




 本文介绍聚类算法及K-Means的工作原理与步骤,通过实例展示如何使用sklearn进行聚类,并讨论不同k值对结果的影响。
本文介绍聚类算法及K-Means的工作原理与步骤,通过实例展示如何使用sklearn进行聚类,并讨论不同k值对结果的影响。
聚类算法是一类非监督学习的算法,在给定的一个数据集中,给了N个样本,没有给出样本对应的标签类别数据y,可以利用聚类算法,进行标签的分类。
K-Means算法的原理与步骤:
1> 在N个样本总体中,随机抽出k个初始数据的质心,接着把数据集中的样本取出,计算样本离各个质心的距离,把样本归到离质心最近的一个簇里

2> 计算每个簇的样本特征的平均值,得到各簇新的质心
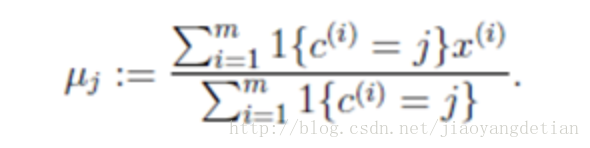
3> 迭代以上两个步骤,直到满足下边的公式:(即代价函数的值最小,质心的坐标不再变化,或者变化很小时)

聚类算法的缺点:
1> 在不知道样本数据集的数据有几个分类时,k值是开发人员设定的,如果k值一次设置的不合适,需要随机再设置,最后才能使模型收敛。
注:这里模型收敛的情况下,也可能只是达到了局部最小值,这时候需要改进模型,后边再讲
2> 每次聚类的过程,使模型收敛通常要经过大量的迭代过程
下面是举的一个例子:这里是用了sklearn提供的KMeans方法
从csv文件中,取出一万多条数据,取出数据中对应两个特征的两个列,进行聚类,结果得出,它被分为了3个类别,下边两种图分别为,初始质心点k = 2,与初始质心点k=3,两种情况下,聚类的效果图表:(很显然k=3时更合适)

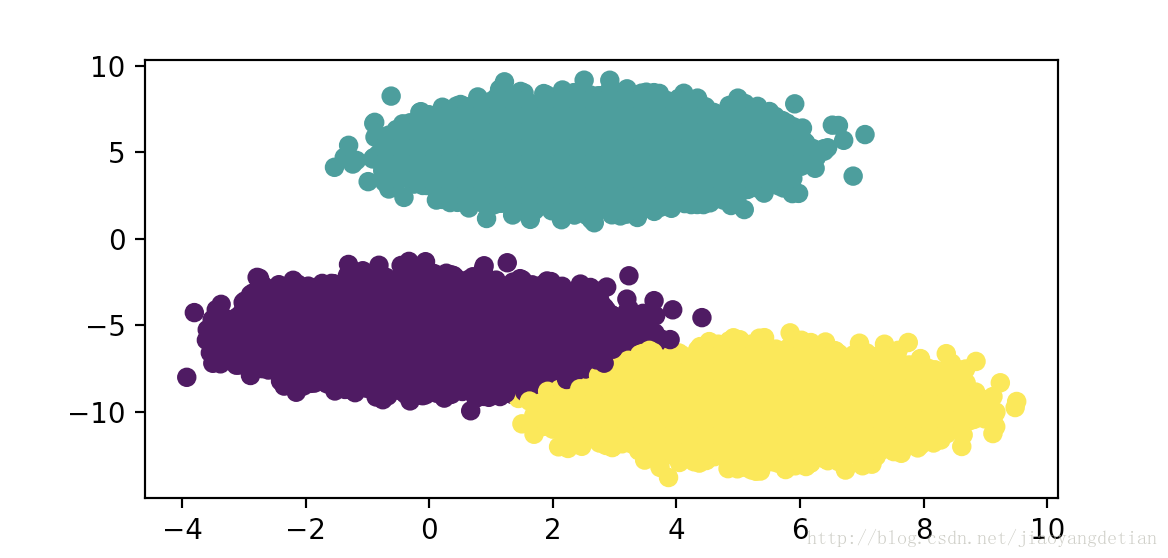
下面是这个例子demo的下载地址:demo

















 2035
2035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









