 解决qwen2.5vl加载mismatch问题
解决qwen2.5vl加载mismatch问题




在用VLMEvalKit框架进行MLLM评测的时候,发现加载我的qwen2.5-vl-7b模型报错:
size mismatch for bias: copying a param with shape torch.Size([3584]) from checkpoint, the shape in current model is torch.Size([1280]).
网上搜了一圈没找到类似的错,后面查看log发现有一个warning信息:
You are using a model of type qwen2_5_vl to instantiate a model of type qwen2_vl. This is not supported for all configurations of models and
can yield errors.
这个应该就是问题来源,也就是说我加载的模型里model_type为qwen2.5vl,但是模型加载代码里的model类型是qwen2vl,没匹配上模型结构。
问题找到了,怎么改呢?
首先找到warning信息输出源,我全局搜索的,发现在
vlmeval/vlm/hawk_vl/hawk/model/vision_encoder/qwen_vit/configuration_qwen_vit.py
有类似代码:

修改这里面的代码无效,说明其实没调用这里的代码,只是逻辑上有重合的模块,看了一下这个是QwenVisionConfig实,际上继承了PretrainedConfig类,后者在transformers库,也就是比如在这样的路径:
{conda环境目录}/lib/python3.10/site-packages/transformers 下
其中找到configuration_utils.py里的PretrainedConfig类,有一样的代码,修改后发现确实调用这里的warning,在这里进行debug就行。

为什么这里是qwen2_vl呢,我就追溯这个cls实例的来源,后面发现是在
VLMEvalKit/vlmeval/vlm/qwen2_vl/model.py
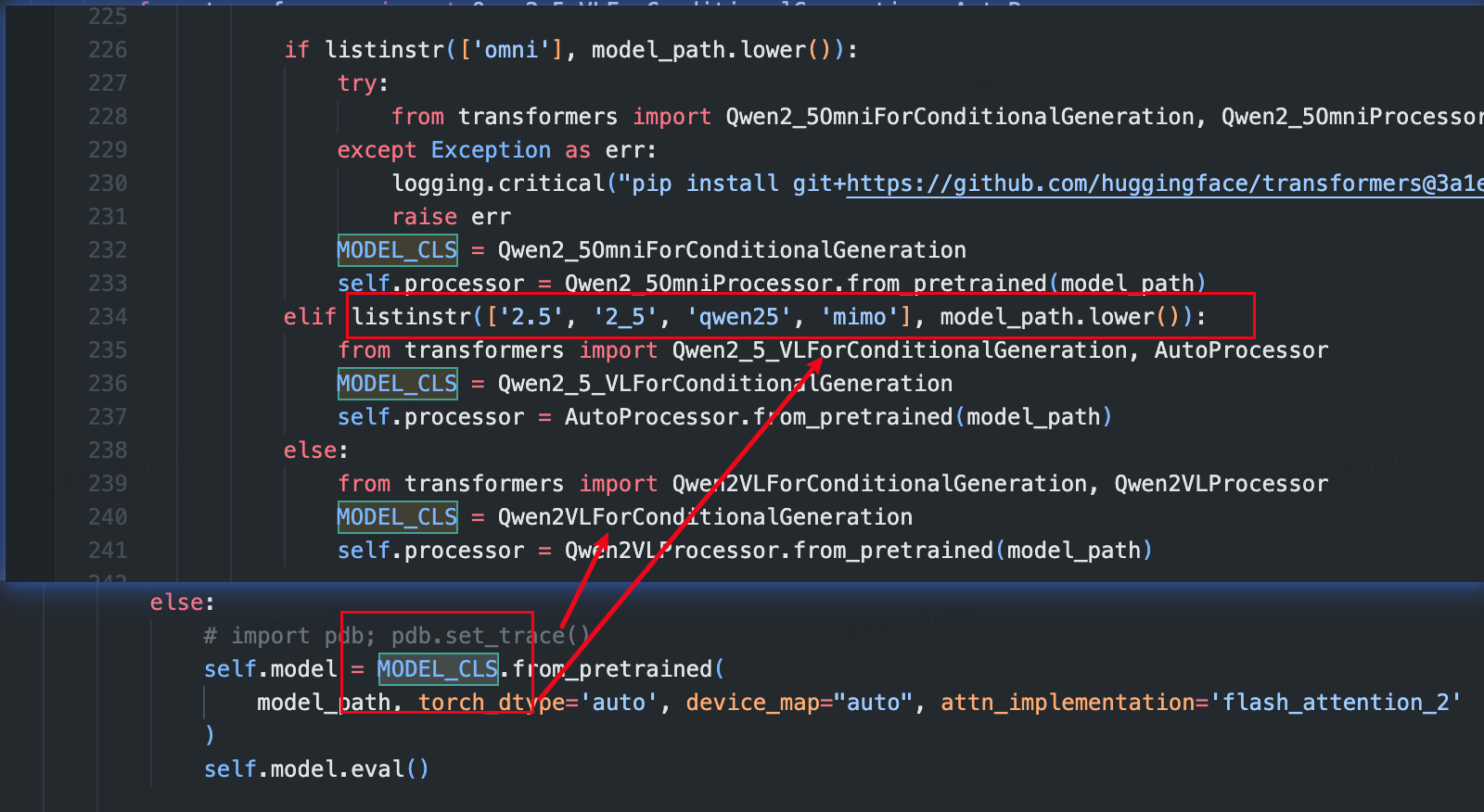
在vlmevalkit框架里被定义,简单来说就是我的框架里的config.py里定义了
partial(
Qwen2VLChat,
# model_path="xxx"
min_pixels=1280 * 28 * 28,
max_pixels=16384 * 28 * 28,
use_custom_prompt=False,
),
这里用了Qwen2VLChat(因为qwen2.5vl在vlmevalkit里也是这样用的,没有对2.5vl单独有个实例)
然后框架里会根据路径里是否有2.5来判断是不是qwen2.5vl,没有的话就默认是qwen2vl。。。。
要改的话也很简单,路径里加个2.5,但是不得不说这样的设计有点草台班子。


















 4963
4963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









