







需要全部代码请点赞关注收藏后评论区留言私信~~~
K-Mean算法,即 K 均值算法,是一种常见的聚类算法。算法会将数据集分为 K 个簇,每个簇使用簇内所有样本均值来表示,将该均值称为“质心”。
K-Means++,算法受初始质心影响较小;表现上,往往优于 K-Means 算法;与 K-Means算法不同仅在于初始质心的选择方式不同
Mini Batch K-Means
与 K-Means 算法相比,大大减少计算时间
算法步骤
容易受初始质心的影响;算法简单,容易实现;算法聚类时,容易产生空簇;算法可能收敛到局部最小值。
通过聚类可以实现:发现不同用户群体,从而可以实现精准营销;对文档进行划分;社交网络中,通过圈子,判断哪些人可能互相认识;处理异常数据。
距离计算方式是 欧式距离。
1.从样本中选择 K 个点作为初始质心(完全随机) 2.计算每个样本到各个质心的距离,将样本划分到距离最近的质心所对应的簇中 3.计算每个簇内所有样本的均值,并使用该均值更新簇的质心 4.重复步骤 2 与 3 ,直到达到以下条件之一: 质心的位置变化小于指定的阈值(默认为 0.0001) 达到最大迭代次数
K-Means算法文本聚类实战
文本聚类结果如下


部分代码如下
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
def jieba_tokenize(text):
return jieba.lcut(text)
tfidf_vect = TfidfVectorizer(tokenizer=jieba_tokenize, lowercase=False)
text_list = ["中国的
害","他很高兴去中国工作","真是一个高兴的周末","这件衣服太不舒服啦"]
#聚类的文本集
tfidf_matrix = tfidf_vect.fit(text_list) #训练
print(tfidf_matrix.vocabulary_) #打印字典
tfidf_matrix = tfidf_vect.transform(text_list) #转换
arr=tfidf_matrix.toarray() #tfidf数组
print('tfid
n',arr)
num_clusters = 4
km = KMeans(n_clusters=num_clusters, max_iter=300, random_state=3)
km.fit(tfidf_matrix)
prt=km.predict(tfidf_matrix)
print("Predicting result: ", prt)对半环形数据集进行K-Means聚类
问题描述: SKlearn中的半环形数据集make_moons是一个二维数据集,对某些算法来说具有挑战性。数据集中的数据有两类,其分布为两个交错的半圆,而且还包含随机的噪声
聚类结果如下
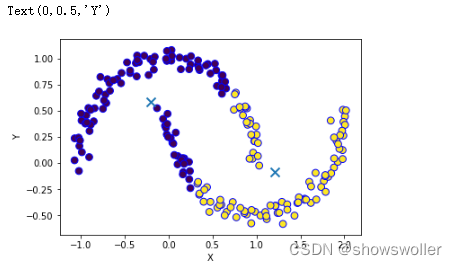
部分代码如下
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_moons
#生成环形数据集
X, Y = make_moons(n_samples=200, noise=0.05, random_state=0)
#使用K-Means聚成两类
kmeans = KMeans(n_clusters=2)
kmean(X)
Y_pred = kmeans.predict(X)
#绘制聚类结果图
plt.scatter(X[:, 0], X[:, 1], c=Y_pred, s=60, edgecolor='b')
plt.scatter(kmeans.clustedth=2, edgecolor='k')
plt.xlabel("X")
plt.ylabel("Y")创作不易 觉得有帮助请点赞关注收藏~~~
















 1022
1022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











