







 本文介绍了如何在MapReduce中实现自定义Partitioner,通过Partitioner将数据根据运营商分到不同组,详细讲解了MyPartitioner的实现,并强调了在集群上运行以观察效果的必要性。实验结果显示,Partitioner成功将数据分配到指定的Reducer中。
本文介绍了如何在MapReduce中实现自定义Partitioner,通过Partitioner将数据根据运营商分到不同组,详细讲解了MyPartitioner的实现,并强调了在集群上运行以观察效果的必要性。实验结果显示,Partitioner成功将数据分配到指定的Reducer中。
接着
mapreduce–使用自定义类做value
继续做实验,这次试一试Partitioner的效果。
根据之前实验的数据,key值是数据中第二列的电话号码,我想把它们根据运营商不同分到不同的组,也即以13,15,18,以及其他开头的号码分别分到一组中。
那么我应该加一个Partitioner控制shuffle阶段的分组过程。
- MyPartitioner扩展Partitioner类 Partitioner类的范形参数K,V和Mapper的输出参数是一致的
- 需要重载getPartition函数,它的参数分别为Mapper的输出参数以及Reducer的数目
- getPartition函数返回的int值便是它处理的键值对Key,Value所分配到的Reducer序号
- 我设置了4个Reducer,所以可以使用的Reducer序号依次为0,1,2,3
- 我使用了一个静态的Map,注意Map里边的泛型参数是Integer,不能为int的;Map是虚拟类,所以创建实例的时候也不能创建Map,而应该创建具体类比如HashMap;静态成员变量的初始化方式用static{…}来处理
public static class MyPartitioner extends Partitioner<Text, MyData>{
//
private static Map<String, Integer> myMap = new HashMap<String, Integer>();
static{
myMap.put("13", 1);
myMap.put("15", 2);
myMap.put("18", 3);
}
@Override
public int getPartition(Text key, MyData value, int numPartitions) {
// TODO Auto-generated method stub
String strKey = key.toString();
String prefix = strKey.substring(0, 2);
int retPartition = 0;
if (myMap.containsKey(prefix)){
retPartition = myMap.get(prefix);
}
return retPartition;
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
Job job = new Job(conf, "Test1");
job.setJarByClass(HadoopTest1.class);
//注意设置Reducer的数目
job.setNumReduceTasks(4);
job.setMapperClass(HadoopTest1Mapper.class);
//设置Partitioner的类
job.setPartitionerClass(MyPartitioner.class);
job.setReducerClass(HadoopTest1Reducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(MyData.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}如果是在单机伪分布式情况下进行实验,不管Reducer数目设置为多少,实际上都只有一个。所以必须要在集群上进行实验才能看到效果。
首先将数据上传到集群中,并登陆集群账号,此时ls显示的内容便是集群账号的本地文件系统,此时数据不在hdfs里边!
所以要把HTTP.dat数据上传到hdfs目录下,不过,为什么jar文件不需要上传呢?

查看hdfs里边的目录,可以看到文件已经上传到hdfs里边了。

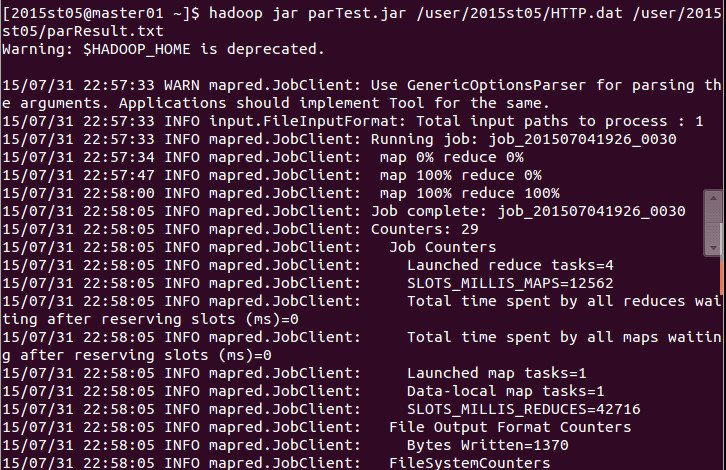
执行hadoop jar命令运行程序,因为在生成jar包的时候已经设置了主类,所以此时
hadoop jar parTest.jar 后面不需要接主类的名字,可以直接跟输入输出参数了。输入输出都是在hdfs里边进行的!
输出参数的起名有点问题,虽然我写的是parTest.result,看起来是个文件,但实际上它是个目录啦。
查看结果目录,可以看到对于每个Reducer,都生成了一个相应的part-r-0000x。
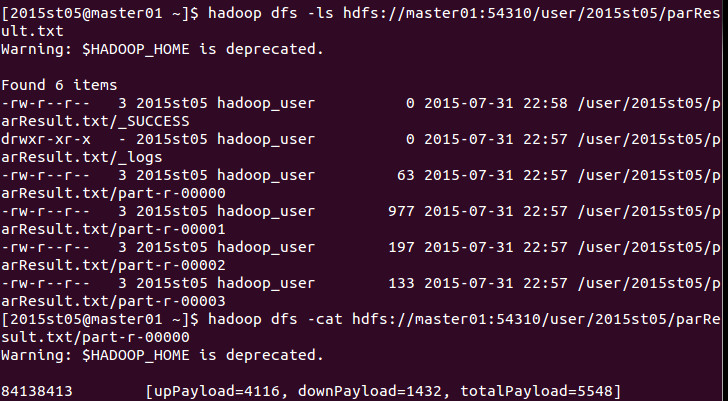
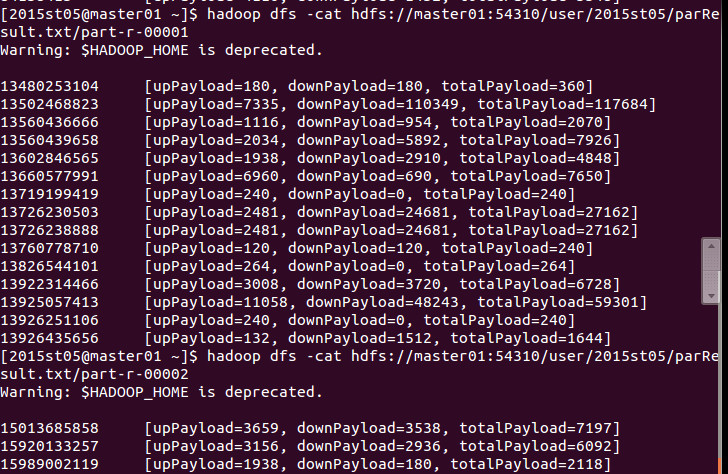
依次查看每个Reducer的结果,可以看到它们确实按照我的Partitioner进行了划分啦!















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









