







Clip算子的broad_cast_type类型为BcastType::UNKNOWN_BCAST_TYPE.所以会调用到
fallback::ElemwiseImpl::exec(srcs, dst); 然后因为
srcs.size() > 2,就调用到:
naive::ElemwiseForwardImpl::exec(srcs, dst);
先看下调用堆栈图:
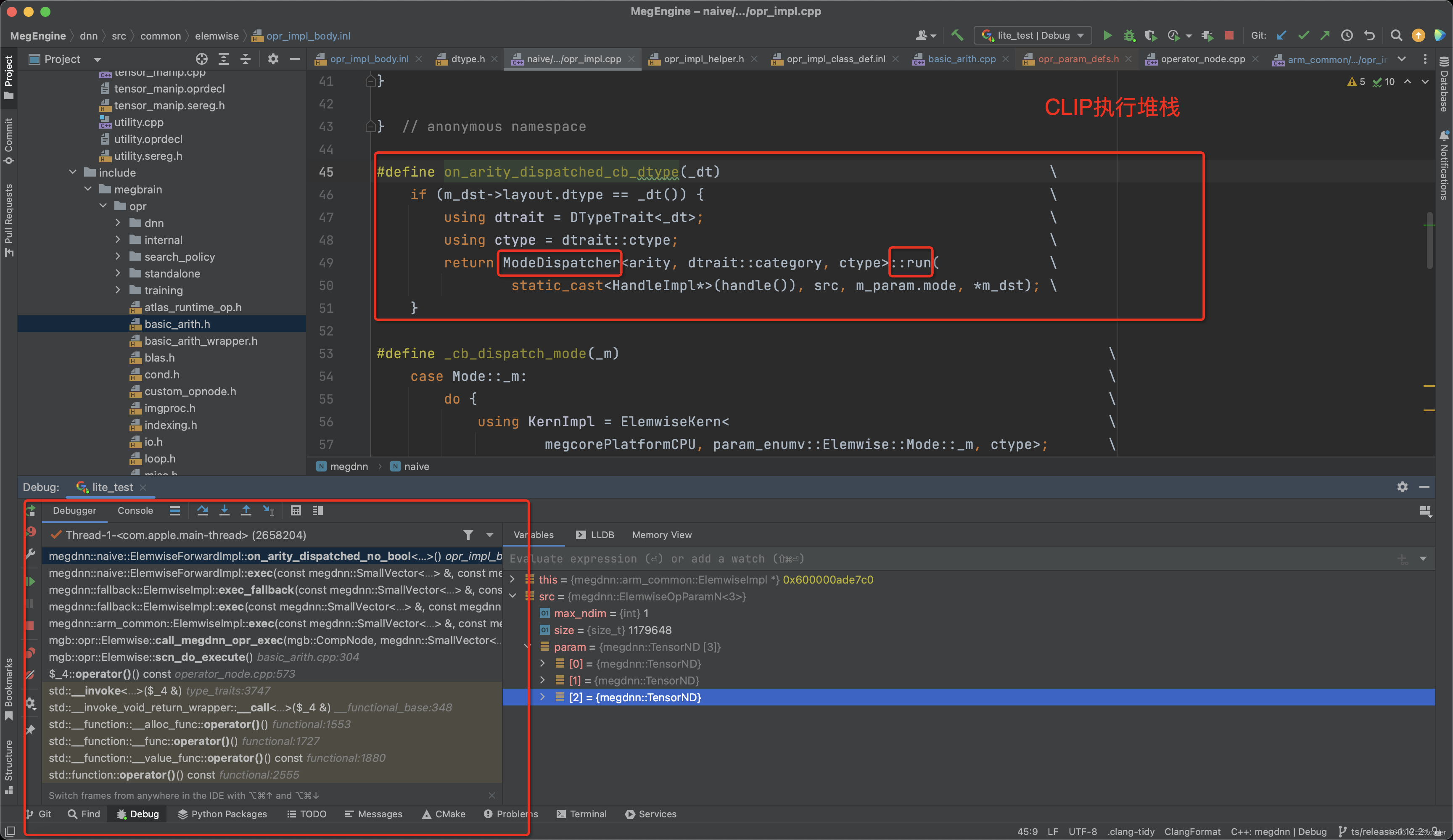
Elemwise类首先定义算子执行分配器ModeDispatcher, 通过on_arity_dispatched_cb_dtype 进行调用,实际上由方法ElemwiseForwardImpl::on_arity_dispatched和ElemwiseForwardImpl::on_arity_dispatched_no_bool 调用。
#define on_arity_dispatched_cb_dtype(_dt) \
if (m_dst->layout.dtype == _dt()) { \
using dtrait = DTypeTrait<_dt>; \
using ctype = dtrait::ctype; \
return ModeDispatcher<arity, dtrait::category, ctype>::run( \
static_cast<HandleImpl*>(handle()), src, m_param.mode, *m_dst); \
}
template <int arity>
void ElemwiseForwardImpl::on_arity_dispatched() {
printf("********************** on_arity_dispatched\n");
auto src = make_elemwise_op_param<arity>();
MEGDNN_FOREACH_COMPUTING_DTYPE_FLOAT(on_arity_dispatched_cb_dtype)
MEGDNN_FOREACH_COMPUTING_DTYPE_INT(on_arity_dispatched_cb_dtype)
on_arity_dispatched_cb_dtype(::megdnn::dtype::Bool) megdnn_throw("bad dtype");
}
template <int arity>
void ElemwiseForwardImpl::on_arity_dispatched_no_bool() {
printf("********************** on_arity_dispatched_no_bool\n");
auto src = make_elemwise_op_param<arity>();
MEGDNN_FOREACH_COMPUTING_DTYPE_FLOAT(on_arity_dispatched_cb_dtype)
MEGDNN_FOREACH_COMPUTING_DTYPE_INT(on_arity_dispatched_cb_dtype)
megdnn_throw("bad dtype");
}以下为ModeDispatcher的定义:
#define FOREACH MEGDNN_FOREACH_ELEMWISE_MODE_TERNARY_FLOAT
IMPL_MODE_DISPATCHER(3, DTypeCategory::FLOAT);
#define IMPL_MODE_DISPATCHER(_arity, _dtype_cat) \
template <typename ctype> \
struct ElemwiseForwardImpl::ModeDispatcher<_arity, _dtype_cat, ctype> { \
static constexpr int arity = _arity; \
static void run( \
HandleImpl* handle, const ElemwiseOpParamN<arity>& src, Mode mode, \
const TensorND dst) { \
switch (mode) { \
FOREACH(_cb_dispatch_mode) \
default: \
megdnn_throw("bad mode"); \
} \
} \
}
#undef FOREACH
#define MEGDNN_FOREACH_ELEMWISE_MODE_TERNARY_FLOAT(cb) \
MEGDNN_ELEMWISE_MODE_ENABLE(COND_LEQ_MOV, cb) \
MEGDNN_ELEMWISE_MODE_ENABLE(COND_LT_MOV, cb) \
MEGDNN_ELEMWISE_MODE_ENABLE(FUSE_MUL_ADD3, cb) \
MEGDNN_ELEMWISE_MODE_ENABLE(CLIP, cb) \
MEGDNN_ELEMWISE_MODE_ENABLE(PRELU_GRAD, cb)
#define MEGDNN_ELEMWISE_MODE_ENABLE(_mode, _cb) _cb(_mode)
扩展代码后:
template <typename ctype>
struct ElemwiseForwardImpl::ModeDispatcher<_arity, _dtype_cat, ctype> {
static constexpr int arity = _arity;
static void run(
HandleImpl* handle, const ElemwiseOpParamN<arity>& src, Mode mode,
const TensorND dst) {
switch (mode) {
FOREACH(_cb_dispatch_mode)
default:
megdnn_throw("bad mode");
}
}
展开为:
template <typename ctype>
struct ElemwiseForwardImpl::ModeDispatcher<_arity, _dtype_cat, ctype> {
static constexpr int arity = _arity;
static void run(
HandleImpl* handle, const ElemwiseOpParamN<arity>& src, Mode mode,
const TensorND dst) {
switch (mode) {
_cb_dispatch_mode(COND_LEQ_MOV)
_cb_dispatch_mode(COND_LT_MOV)
_cb_dispatch_mode(FUSE_MUL_ADD3)
_cb_dispatch_mode(CLIP)
_cb_dispatch_mode(PRELU_GRAD)
default:
megdnn_throw("bad mode");
}
}
#define _cb_dispatch_mode(_m) \
case Mode::_m: \
do { \
using KernImpl = ElemwiseKern< \
megcorePlatformCPU, param_enumv::Elemwise::Mode::_m, ctype>; \
MIDOUT_BEGIN( \
megdnn_naive_elemwise, \
midout_iv(param_enumv::Elemwise::Mode::_m)) { \
auto params = src; \
MEGDNN_DISPATCH_CPU_KERN( \
handle, ElemArithKernCaller<arity MEGDNN_COMMA KernImpl>::run( \
dst.ptr<ctype>(), params)); \
return; \
} \
MIDOUT_END(); \
} while (0);看看ElemwiseKern之CLIP算子的定义
struct ElemwiseKern;
DEF_KERN_ALL(CLIP, x <= y ? y : (x <= z ? x : z));
//! define kernel for all ctypes
#define DEF_KERN_ALL(_mode, _imp) \
DEF_KERN_INT(_mode, _imp); \
DEF_KERN_FLOAT(_mode, _imp);
//! define kernel for all float types
#define DEF_KERN_FLOAT(_mode, _imp) \
DEF_KERN(dt_float32, _mode, _imp); \
DNN_INC_FLOAT16(DEF_KERN(dt_float16, _mode, _imp);) \
DNN_INC_FLOAT16(DEF_KERN(dt_bfloat16, _mode, _imp);)
//! define kernel for all int types
#define DEF_KERN_INT(_mode, _imp) \
DEF_KERN(dt_int32, _mode, _imp); \
DEF_KERN(dt_int16, _mode, _imp); \
DEF_KERN(dt_int8, _mode, _imp); \
DEF_KERN(dt_uint8, _mode, _imp);
//! define kernel for a single ctype
#define DEF_KERN(_ctype, _mode, _imp) \
template <megcorePlatform_t plat> \
struct ElemwiseKern<plat, param_enumv::Elemwise::Mode::_mode, _ctype> { \
typedef _ctype ctype; \
static __host__ __device__ _ctype apply(KERN_SIG) { return ctype(_imp); } \
}
ElemArithKernCaller 为实际算子执行代码:
其中KernImpl就是前面定义的 ElemwiseKern, 通过MEGDNN_DISPATCH_CPU_KERN,有CPU调度执行
/*!
* \brief operator impls should utilize this method to
* \param _handle a pointer to HandleImpl
* \param _stmt the statements to be executed for the kernel
*/
#define MEGDNN_DISPATCH_CPU_KERN(_handle, _stmt) \
do { \
auto _kern = [=]() { _stmt; }; \
_handle->dispatch_kern(_kern); \
} while (0)
template <int arity, class KernImpl>
struct ElemArithKernCaller {
typedef typename KernImpl::ctype ctype;
static void run(ctype* dest, const ElemwiseOpParamN<arity>& param);
};
template <class KernImpl>
struct ElemArithKernCaller<1, KernImpl> {
typedef typename KernImpl::ctype ctype;
static void run(ctype* dest, const ElemwiseOpParamN<1>& param) {
auto iter0 = tensor_iter_valonly<ctype>(param[0]).begin();
for (size_t i = 0; i < param.size; ++i) {
dest[i] = KernImpl::apply(*iter0);
++iter0;
}
}
};
template <class KernImpl>
struct ElemArithKernCaller<2, KernImpl> {
typedef typename KernImpl::ctype ctype;
static void run(ctype* dest, const ElemwiseOpParamN<2>& param) {
auto iter0 = tensor_iter_valonly<ctype>(param[0]).begin();
auto iter1 = tensor_iter_valonly<ctype>(param[1]).begin();
for (size_t i = 0; i < param.size; ++i) {
dest[i] = KernImpl::apply(*iter0, *iter1);
++iter0;
++iter1;
}
}
};
template <class KernImpl>
struct ElemArithKernCaller<3, KernImpl> {
typedef typename KernImpl::ctype ctype;
static void run(ctype* dest, const ElemwiseOpParamN<3>& param) {
auto iter0 = tensor_iter_valonly<ctype>(param[0]).begin();
auto iter1 = tensor_iter_valonly<ctype>(param[1]).begin();
auto iter2 = tensor_iter_valonly<ctype>(param[2]).begin();
for (size_t i = 0; i < param.size; ++i) {
dest[i] = KernImpl::apply(*iter0, *iter1, *iter2);
++iter0;
++iter1;
++iter2;
}
}
};















 2640
2640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









