







需要源码请点赞关注收藏后评论区留言~~~
参数化策略
策略梯度法也是直接优化策略的方法,它先参数化策略,并把累积回报作为目标函数,然后用梯度上升法去优化参数使目标函数取得最大值,从而得到最优策略。
将策略确定为一个包含待定参数向量θ的函数π_θ:π_θ(a│s)=P(A_t=a│S_t=s,θ)
常用的策略参数化方法有Softmax策略和高斯策略,前者用于动作空间较小的离散型强化学习中,后者可应用于连续型强化学习中。
Softmax策略
Softmax策略先定义一个偏好函数ℎ(s,a,θ),该函数可看作用一组参数θ去拟合在状态s执行动作a的概率。为了符合概率取值的要求,用Softmax函数来归一化每一(s,a)对的偏好值,得到拟合的策略π_θ(a│s):
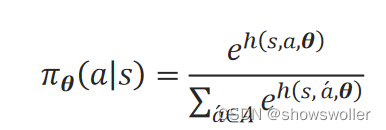
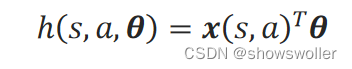
高斯策略
高斯策略认为在状态s执行动作a的概率服从高斯分布。该高斯分布的均值由θ根据状态s来拟合,记为偏好函数u(s,θ)。它的方差σ^2也可根据状态s来拟合,也可以设为固定值。
在状态s执行动作a的概率服从该高斯分布:a~N(u(s,θ),σ^2)
此时,策略函数π_θ(a│s)可表示为:
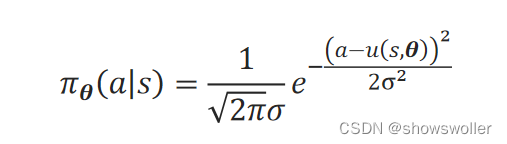
目标函数
1)将目标函数看作是指定初始状态s_0(如冰湖问题)在策略π_θ下累计回报的期望,即s_0的状态值函数:J(θ)=E_π_θ[G|s_0┤]=V_π_θ(s_0)
2)在没有明确初始状态时(如倒立摆控制问题),将目标函数看作是每个状态的累积回报的期望:J(θ)=∑_s▒d_π_θ(s)G_s
3)在没有终止状态的问题中,将目标函数看作是任一时间步的平均立即回报:
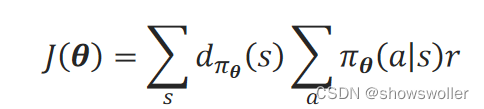
梯度
策略梯度法,实际上就是用梯度上升法去求得使目标函数最大时的策略参数θ。梯度上升法的迭代关系式为:
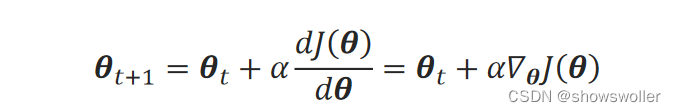
其中,∇_θJ(θ)是目标函数关于系数θ的梯度:
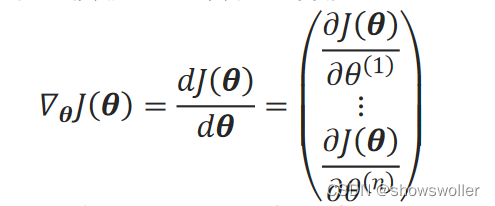
三种目标函数对θ的梯度∇_θJ(θ)都可表示为:
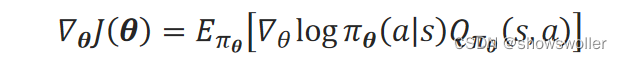
当采用Softmax策略、偏好函数ℎ(s,a,θ)采用线性函数时,可以证明分值函数∇_θlogπ_θ(a│s)为:
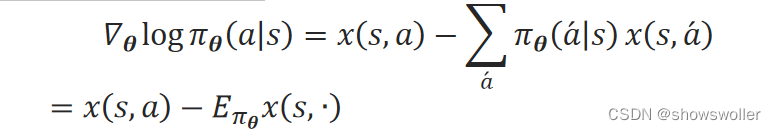
当采用高斯策略、偏好函数ℎ(s,a,θ)采用线性函数时,可以证明分值函数∇_θlogπ_θ(a│s)为:
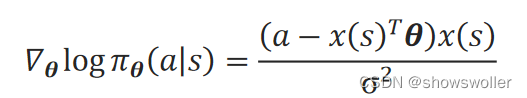
动作值函数Q_π_θ(s,a)可采用蒙特卡罗法或时序差分法来求得。
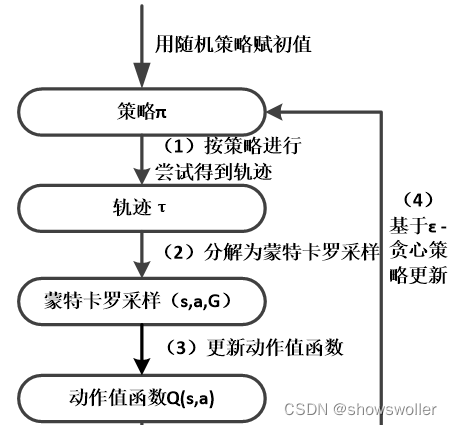
蒙特卡罗策略梯度法
当采用蒙特卡罗法时,通过尝试得到的轨迹τ,从轨迹τ中得到一系列采样。用单个采样(s_t,a_t,G_t)来近似计算策略梯度均值:
算法流程图如下
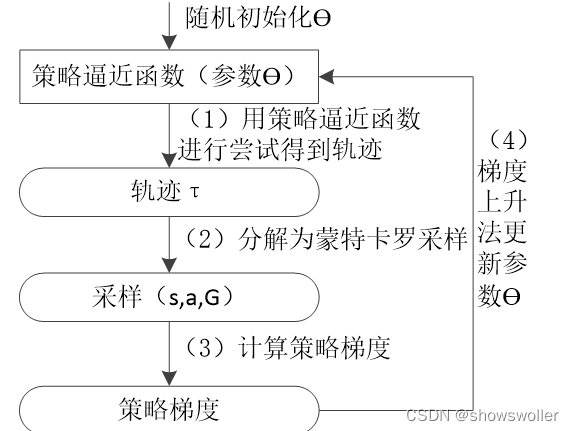
标记为(6)的操作中,要计算的累积折扣回报G_t可由轨迹的立即回报反向递推求得。
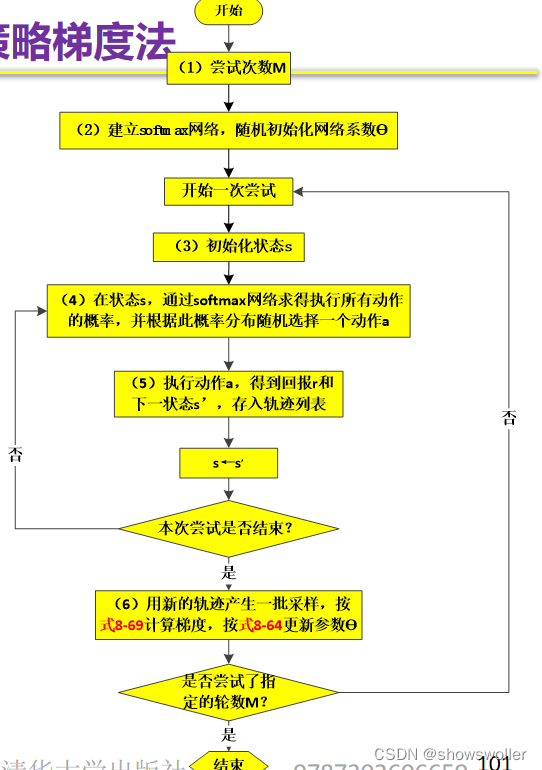
构建一个结构为(4,10,2)的全连接层神经网络,输出层的激活函数为softmax。
通过尝试得到的轨迹τ,从轨迹τ中得到一系列采样(s_t,a_t,G_t)
在求d_π_θ(s)分布下的G_s的期望时,可用按d_π_θ(s)分布进行采样得到的G_s的样本的均值来近似。 网络的训练样本的标签设为[G_t,0]或[0,G_t]
训练结果如下
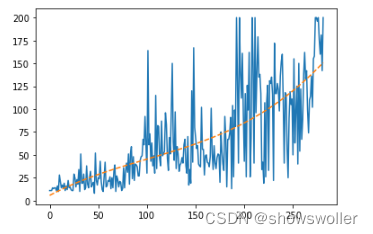
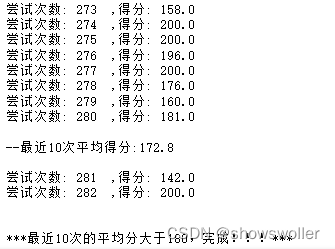
部分代码如下
# Softmax网络
model_softmax = keras.models.Sequential([
layers.Dense(10, input_dim=env.observation_space.shape[0], activation='relu'),
layers.Dense(env.action_space.n, activation="softmax")
])
model_softmax.compile(loss='mean_squared_error', optimizer=optimizers.Adam(0.001))
n_episodes = 1000
episode_score_list = []
for i in range(n_episodes):
s = env.reset()
score = 0 # 记每次得分
tau = []
while True:
pi_s = model_softmax.predict( np.array([s]) )[0] # 状态s的策略
a = np.random.choice( len(pi_s), p=pi_s ) # 按概率大小随机确定要执行的动作
next_s, r, done, _ = env.step( a )
tau.append( [s, a, r] )
score += r
s = next_s
if done:
break
X = [ step[0] for step in tau ]
y = [ [1 if step[1] == i else 0 for i in range(env.action_space.n)] for step in tau ]
G = G_seq( [step[2] for step in tau] )
model_softmax.fit(np.array(X), np.array(y), sample_weight=np.array(G), epochs=10, verbose=0)
episode_score_list.append(score)
print('尝试次数:', i+1, ' ,得分:', score)
# 10次尝试后,输出中间信息
if (i+1) % 10 == 0:
print("\n--最近{}次平均得分:{:.1f}\n".format(10, np.mean(episode_score_list[-10:]) ) )
# 最近10次的平均分大于180时,不再训练
if np.mean(episode_score_list[-10:]) > 180:
print("\n\n***最近10次的平均分大于180,完成!!!***")
break创作不易 觉得有帮助请点赞关注收藏~~~
















 2808
2808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











