







图论——二分图最大匹配与匈牙利算法
相关概念与术语
二分图:简单来说,如果图中点可以被分为两组,并且使得所有边都跨越组的边界,则这就是一个二分图。准确地说:把一个图的顶点划分为两个不相交集 U U U 和 V V V ,使得每一条边都分别连接 U U U 、 V V V 中的顶点。如果存在这样的划分,则此图为一个二分图。二分图的一个等价定义是: 不含有「含奇数条边的环」的图 。
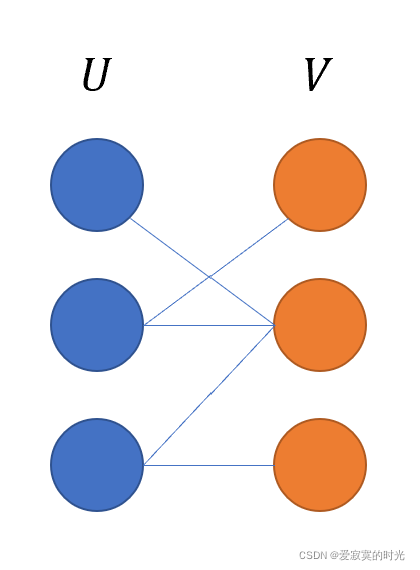
- 匹配:在图论中,一个 匹配 是一个边的集合,其中任意两条边都没有公共顶点。我们定义匹配点、匹配边、未匹配点、非匹配边,它们的含义非常显然。匹配点和匹配边就是已经有匹配边相连的点,其他都是未匹配点和非匹配边。
- 极大匹配:给出一个现有的匹配,如果在不修改现有匹配边的情况下,如果不能再增加匹配边,那么这个匹配就是一个 极大匹配 。
- 最大匹配:一个图所有极大匹配中,所含匹配边数最多的极大匹配,称为这个图的 最大匹配 。在最大匹配中,匹配边的数量称为这个图的 最大匹配数 。
- 完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个 完美匹配 。显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。
匈牙利算法
求解二分图最大匹配问题的一个最常用的算法是匈牙利算法。下面介绍匈牙利算法的原理和使用。
- 交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边…形成的路径叫 交替路 。
- 增广路:从一个未匹配点出发,走交替路,如果终点是另一个未匹配点(出发的点不算),则这条交替路称为 增广路 。并且增广路的长度一定是奇数,按照次序给增光路的边编号,那么奇数编号的边是未匹配边,偶数则是匹配边。
其中,增广路有一个重要特点: 非匹配边比匹配边多一条 。因此,研究增广路的意义是改进匹配。只要把增广路中的匹配边和非匹配边的身份交换即可。由于中间的匹配节点不存在其他相连的匹配边,所以这样做不会破坏已经存在的匹配的性质。交换后,图中的匹配边数目比原来多了 1 条。从这个角度分析,匈牙利算法也算作是一种贪心算法。
我们可以通过不停地找增广路来增加匹配中的匹配边和匹配点。找不到增广路时,达到最大匹配(这是增广路定理)。匈牙利算法正是这么做的,这也是算法的核心。
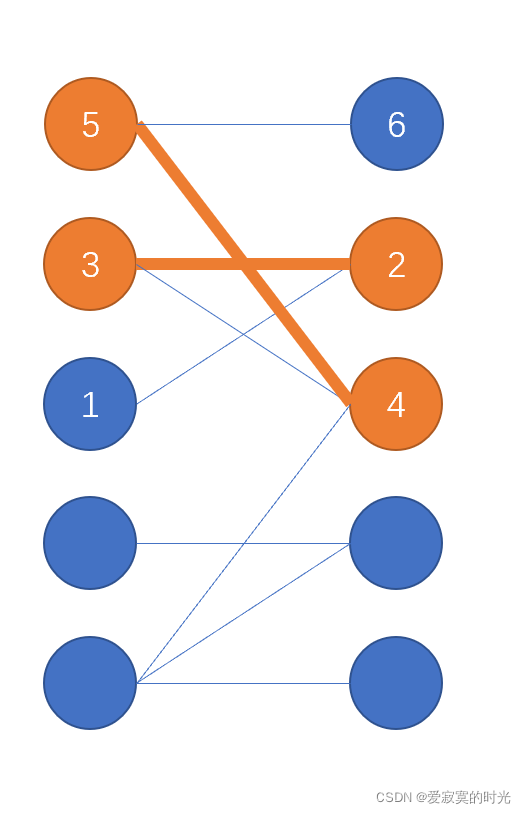
例如,对下图中,增广路 1 → 2 → 3 → 4 → 5 → 6 1 \to 2 \to 3 \to 4 \to 5 \to 6 1→2→3→4→5→6 中,可以反转匹配边和非匹配边,这样匹配边的数量就会增加一个,并且不会影响现有的匹配。
模板
主要思想:遍历左点集的每一个点,依次寻找增广路,如果存在增广路,那么就调整匹配。
寻找增广路的方式可以使用 BFS 和 DFS 寻找。
DFS
#include <bits/stdc++.h>
#define FR freopen("in.txt", "r", stdin)
using namespace std;
int n, m, t;
vector<int> graph[1005];
int match[1005];
int tag[1005];
bool dfs(int u, int t)
{
if (tag[u] == t)
return false; // 在一条增广路中,直接返回false
tag[u] = t; // 给节点打上路径标记
for (auto it = graph[u].begin(); it != graph[u].end(); it++)
{
int v = *it;
if (match[v] == 0 || dfs(match[v], t)) // 如果v节点没有匹配,或者v节点的原配存在增广路(假设原配还没有匹配)
{
// 翻转路径
match[v] = u;
return true;
}
}
return false;
}
int main()
{
FR;
cin >> n >> m >> t;
while (t--)
{
int u, v;
cin >> u >> v;
graph[u].push_back(v);
}
int cnt = 0;
for (int i = 1; i <= n; i++)
{
if (dfs(i,i))
{
// 如果存在增广路,那么调整之后匹配数必多一个
cnt++;
}
}
cout << cnt;
return 0;
}
例题
[ZJOI2007] 矩阵游戏
我们将行号作为 U U U 列节点,将列号 V V V 列节点,那么根据初始情况,如果存在 ( x , y ) (x,y) (x,y) 中是黑色点,那么在图中连接一条 ( x , y ) (x,y) (x,y) 的边。对于行列交换来说,并不会修改图的拓扑结构,因此如果图中存在完美匹配,那么一定存在满足要求的行列交换方案。

















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









