







参考资料
[1] 强化学习入门 第五讲 值函数逼近
本文主要是对该资料学习的笔记,并且加入了一些自己的想法,如有错误欢迎指出。
强化学习的分类
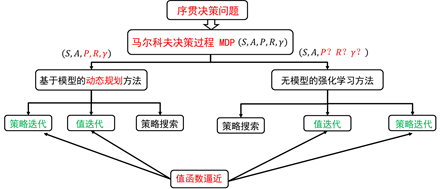
无模型强化学习 - 理论
强化学习的核心问题
强化学习的核心问题为:
- 策略评估部分:值函数、状态-行为值函数的估计问题!
- 策略改善部分:给定值函数下, π ( a ∣ s ) \pi(a|s) π(a∣s)的选取问题!
回报函数、值函数定义
累计回报函数
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
=
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
(1.1)
G_t = R_{t+1} + \gamma R_{t+2} + ... = \sum^{\infty}_{k=0} \gamma ^{k}R_{t+k+1} \tag{1.1}
Gt=Rt+1+γRt+2+...=k=0∑∞γkRt+k+1(1.1)
状态值函数
v
π
(
s
)
=
E
π
[
G
t
]
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
]
(1.2)
v_\pi (s) = E_\pi[G_t] = E_\pi \left[ \sum^{\infty}_{k=0} \gamma ^{k}R_{t+k+1} | S_t = s \right] \tag{1.2}
vπ(s)=Eπ[Gt]=Eπ[k=0∑∞γkRt+k+1∣St=s](1.2)
行为值函数
q
π
(
s
,
a
)
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
(1.3)
q_\pi (s,a) = E_\pi \left[ \sum^{\infty}_{k=0} \gamma ^{k}R_{t+k+1} | S_t = s , A_t = a \right] \tag{1.3}
qπ(s,a)=Eπ[k=0∑∞γkRt+k+1∣St=s,At=a](1.3)
状态值函数和行为值函数的定义是在策略
π
\pi
π下各次实现中累计回报函数的数学期望。
动态规划方法值函数:
V
(
s
t
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
R
s
a
+
γ
∑
s
′
P
s
s
′
a
V
(
s
′
)
)
(1.4)
V (s_t) = \sum_{a \in A} \pi(a|s)\left( R^a_s + \gamma\sum_{s'} P^{a}_{ss'}V(s') \right) \tag{1.4}
V(st)=a∈A∑π(a∣s)(Rsa+γs′∑Pss′aV(s′))(1.4)
动态规划方法值函数的计算用到了后继状态的值函数,利用bootstrapping方法,即用后继状态的值函数估计当前值函数。此时期望值由模型提供。
蒙特卡罗方法值函数:
V
(
s
t
)
=
V
(
s
t
)
+
α
(
G
t
−
V
(
s
t
)
)
(1.5)
V (s_t) = V (s_t) + \alpha(G_t-V(s_t)) \tag{1.5}
V(st)=V(st)+α(Gt−V(st))(1.5)
蒙特卡罗方法利用经验平均估计状态的值函数,即利用多次历史实验中该状态的平均累计回报函数来逼近期望。
时间差分方法值函数:
V
(
S
t
)
←
V
(
S
t
)
+
α
(
R
t
+
1
+
γ
V
(
S
t
+
1
)
−
V
(
S
t
)
)
(1.6)
V(S_t) \leftarrow V(S_t) + \alpha(R_{t+1} + \gamma V(S_{t+1}) - V(S_t)) \tag{1.6}
V(St)←V(St)+α(Rt+1+γV(St+1)−V(St))(1.6)
值函数逼近
之前介绍方法都是基于表格的强化学习,其维数为状态的个数,算法更新的是表格中具体状态下值函数的值。
在状态空间很大或者状态连续时无法使用网格进行表示,此时需要用到值函数逼近的方法逼近值函数。
本节中学习的是参数化值函数逼近。
其中参数化的意思是:
- 在线性逼近时值函数由一组函数(基函数)和一组参数组成,记为 v ( s , θ ) v(s,\theta) v(s,θ),更新的过程为更新参数向量 θ \theta θ的值;
- 在非线性逼近时值函数一般由神经网络表示。
值函数的形式
首先在此给出线性逼近时的基函数表达式,这样后面看问题更加具体。
常用的基函数组:
- 多项式基函数
( 1 , s 1 , s 2 , s 1 2 , s 2 2 , ⋯ ) (1, s_1, s_2, s_1^2, s_2^2, \dotsb) (1,s1,s2,s12,s22,⋯) - 傅里叶基函数
ϕ i ( s ) = c o s ( i π s ) , s ∈ [ 0 , 1 ] \phi_{i}(s)=cos(i\pi s),s\in[0,1] ϕi(s)=cos(iπs),s∈[0,1] - 径向基函数
ϕ i ( s ) = e x p ( − ∣ ∣ s − c i ∣ ∣ 2 2 δ i 2 ) \phi_{i}(s)=exp(-\frac{||s-c_i||^2}{2\delta_i^2}) ϕi(s)=exp(−2δi2∣∣s−ci∣∣2)
此时值函数的表达式为:
v
^
(
s
,
θ
)
=
θ
T
ϕ
(
s
)
(2)
\hat{v}(s,\theta) = \theta^{T}\phi(s) \tag{2}
v^(s,θ)=θTϕ(s)(2)
其中:
- θ T \theta^{T} θT为参数向量,n维
- ϕ ( s ) \phi(s) ϕ(s)为基函数组,n维
逼近过程
值函数的逼近是一个监督学习的过程,其输入数据为
s
t
s_t
st,即当前的状态;相应的标签为
U
t
U_t
Ut。其中,
U
t
U_t
Ut在蒙特卡罗方法中为
G
t
G_t
Gt,在时间差分法中为
r
+
γ
Q
(
s
′
,
a
′
)
r+\gamma Q(s^{'},a^{'})
r+γQ(s′,a′),在TD(λ)中为
G
t
λ
G^{\lambda}_t
Gtλ
训练目标为:
a
r
g
m
i
n
θ
(
q
(
s
,
a
)
−
q
^
(
s
,
a
,
θ
)
)
2
(3)
argmin_{\theta}(q(s,a)-\hat{q}(s,a,\theta))^2 \tag{3}
argminθ(q(s,a)−q^(s,a,θ))2(3)
需要说明的是,不同于表格型强化学习只更新当前状态 s t s_t st处的值函数,值函数逼近法在更新参数时会导致所有状态下值函数的改变!
值函数具体的更新方法有增量式学习和批方法。
增量式学习:随机梯度下降
在该方法下的参数随机梯度更新公式为:
θ
t
+
1
=
θ
t
+
α
[
U
t
−
v
^
(
s
t
,
θ
t
)
]
∇
θ
v
^
(
s
t
,
θ
)
(3.1)
\theta_{t+1}=\theta_{t}+\alpha[U_t-\hat{v}(s_t,\theta_{t})]\nabla_{\theta}\hat{v}(s_t,\theta) \tag{3.1}
θt+1=θt+α[Ut−v^(st,θt)]∇θv^(st,θ)(3.1)
其中:
- θ t + 1 \theta_{t+1} θt+1、 θ t \theta_{t} θt均为n维向量;
- ∇ θ v ^ ( s t , θ ) \nabla_{\theta}\hat{v}(s_t,\theta) ∇θv^(st,θ)为对 v ^ ( s t , θ ) \hat{v}(s_t,\theta) v^(st,θ)求关于 θ \theta θ的梯度,此时 s t s_t st为确定值;
- α \alpha α为学习率,需要设定较小的值。
关于 α \alpha α较小取值的解释:逼近的值函数并不需要在各状态下都能达到最精确的值,而是要在整体上平衡所有不同状态的误差,因此需要较小的值。
对于蒙特卡罗方法,需要按照策略产生多组数据(从起始状态到最终状态的完整过程),然后根据各组数据迭代更新值函数参数。假设一组数据为
<
s
1
,
G
1
>
,
<
s
2
,
G
2
>
,
<
s
3
,
G
3
>
…
<s_1,G_1>,<s_2,G_2>,<s_3,G_3>\dotsc
<s1,G1>,<s2,G2>,<s3,G3>…,此时需要按照下述公式更新值函数:
Δ
θ
=
α
(
G
t
−
v
^
(
s
t
,
θ
)
)
∇
θ
v
^
(
s
t
,
θ
)
(3.2)
\Delta \theta = \alpha(G_t-\hat{v}(s_t,\theta))\nabla_{\theta}\hat{v}(s_t,\theta) \tag{3.2}
Δθ=α(Gt−v^(st,θ))∇θv^(st,θ)(3.2)
算法描述为:

对于时间差分法,由于TD(0)方法中
U
t
=
R
t
+
1
+
γ
v
^
(
s
t
+
1
,
θ
)
U_t = R_{t+1} + \gamma \hat{v}(s_{t+1},\theta)
Ut=Rt+1+γv^(st+1,θ),目标值函数与估计的值函数均含θ。如果只考虑估计的值函数中θ,则该方法为半梯度法。此时的θ更新公式为:
θ
t
+
1
=
θ
t
+
α
[
R
+
γ
v
^
(
s
t
+
1
,
θ
)
−
v
^
(
s
t
,
θ
t
)
]
∇
θ
v
^
(
s
t
,
θ
)
)
(3.3)
\theta_{t+1}=\theta_{t}+\alpha[R + \gamma \hat{v}(s_{t+1},\theta)-\hat{v}(s_t,\theta_{t})]\nabla_{\theta}\hat{v}(s_t,\theta)) \tag{3.3}
θt+1=θt+α[R+γv^(st+1,θ)−v^(st,θt)]∇θv^(st,θ))(3.3)
基于半梯度的TD(0)算法描述为:

疑问:
- 公式3.3的中间出现了 θ \theta θ。但没明确说明这是哪个时刻的。我的理解是 θ t \theta_{t} θt,因为计算完 θ t + 1 \theta_{t+1} θt+1之前只能使用旧值。
基于半梯度的Sarsa算法描述为:

总结一下几种方法的θ更新公式:

批方法
批的方法计算复杂,效率更高。
















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









