







上一节说到SBF对counter的存储。为实现counter的高效存储,我们先简化问题,来看最少需要多少位才能存储所有的counter。假设SBF要表示M个元素的集合(可能包含重复元素),counter数组的长度为m(对应着bloom filter的位数组),显然所有counter需要的最少位数N为
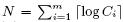
其中Ci表示counter数组中第i个counter的大小,即哈希函数映射到第i位的次数。用N位存储counter,其实相当于把所有的counter化成二进制位串然后连在一起。这样当然占用的位数最少,但如何访问长度不一的counter是个大问题。不管怎么样,在不考虑增删操作的情况下,我们想要达到的目标就是在保证查询操作快速的基础上,使得存储位数尽量接近N。
SBF并没有发明什么异乎寻常的高超技巧,和你大概能想到的一样,它构建了一套索引结构。首先SBF将N位的基本位串分成m/logN段,每一段包含logN个counter,然后将每一段的offset记下来。由于offset要占用logN位,所以记录子串offset的数组(论文中叫Coarse Vector)总长度为m位。
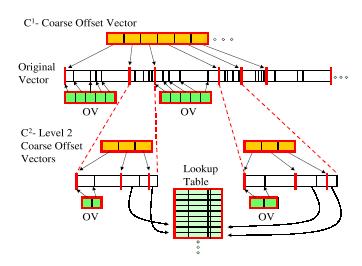
有了Coarse Vector,我们就可以随机访问任何一个子串了。这时我们有两种选择,要么把子串继续分成子段,要么将子串中所有counter的offset记下来(即上图中的OV,Offset Vector)。子串有长有短,但所含counter个数相同,也就是记录counter的offset数组长度相同,这就意味着把长子串用来记录offset比较划算。SBF规定子串长度超过log3N位的,直接用offset数组记录counter位置,否则再继续分。N位基本位串中最多有N/log3N个长度不超过log3N的子串,所以在这一层所有的offset数组加起来长度最多为N/log3N × (logN × logN) = N/logN位。
长度不超过log3N位的子串,我们将其再分成loglogN段,每一段包含logN/loglogN个counter。由于offset要占用loglog3N = 3loglogN位,所以整个offset数组总长度为3loglogN ×logN/loglogN = 3logN位。这一层所有的offset数组加起来长度最多为m/logN × 3logN = 3m位。
并不是子串的每一个子段都用offset数组来存储counter的位置,和前面一样,仍然只记录较长的子段。假设子段长度为T,这里的阀值设为T0 = (loglogN)3,当T > T0时,子段的counter位置用offset数组记录。由于子段包含loglogN个counter,且每一个offset可以用3loglogN位表示,因此offset数组的长度最多为loglogN × 3loglogN = 3(loglogN)2 « T。这一层的所有的offset数组长度加起来也不过O(N)。
现在就剩了T ≤ T0的情况,这时SBF也不继续分了,而是将所有这类情况存储在一个全局查询表里。关于这个查询表,这里就不多做介绍了,有兴趣的可以去读一下原始论文。总之,在不考虑增删操作的情况下,SBF的counter存储所要达到的目标就是只使用O(N) + O(m)位,构建时间为O(m)。通过上面构建的复杂的索引结构,这个目标是达到了。下一节我们来看增删操作如何在这样的结构上实现。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









