







散列表(hash table)是实现字典操作的一种有效数据结构,尽管最坏的情况下散列表中查找一个元素与链表中查找的时间相同,达到了时间复杂度:n。但在合理的假设下,在散列表中查找一个元素的平均时间是 :1;散列表成为数组寻址的一种有效替代,因为散列表使用一个长度与实际存储的关键字数目成比例的数组来存储。因此,有时候通过散列函数计算出的下标,可能在多个关键字上产生冲突,因此就需要有效地解决冲突的方法。JAVA中的map set容器的hash结构,具有所有存储方式中最快的查找速度。
1.直接寻址表
当关键字的全域比较小时(即最大值(上界)较小时),直接寻址是一种简单有效的技术。假设某动态集合中,每一个元素都是取自于全域U={0,1,2……,m-1}的一个关键字,这里m不是一个很大的数,否则会浪费很多空间。并且假设两个元素没有相同的关键字。我们用一个数组T[0……m]来表示一个直接寻址表,表中的每一个位置称为槽,对应全域中的一个关键字,没有存放关键字的槽为NIL。如图:
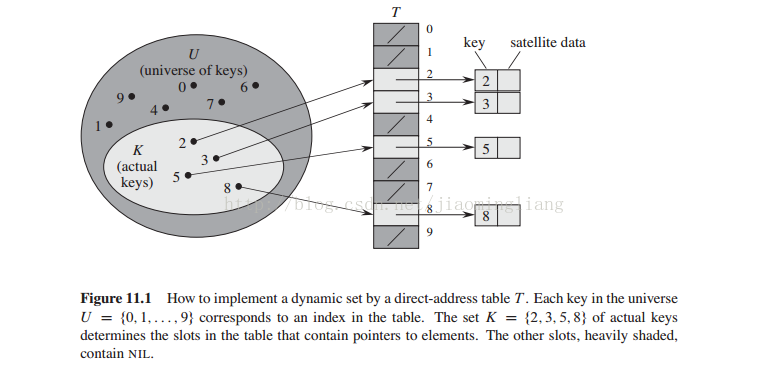
其字典操作非常简单:
search(T,k)//查询
{
return T[k];
}
insert(T,x)//插入
{
T[x.k]=x;
}
delete(T,k)//删除
{
T[k]=null;
}直接寻址简单,但是当全域很大时,就会面临他的缺陷。在散列方式下,钙元素存在槽h(k),中h为将key映射入散列表(T[0……m-1])的函数,由此计算出关键字存储在槽中的位置。这里散列表的大小m一般要比|U|小的多,h(k)是k的散列值,散列函数减少了数组的大小。

因为|U|>m,加上散列函数的映射,肯定会多个关键值存放在相同槽中,在同一个槽中的key可能相同,也可能不同,主要解决冲突的方法有链表法和开放寻址法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2689
2689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









