







觉得有帮助请点赞关注收藏~~~
值函数逼近
对于取实数值R的动作值函数Q(s,a)来说,它是状态空间S和动作空间A的笛卡尔积到实数集的映射:S×A→R
该映射问题可以看作是机器学习中的回归问题,因此,求解回归问题的模型都可以用来求得该映射。
其基本方法一般是先确定逼近的结构,然后通过样本集来迭代优化结构的参数。这种事先确定结构,再优化参数的逼近方法,称为参数化逼近。参数化逼近又分为线性逼近和非线性逼近,它们分别采用线性和非线性的结构,前者如线性回归模型,后者如神经网络模型等等。
求解回归问题的关键问题包括模型、样本、损失函数和优化等方面。
1.模型
将逼近动作值函数Q(s,a)的模型结构记为Q ̂(x(s,a),θ),其中θ是待优化的参数向量,x(s,a)是由s和a按全排列组成的向量,共有|S|×|A|个可能取值。x(s,a)也可以看作是通过特征工程从状态和动作中提取的特征组成的向量。
当采用线性逼近时,动作值函数的逼近可表示为:
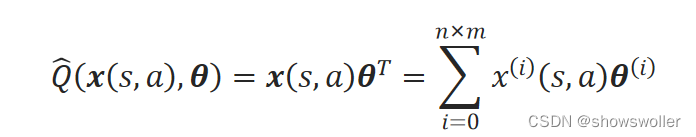
其中,指定x^(0)=1,指定θ^(0)=b是线性模型的偏置。
2.样本
记长度为T的轨迹τ=(s_0,a_0,s_1,a_1,…s_T−1,a_T−1),立即回报序列为:R=(r_1,r_2,…,r_T),累积折扣回报序列为:G=(G_0,G_1,…,G_T−1),其中G_t=r_t+1+γr_t+2+γ^2r_t+3+…+γ^T−1−tr_T=∑_k=0^T−1−t▒γ^kr_t+1+k。
基于蒙特卡罗法生成的训练样本为:s_t=(x(s_t,a_t),G_t),其中,x(s_t,a_t)是实例,G_t是对应的标签。
基于时序差分法生成的训练样本为:s_t=(x(s_t,a_t),r_t+1+γQ ̂(x(s_t+1,a_t+1),θ)),其中,x(s_t,a_t)是实例,r_t+1+γQ ̂(x(s_t+1,a_t+1),θ)是对应的标签。
3.损失函数
对基于蒙特卡罗法生成的训练样本来说,单个样本s_t=(x(s_t,a_t),G_t)产生的平方误差损失函数为:
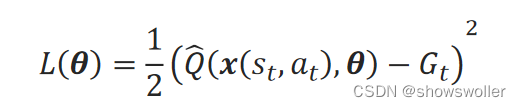
对基于时序差分法生成的训练样本来说,单个样本s_t=(x(s_t,a_t),r_t+1+γQ ̂(x(s_t+1,a_t+1),θ))产生的平方误差损失函数为:
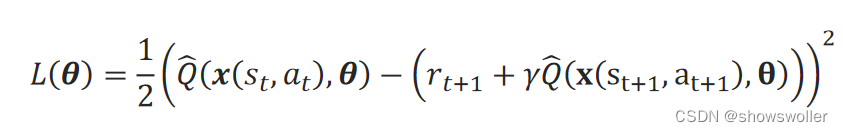
4.优化
参数θ的优化可采用多种方法,常用梯度下降法,其迭代关系式为:

如果采用线性逼近,对蒙特卡罗法生成样本的损失函数,梯度为:
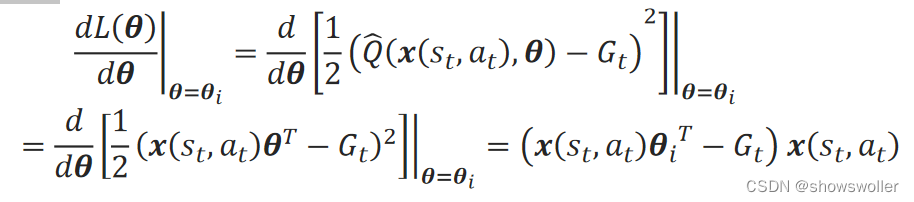
如果采用线性逼近,对时序差分法生成样本的损失函数,梯度为:
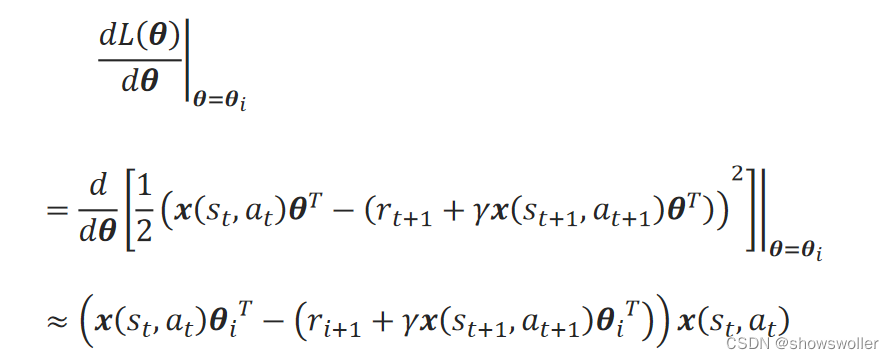
上式只对预测值x(s_t,a_t)θ_i^T进行了求导,忽略了对样本标签(r_i+1+γx(s_t+1,a_t+1)θ_i^T)的求导,可见此时并非完全的梯度法,此方法称为半梯度法。
基于值函数逼近的时序差分法基本流程
(2)和(4)步操作中的Q(s,a)用逼近函数Q ̂(x(s,a),θ)来计算。 当采用同策略的Sarsa法时,(5-1)步操作中的值函数的更新在参数化逼近中表现为参数θ的更新:
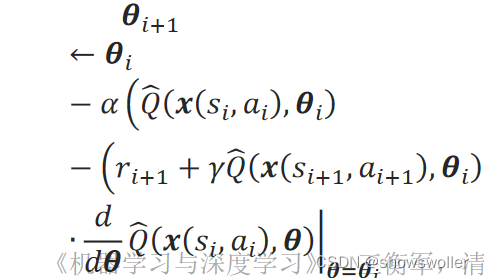
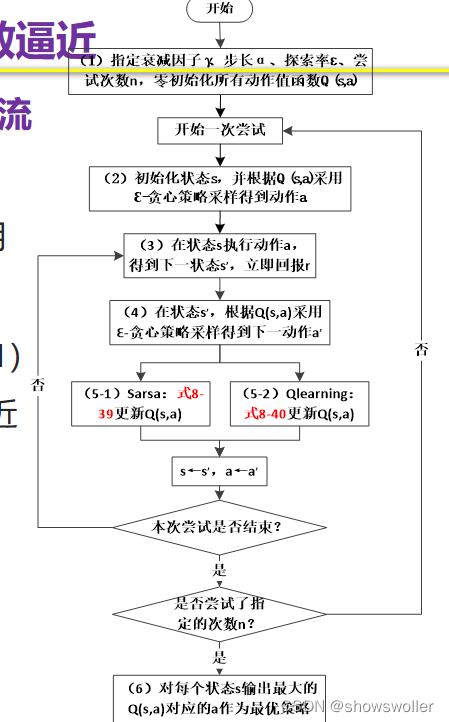
当采用异策略的Qlearning法时,(5-2)步中参数θ的更新采用贪心策略:
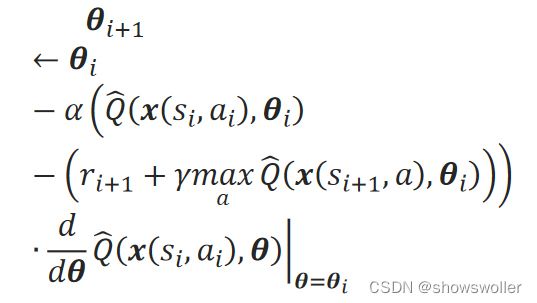
创作不易 觉得有帮助请点赞关注收藏~~~
















 6054
6054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











