







—–Set:元素无序(存入和取出的顺序不一定是一致),元素不可以重复
—HashSet:底层数据结构是哈希表
hashSet是如何保证元素唯一性的呢?
是通过元素的两个方法,hashCode和equals来完成
如果元素的hashCode值相同,才会判断equals是否为true;如果元素的hashCode值不同,不会调用equals方法。
注意:对于判断元素是否存在(contains),删除(remove)、添加(add),都要先hashCode,后equals
Set集合的功能和Collection是一致的。
package com.HashSet;
import java.util.*;
/*
* 哈希集合,是先看哈希地址,因为是new出来的东西,所以他们的哈希地址均不同
* 被认为是不同的元素,不符合实际应用
*/
public class People {
private String name;
private int age;
People(String name,int age){
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public boolean equals(Object obj) //注意这里是复写,所以必须传Object对象
{
if(!(obj instanceof People))//集合中各种类型的元素,若不是人类型,则返回false
return false;
People p=(People)obj;
System.out.println(this.name+"---equals--"+p.name);
if(this.name==p.name&this.age==p.age)
return true;
return false;
}
public int hashCode() {
System.out.println(this.name+"---------hashCode");
//return 60;这是word上的讲解return
//用同一个hashCode使得没存入一个元素,就得判断equals,比较麻烦,所以可以在hashCode这做些判断,
//hashCode不相同的就不用再判断equals了,优化代码。
System.out.println("name.hashCode:"+(name.hashCode()+age)+"---------------------------------");
return name.hashCode()+age;
}
}
public class HashSetDemo {
public static void sop(Object obj) {
System.out.println(obj);
}
public void WuXu_BuChongFu() {
HashSet hs=new HashSet();
hs.add("java01");
hs.add("java01");
hs.add("java03");
hs.add("java05");
//public boolean add(E e)注意其返回值为布尔类型,在Set中,不允许有重复元素
//所以存入失败
Iterator it =hs.iterator();
while(it.hasNext())//set无序,所以打印结果很可能与存入的顺序不同
{
System.out.println(it.next());
}
}
public static void main(String[] args) {
HashSet hs=new HashSet();
hs.add(new People("a1",11));
hs.add(new People("a2",12));
hs.add(new People("a3",13));
hs.add(new People("a2",12));
sop("元素存入成功:!!!!!!!!");
//sop("a1:"+hs.contains(new People("a2",12)));//判断是否包含也是先判断hashCode,若不同,则一定不包含,若相同,则判断equals方法
//根据equals方法来得出返回值
sop("移除a3"+hs.remove(new People("a3",13)));//和contains相同判断过程
/*Iterator it=hs.iterator();
while(it.hasNext()) {
People p=(People)it.next();
sop(p.getName()+" "+p.getAge());
}*/
}
}
哈希地址解释:
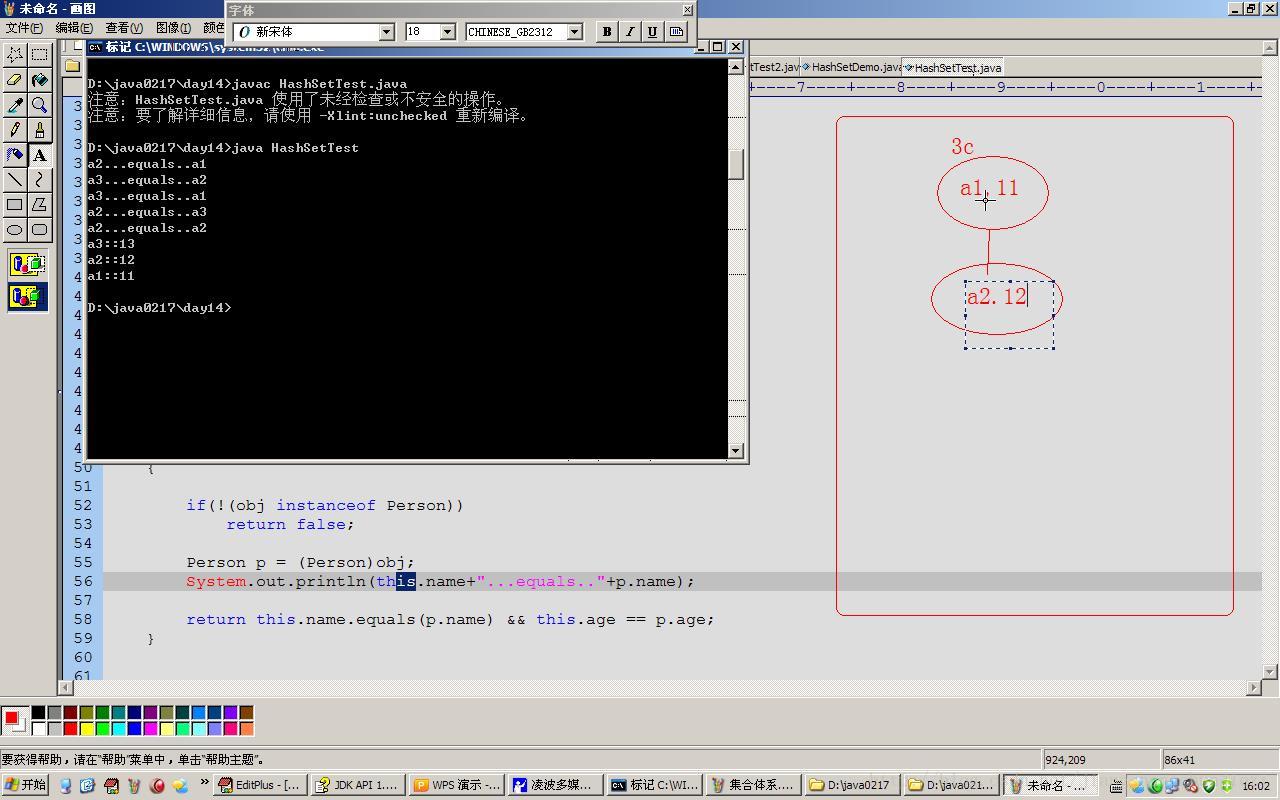
总体而言,就是先看哈希码值,再看equals方法
因为People中对HashCode进行重写,所有对象均是同一个哈希地址。
(若不重写,就是自动生成哈希值,那么第一步就不相同,不用判断第二步。)
①a1正常填入。
②a2在填入前,先判断了hashCode,相同,所以用equals方法进行判断,姓名和年龄数值不同,所以存入.
③a3在填入前,先判断了hashCode,相同,所以用equals方法进行和已经存入的元素比较,比较的顺序不确定,如图所示,可以先a2再a1.均不同存入。
④a2在存入前,先判断了hashCode相同,所以用equals方法进行和已经存入的元素进行判断,比较顺序不确定,如图所示,先a3,再a2,比较到a2时,就判断出有相同的元素了,所以不存入a2,就不用再和a1比较了。
若在hashCode中输出一句话,就更容易理解了。见下面输出
a1———hashCode
a2———hashCode
a2—equals–a1
a3———hashCode
a3—equals–a1
a3—equals–a2
a2———hashCode
a2—equals–a1
a2—equals–a2

















 3630
3630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









