pdf/2210.06155v2.pdf
2:工程地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
3:体验:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout
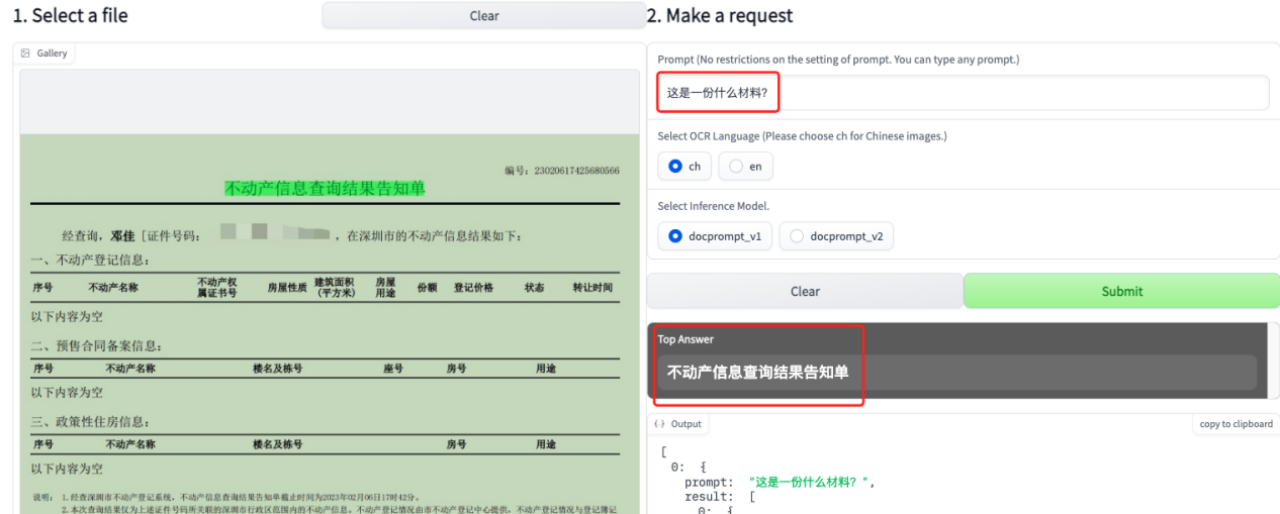
输入一张图片,再根据那张图片图片提问,eg:
问:这是一份什么材料?
系统自动答:不动产信息查询结果告知单
并且自动在上传的图上标出信息位置。
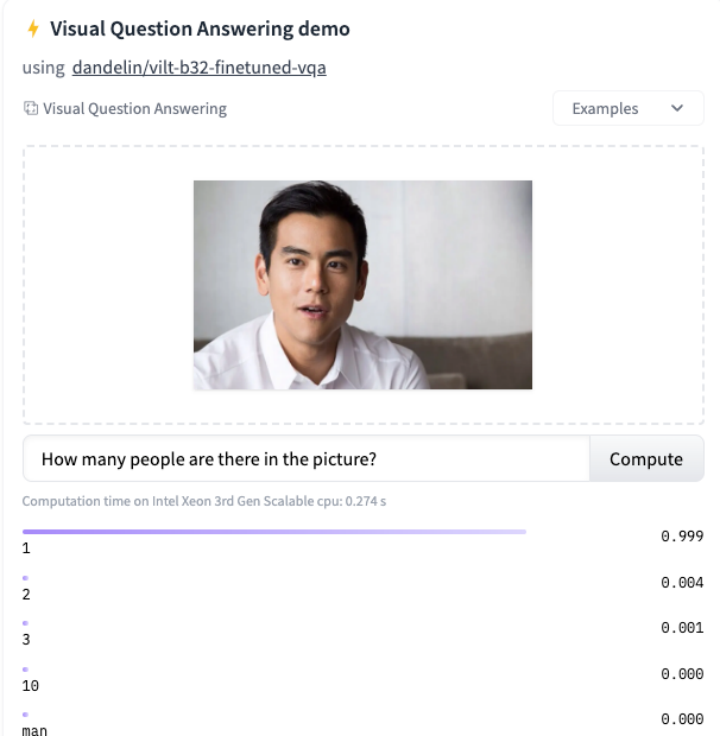
二:vilt
体验:https://huggingface.co/tasks/visual-question-answering
四 结论:
VQA语料是图片,跟我们目前实际问答任务相关性较弱,但是个人感觉这块的应用前景比较好,值得研究。

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









