






保姆级在Kaggle上部署stable diffusion,白嫖万元 32G 双GPU
最近爆火的AI绘画项目stable diffusion,免费开源,受到广大用户的喜爱,但是它对电脑显卡有很高的要求,自己想玩AI但是购买服务器又太贵,本文将告诉你一个免费部署的方法。
Kaggle注册
1、首先打开Kaggle官网: www.kaggle.com

可以使用国内邮箱账号注册
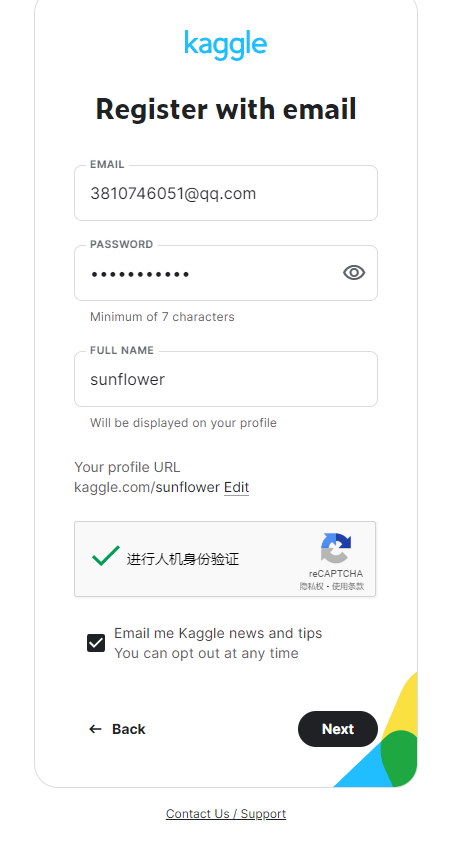
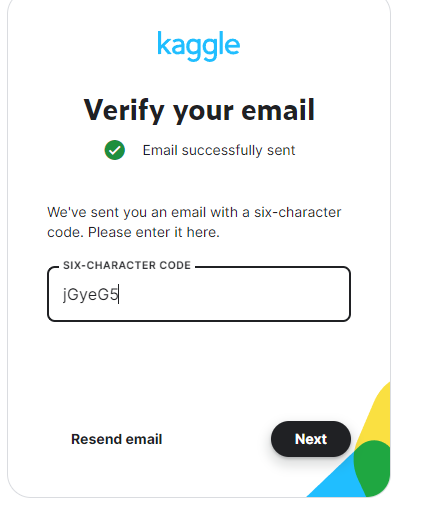
发送邮箱验证,输入邮箱验证码
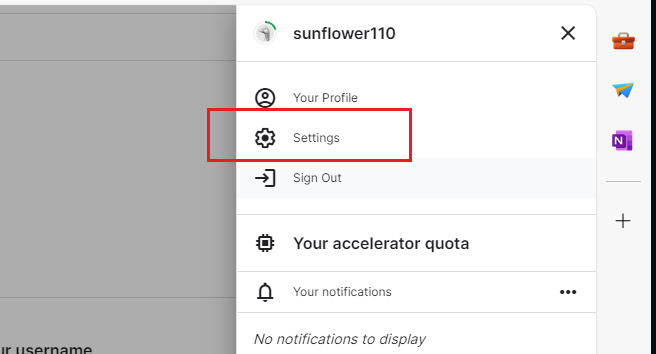
首先点击右上角的头像,进入设置
如果需要使用GPU,需要手机进行验证,点击手机 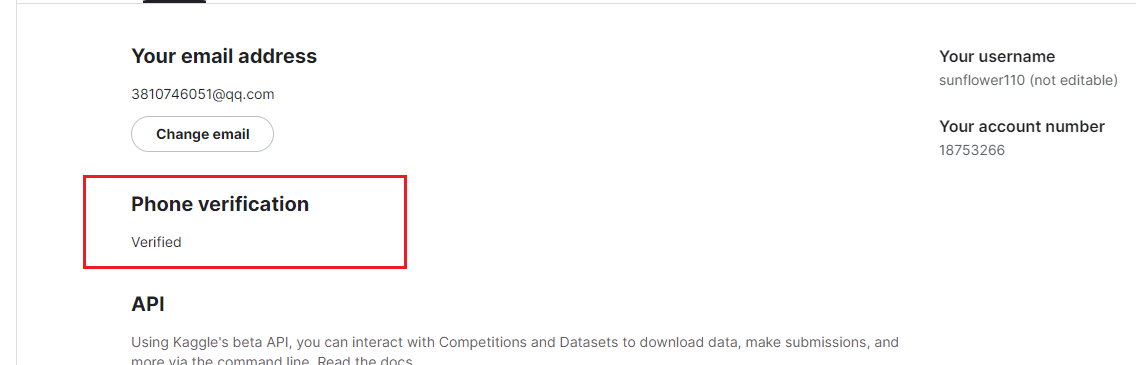
使用你的手机号码进行校验
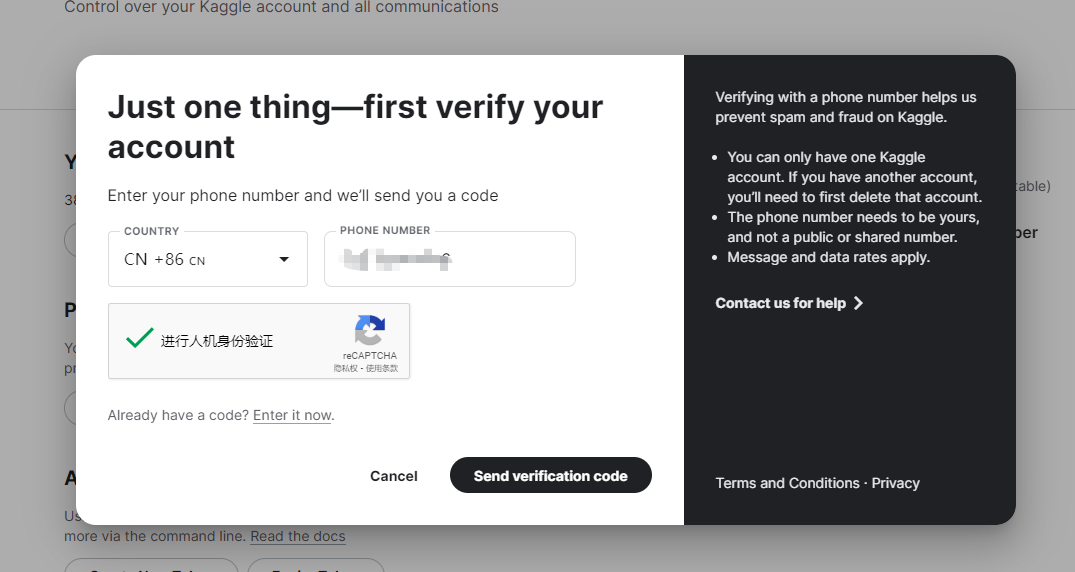
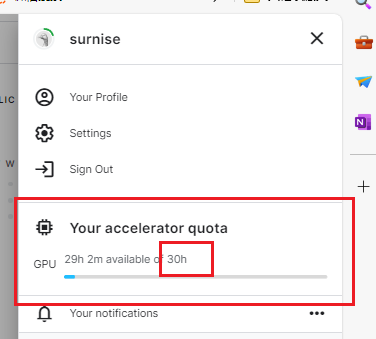
可以看到我们有30小时的gpu的使用时间,这个时间每周都会重置。平均每天4个小时对于普通人完全够用了。
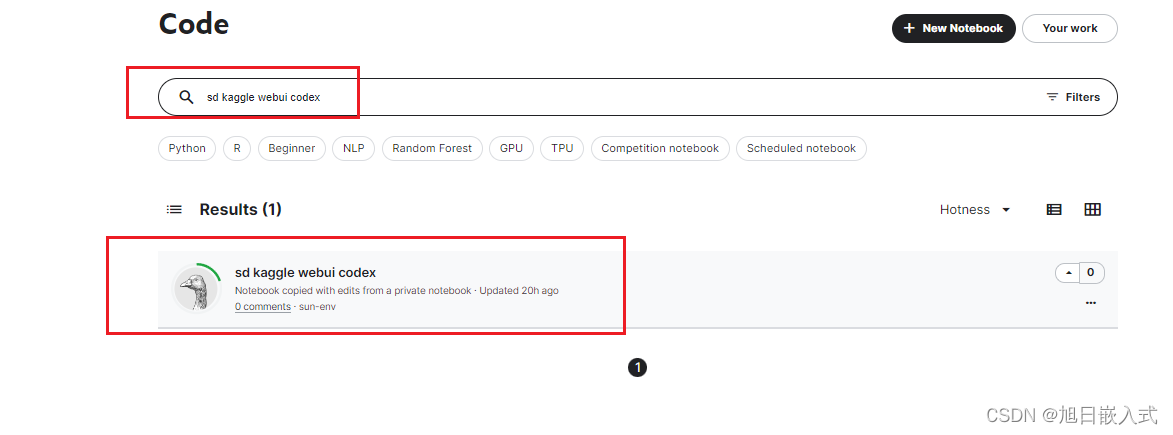
我们点击code 搜索 sd kaggle webui codex
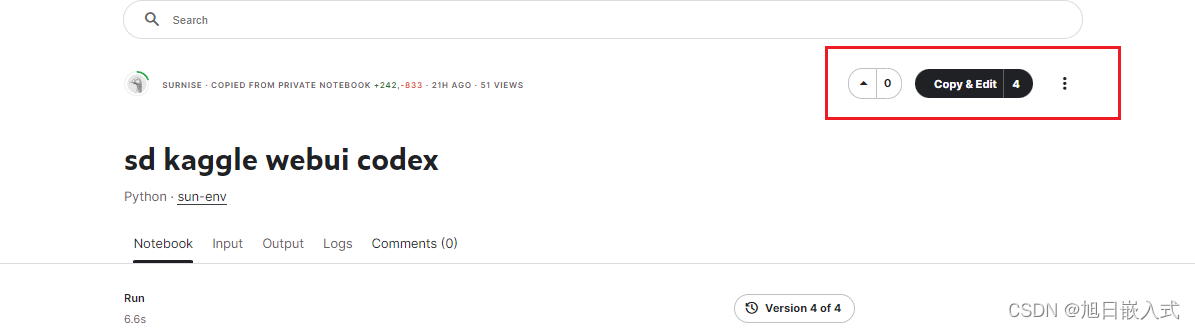
进入之后 点击 copy&Edit
按如图所示进行选择 选择GPUT4x2 ,开启联网
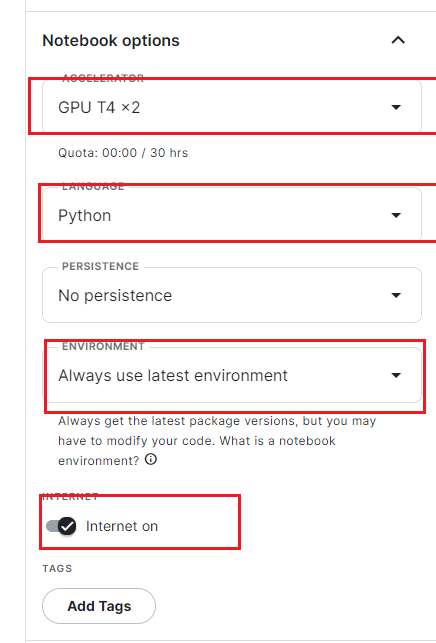
点击Run All

等待4~5分钟左右,当看到如下连接,说明已经部署成功了。
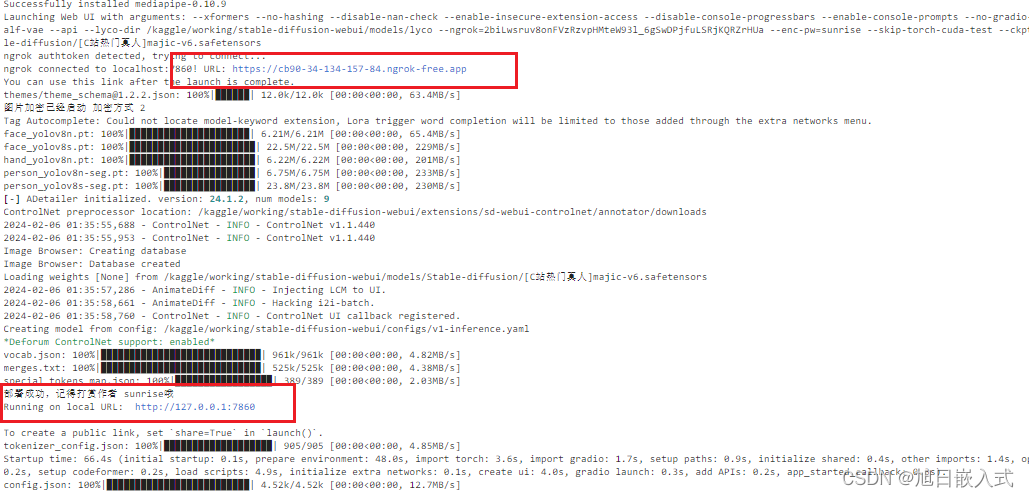
注意:当我们用完后,一定要记得点击右上角那个电源的图标将其关机,否则会一直消耗GPU时长。
我们点击ngrok的内网穿透链接,如果需要自己配置内网穿透,可以查看关于如何使用ngrok的内网穿透的文章
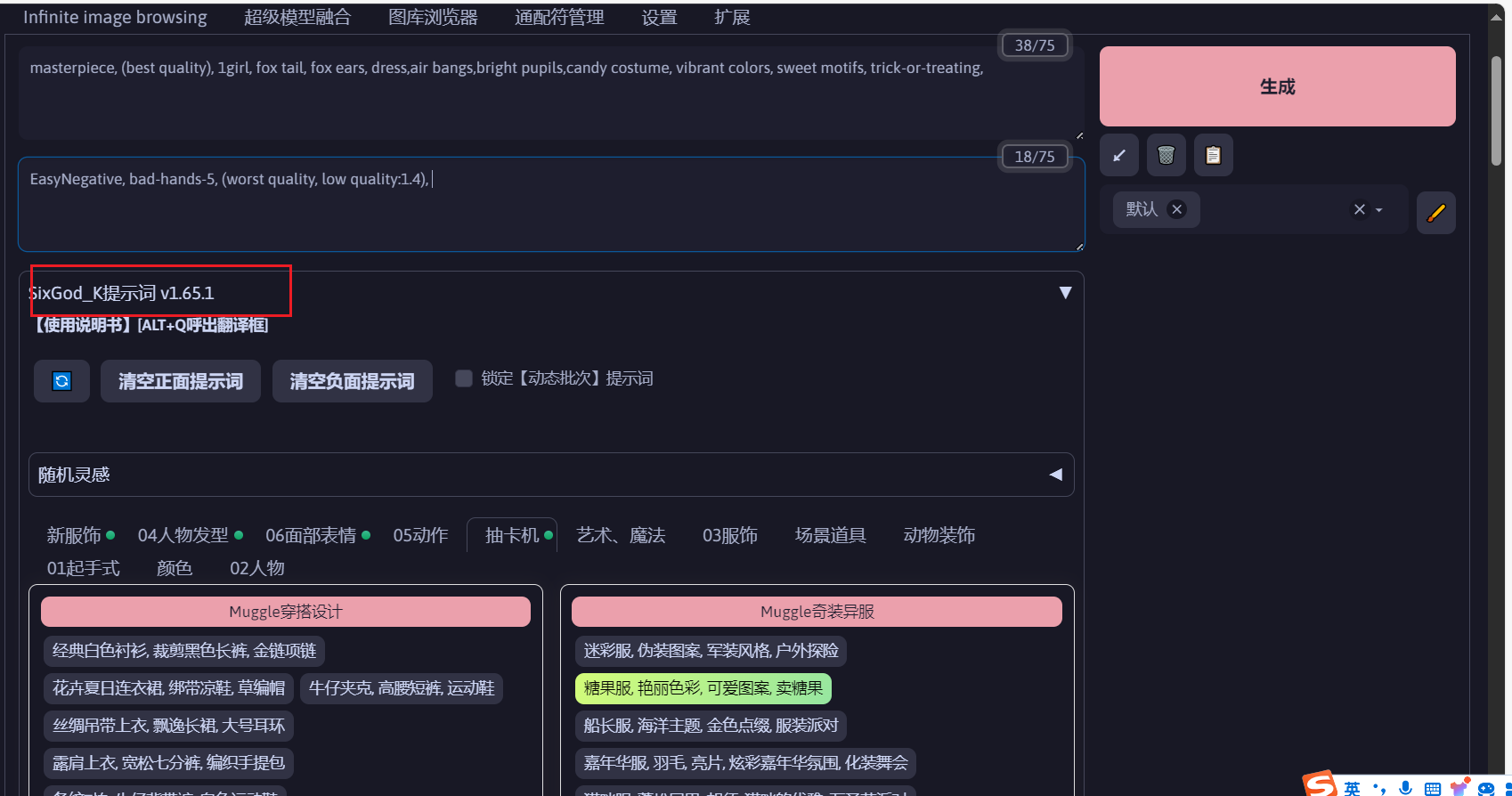
各种常用的插件,爆款提示词插件都已经内置了,抽卡来一张

可自行修改提示词,看看生成的效果。

















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









