







主要参考https://www.cnblogs.com/pinard/p/6251584.html,
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
奇异值分解(Singular Value Decomposition,SVD),用于降维算法的特征分解、推荐系统、NLP等
1.特征值和特征向量
方阵A:n×n
特征向量x:1×n—— w1,w2,...,wn w 1 , w 2 , . . . , w n
特征值: λ λ —— λ1≤λ2≤...≤λn λ 1 ≤ λ 2 ≤ . . . ≤ λ n
W:n×n,上述特征向量集合
Σ Σ :n×n,主对角线为n个特征值的对角矩阵
标准化得 ‖wi‖2=1 ‖ w i ‖ 2 = 1 ,则 wTiwi=1 w i T w i = 1 ,则 WTW=I W T W = I ,则 WT=W−1 W T = W − 1 ,则W为酉矩阵
补充:取topK个特征值对应的特征向量即可实现降维,特征值表示特征的重要性
限制:A必须为方阵
2.奇异值分解SVD
特点:不要求分解的矩阵为方阵
待分解矩阵A:m×n
U:m×m,由左奇异向量组成
Σ Σ :m×n,主对角线为奇异值,其他为0
V:n×n,由右奇异向量组成
U和V均为酉矩阵,即 UTU=I,VTV=I U T U = I , V T V = I
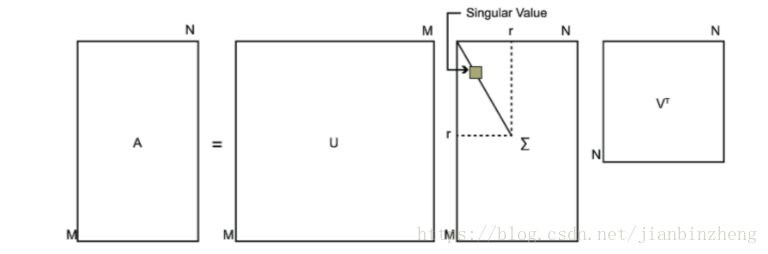
求解上述三个矩阵:
用n×n的方阵 ATA A T A 做特征值分解,得到n个特征值和特征向量v,作为右奇异向量,得到右侧的V矩阵;
用m×m的方阵 AAT A A T 做特征值分解,得到n个特征值和特征向量u,作为左奇异向量,得到左侧的U矩阵;
求解奇异值:
另外:
则 ATA A T A 的特征向量组成V,同理 AAT A A T 的特征向量组成U。且特征值是奇异值的平方,即
3.例子


4.性质
奇异值和特征值类似,且奇异值减少很快,“在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。”。所以可以用topK个奇异值近似描述矩阵
则实现用三个小矩阵近似描述大矩阵A,如灰色部分
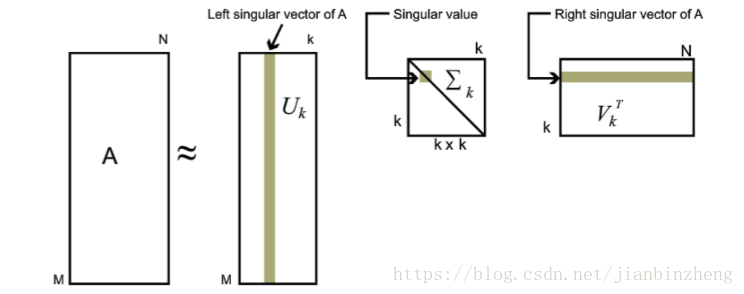
如:在PCA中,需要先计算样本协方差矩阵 XTX X T X ,再计算最大的d个特征向量,样本数和特征数多的时候计算量很大。一些SVD实现算法不需要先求出协方差矩阵 XTX X T X 也可以求出右奇异矩阵,sklearn就是使用SVD。另外,左奇异矩阵可以用于行数的压缩
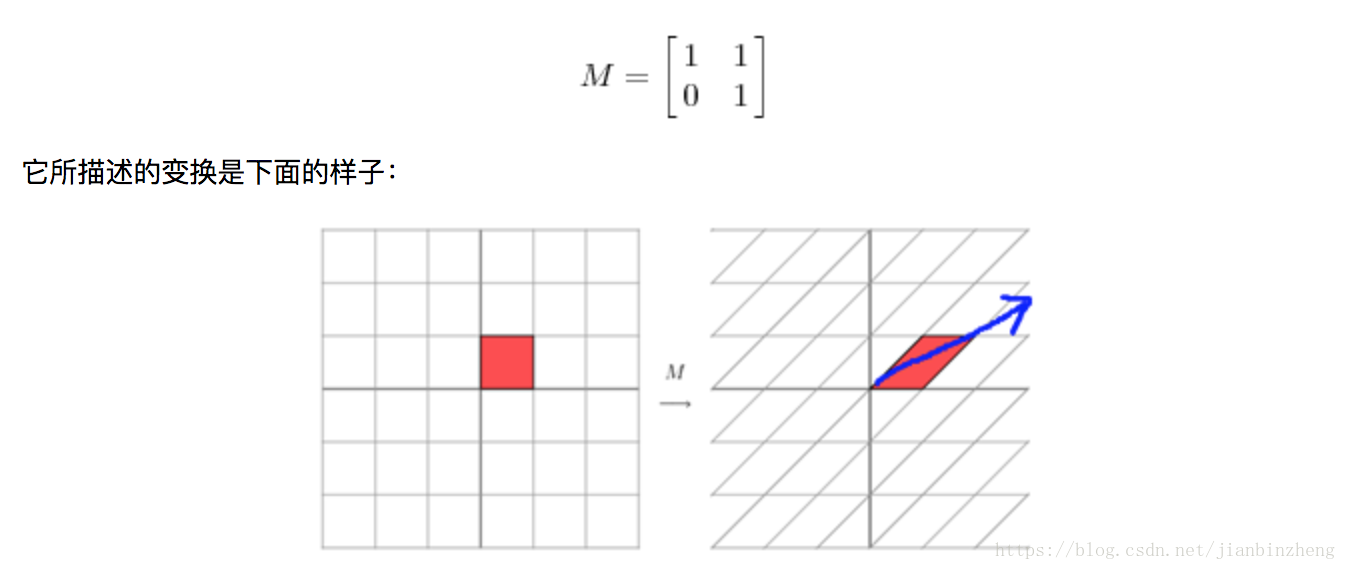
按照参考2的解释,矩阵乘法就是线性变换的过程,特征值大小反映了变换方向的重要性















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









