







 本文详细概述了基于深度学习的可见光与红外图像融合(VIF)技术,包括其动机、分类、发展特点、数据集、评估方法和未来前景。重点介绍了CNN、AE、GAN和Transformer等在VIF中的应用,以及VIF在目标检测、场景分割等领域的作用。
本文详细概述了基于深度学习的可见光与红外图像融合(VIF)技术,包括其动机、分类、发展特点、数据集、评估方法和未来前景。重点介绍了CNN、AE、GAN和Transformer等在VIF中的应用,以及VIF在目标检测、场景分割等领域的作用。
@article{zhang2023visible,
title={Visible and Infrared Image Fusion Using Deep Learning},
author={Zhang, Xingchen and Demiris, Yiannis},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
year={2023},
publisher={IEEE}
}
SCI1区;IF 23.6
文章目录
Abstract
- 可见光与红外光图像融合(Visible and infrared image fusion ,VIF)可以应用在目标检测及跟踪、场景分割以及人群技术等任务。
- 除了传统方法外,近年来还提出了以下方法:
- CNN
- AE(AutoEncoder)
- GAN
- transformer
- 综述详细的分析了动机、分类、近期发展特征、数据集、性能评估方法以及未来前景
Index Terms
- Deep learning
- image fusion
- multimodal fusion
- RGB-T
- visible-infrared image fusion
1. 介绍
VIF近年很热门,是因为可见与红外光的互补特性决定的,且该技术有多项应用。可见光图像包含丰富的纹理特征、但是对光照敏感。红外光图像则相反。VIF目的是为了融合两种图像来结合更多的信息以此促进下游应用。
如图1所示。

VIF按照监督方法可以分为有监督和无监督,按照基于深度学习的方法可以分为CNN、AE、GAN、transformer等。如图三所示。
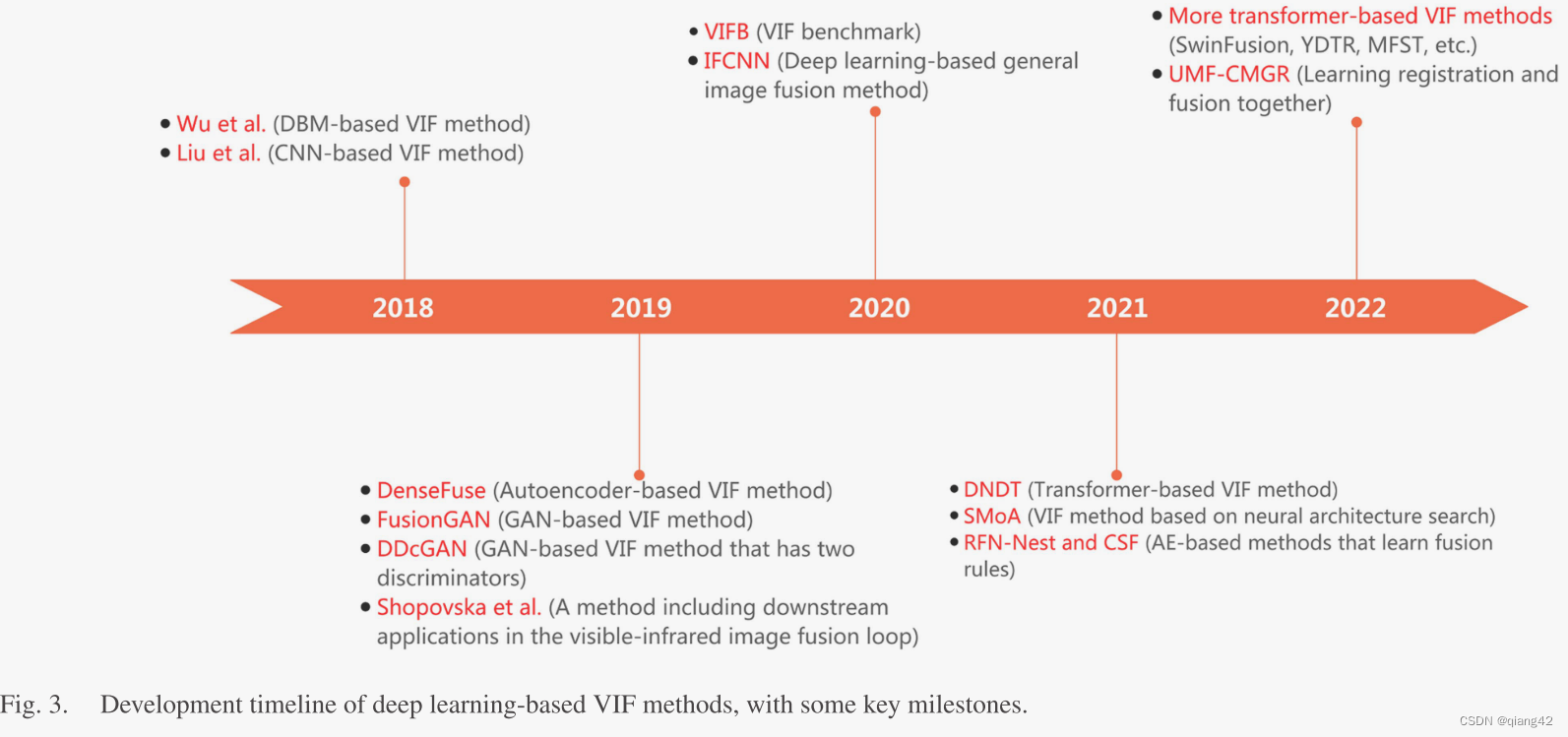
本文贡献
- 基于深度学习方法的全面综述
- 总结出了200多篇论文的最新全面发展特点
- 详细讨论了VIF的未来前景
2. 基于深度学习的可见光-红外图像融合方法
2.1 背景
图像融合包括:
- 可见光(VI)-红外(IR)图像融合,visible-infrared image fusion (VIF)
- 多焦距图像融合,multi-focus image fusion (MFIF)
- 多曝光图像融合,multi-exposure image fusion (MEF)
- 医学图像融合,medical image fusion (MEDIF)
- 遥感图像融合,remote sensing image fusion
VIF可以在三个级别进行融合,分别是: - 像素级,pixel-level:融合->下游任务
- 特征级,feature-level:特征提取->融合->下游任务
- 决策级,decision-level:应用程序分别在IR和VI得到子结果->融合子结果生成最终结果
2.2 将深度学习引入VIF的动机
VIF通常为三个阶段:特征提取(feature extraction)、特征融合(feature fusion)和图像重建(image reconstruction)
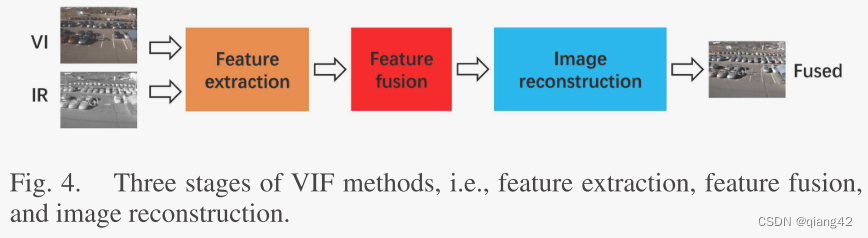
2.3 基于深度学习的VIF方法分类
- 训练时是否有ground truth:有监督、无监督
- 模型类型:CNN、AE、GAN、Transformer
- 是否包含手动设计步骤:端到端、非端到端
- 全卷积、非全卷积
- 网络架构:单分支和多分支。如图5
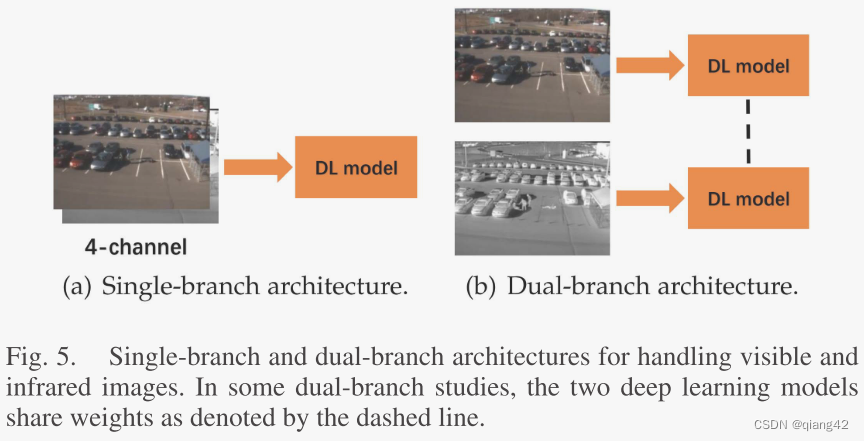
2.4 基于CNN的VIF
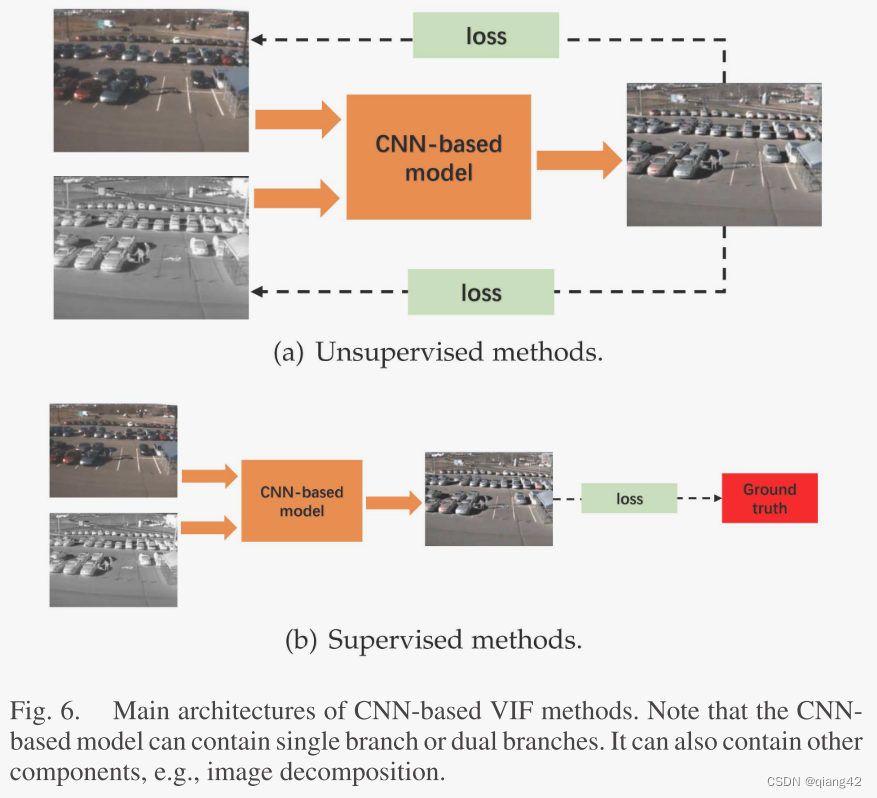
非监督损失函数通常使用融合图像和源图像来定义,包含了图像融合评价指标所构建的项。
- CNN既可以用在VIF的部分阶段,也可以用于全部阶段
- 提升性能的一些方法
- 残差连接,Residual Connection
- 密集连接,Dense Connection
- 注意力机制,Attention Mechanism.
- 多尺度特征,Multiscale Features(大小卷积核)
- 多层次特征,Multilevel Features(将源图像分为基础层和细节层)
- 对比学习,Contrastive Learning
- 神经架构搜索,Neural Architecture Search(自动学习网络架构,如SMoA、NAS)
- 图像或特征分解,Image or Feature Decomposition(如将图像分解为基础部分和细节部分)
- 照明感知模块,Illumination-Aware Module(PIAFusion)
- 其他类型的卷积,Other Types of Convolutions
2.5 基于AE的VIF
步骤:
- 使用可见图像和/或红外图像对自动编码器进行预训练,如图 7(a) 所示。
- 训练好的编码器用于特征提取,训练的解码器用于图像重建,如图7(b)所示。
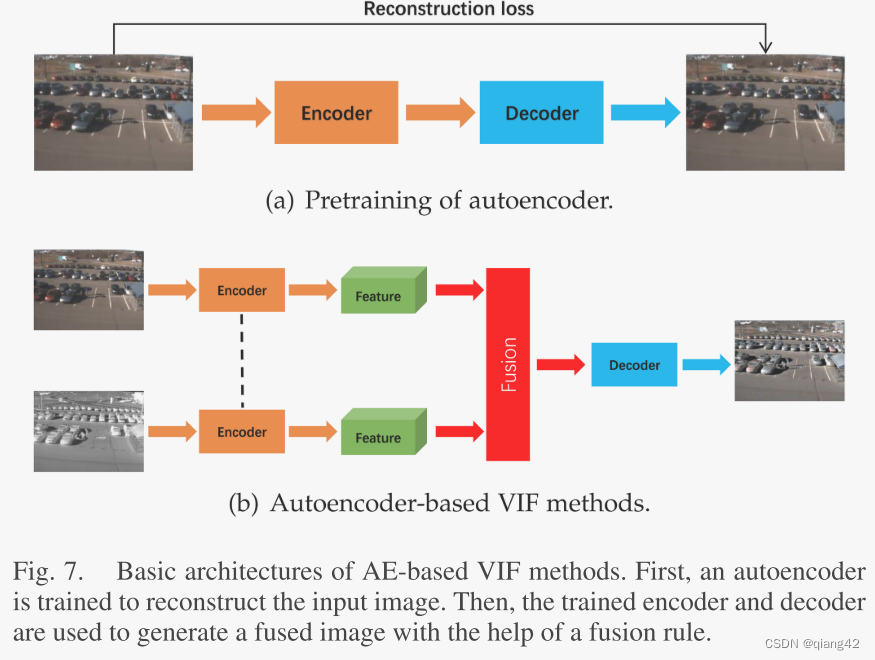
基于AE的方法的特征融合步骤是根据手动融合规则执行的,这可能不是很有效。
2.6 基于GAN的VIF
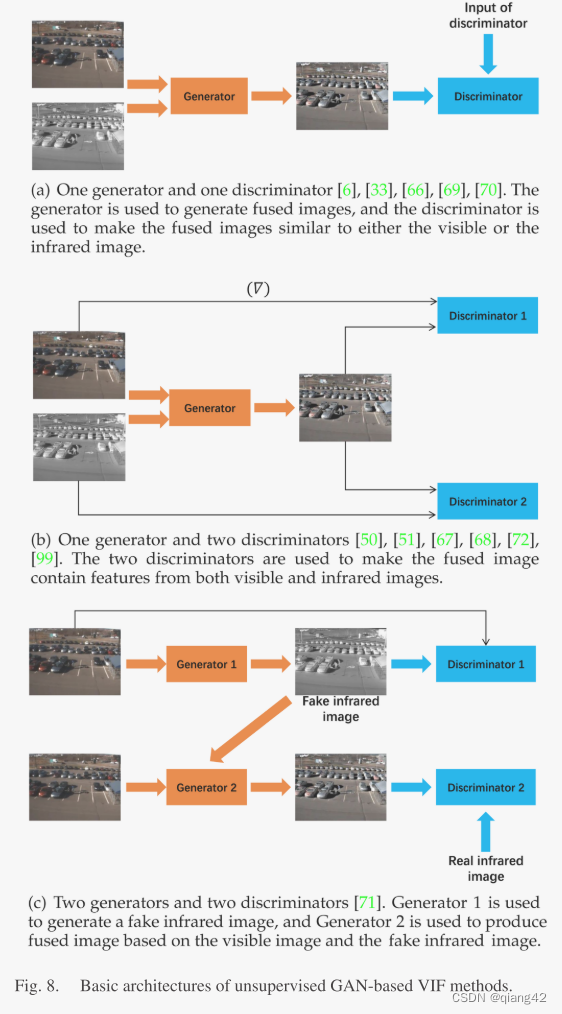
大多数基于 GAN 的 VIF 方法都是无监督方法。训练通常由损失函数驱动,该函数比较融合图像与源图像的差异。根据生成器和判别器的数量讨论这些方法,如图 8 所示。
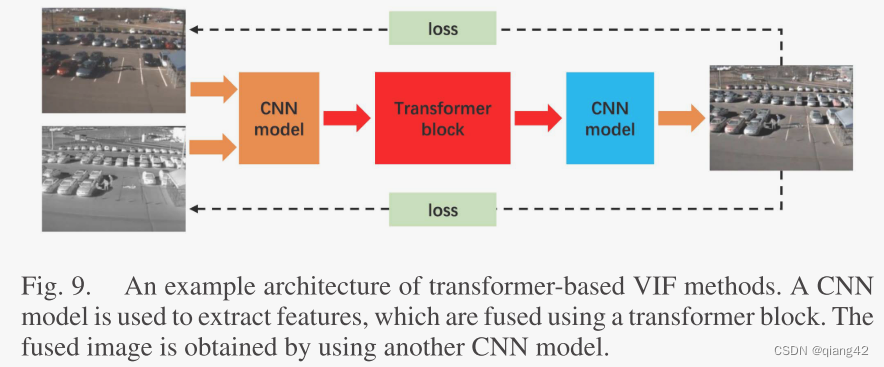
2.6 基于Transformer的VIF
3. 通用图像融合方法
在一般的图像融合方法中,通常采用相同的模型来执行不同的融合任务。一般的图像融合方法使用起来很方便,因为它们可以执行多种图像融合任务。一些方法还可以利用各种图像融合任务之间的共同特征。然而,不同的图像融合任务具有非常不同的特征,因此需要考虑不同的关键点才能获得良好的融合性能。
例如,在 VIF 中,保留可见图像中的纹理细节和红外图像中的显着信息至关重要。在MFIF中,找到聚焦区域和散焦区域之间的边界并正确处理散焦扩散效应(DSE)至关重要。在MEF中,消除光晕效应和鬼影效应至关重要。
4. 近期发展特点
4.1 基于深度学习的VIF模型越来越多
4.2 大多数方法都是无监督方法
VIF 中没有ground truth,而在 MFIF 和 MEF 中有ground truth
4.3 深度学习与传统图像处理技术的结合
4.4 VIF与其他任务的结合
4.5 结合图像融合和配准
由于可见光和红外图像的成像机制不同以及可见光和红外相机的参数不同,精确对准可见红外图像对是很困难的。已经提出了许多方法来执行可见红外图像配准,然而,几乎所有这些研究都没有考虑图像融合任务。
4.6 不同分辨率图像的 VIF 方法
大多数现有的 VIF 方法旨在融合相同分辨率的可见光和红外图像。然而,实际中更常见的是高分辨率的可见光图像和低分辨率的红外图像。
4.7 Benchmarks研究
与计算机视觉中的许多任务不同,图像融合长期以来一直缺乏基准。第一个可见红外图像融合基准(VIFB),它由21个可见红外图像对的测试集、20个VIF方法的代码库和13个评估指标组成。 VIFB 已被许多 VIF 研究采用
4.8面向应用的 VIF 方法
大多数现有的VIF方法没有考虑图像融合过程中的下游应用,如图10(a)所示。可能看着融合效果好、评价指标高,但是对下游应用任务并不是最佳的。
4.9 损失函数中的不同项
事实上,几乎所有基于深度学习的 VIF 方法都包含根据图像融合评估指标设计的损失项。请注意,大多数基于深度学习的 VIF 方法的损失函数仅考虑图像融合性能。因此,我们将这种损失函数称为VIF损失,如图10(a)所示。然而,正如张等人所证明的那样。VIF方法在不同类型的图像融合评估指标(例如基于结构的指标和基于信息论的指标)方面可能具有非常不同的性能。因此,单一基于度量的 VIF 损失不足以训练良好的 VIF 方法。
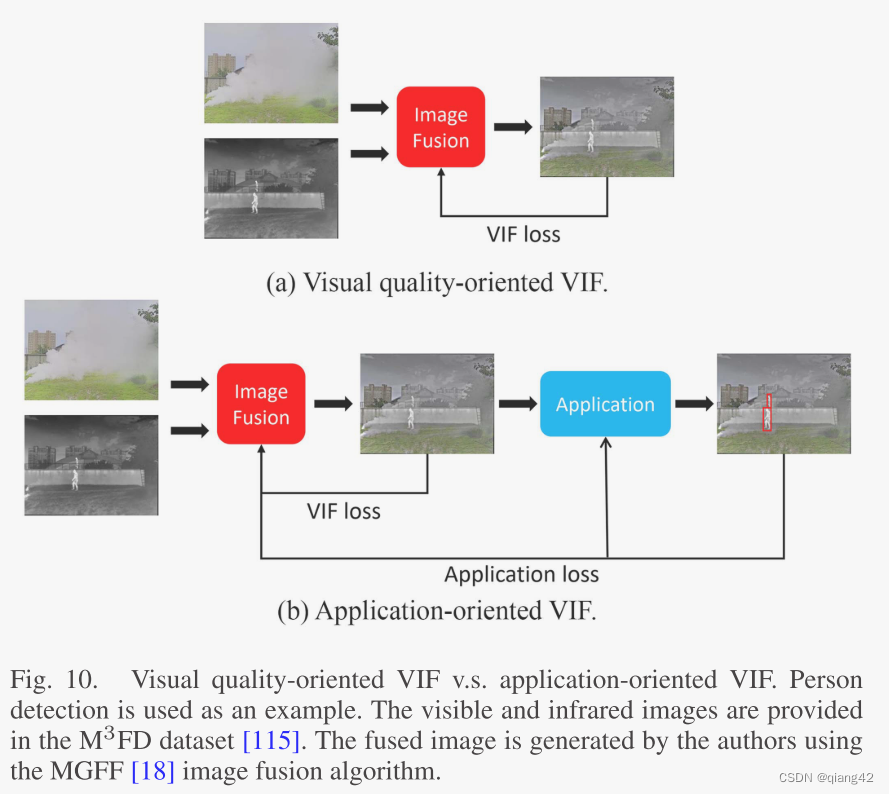
大多数现有的 VIF 方法仅使用 VIF 损失。然而,更有前途的方法是同时使用 VIF 损失和应用程序损失。值得一提的是,应用程序损失通常是在网络输出和应用程序的真实情况之间计算的。相反,VIF 损失通常是在融合图像和源图像或伪真实图像之间计算的。
4.10 可以直接融合彩色图像的方法
大多数 VIF 方法只能融合灰度图像。为了融合彩色图像,这些方法首先将 RGB 图像转换到 YCbCr 空间,然后将 Y 通道与红外图像融合。然后应用逆颜色空间变换以获得颜色融合图像。然而,这个过程很复杂。此外,大多数方法仅使用深度学习方法融合Y通道,而使用传统方法(例如手动方法)融合Cr和Cb通道。这可能会导致信息丢失,因为 Cb 和 Cr 通道也包含重要信息。
4.11 编程框架
Pytorch已成为基于深度学习的VIF方法中最流行的编程框架。
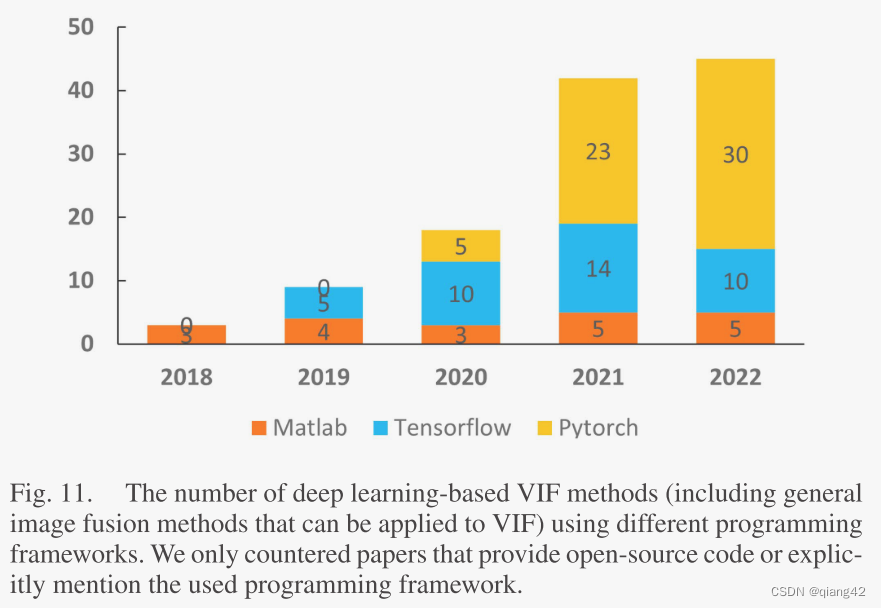
5. 数据集
5.1 训练数据
VIF中没有ground truth
- 有监督训练
- 使用其他方法生成的融合图像作为ground truth,这种方法可能会设定学习的上限
- 使用全清晰图像及其模糊版本。这种方式生成的训练数据不太真实,与真实的可见光-红外图像对不同。
- 对现有 VIF 数据集使用手动标记的对象掩码。这些mask是劳动密集型的,而且获取起来并不方便。
- 使用下游应用的标签。
- 使用 YCbCr 空间中 RGB 图像的 Y 通道作为ground truth
- 无监督训练
- 可见光-红外图像对
- 可见光和红外图像,但它们不一定是对。
- 全清晰可见光图像,主要用于基于AE的方法
- 可见光图像加可见光-红外图像对。在这种情况下,可见光图像和可见光-红外图像对用于训练模型的不同模块。
- 迁移学习,即使用用大规模 RGB 数据集训练的预训练模型
5.2 测试数据
TNO、INO、MFNet、RoadScene、VIFB、LLVIP 和 M3FD
一般来说,VIF领域没有完善的测试集,如表II所示。
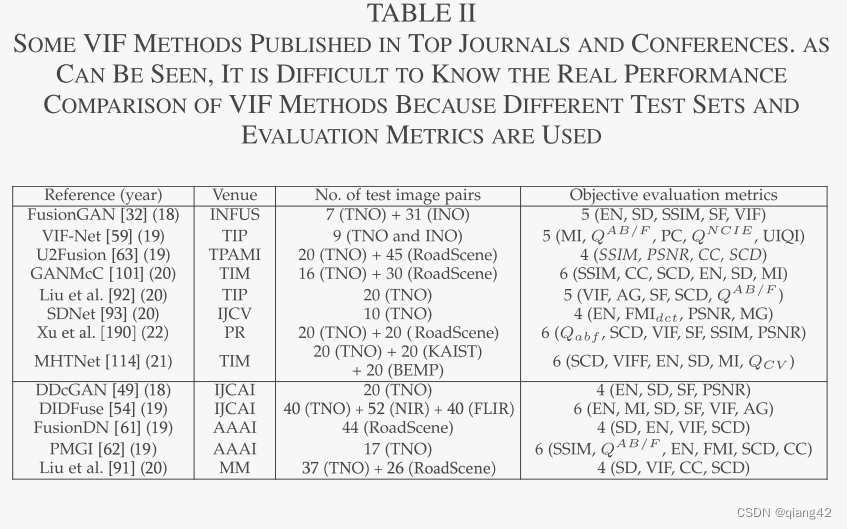
5.2 其他包含可见-红外光图像的数据集
CVC-14和FLIR 为驾驶场景提供可见光-红外图像对。然而,这些数据集中的图像并未对齐。
GTOT、RGBT234和LasHeR主要用于RGBT跟踪。它们提供大量可见光-红外图像对。然而,这些数据集中可见红外图像的对齐不是很准确。
多光谱KAIST是一个多光谱数据集,主要用于多光谱行人检测。此外,OSU数据集是VIF中使用的早期数据集。
6. 性能评估方法
6.1 定性评价
定性评估是指通过手动和目视检查融合图像的质量。通常,融合图像应包含可见图像的纹理细节和红外图像的显着特征。
6.2 定量评价
定量评估是指使用图像融合评估指标来检查融合图像的质量。已经提出了许多评估指标,例如交叉熵(CE)[187]、空间频率(SF)和归一化互信息(NMI)。然而,大多数 VIF 研究中并没有使用一个公认的指标。此外,每个指标通常从一个方面或非常有限的方面部分评估融合图像的质量。这导致了一个重要问题,即不同的 VIF 研究可能使用不同的指标,如表 II 所示。此外,在现有的VIF文献中,也使用了不同的测试集。因此,公平地比较 VIF 方法的性能是相当困难的。
7. 前景
7.1 更好的评估指标
理想的指标应该与视觉性能一致,全面反映融合性能。
7.2 更好的benchmarks
- 最新的基于深度学习的方法在 VIFB 上并没有表现出比旧的基于深度学习的方法有优势。
- 一些传统的 VIF 方法,与基于深度学习的方法表现出非常有竞争力的定量性能,这表明基于深度学习的方法在 VIFB 上没有表现出主导性能。
- 很难从定性比较中得出哪种方法更好的结论。
7.3 基于Transformer的方法
Transformer 在许多计算机视觉任务中取得了优异的性能。开发纯基于Transformer的 VIF 方法很有趣。此外,有必要证明什么是 VIF 背景下的全局信息,这在现有的基于 Transformer 的 VIF 方法中很少得到解释。
7.4 面向应用的图像融合方法
使用 VIF 的动机之一是提高下游应用程序的性能。然而,从我们的回顾中可以看出,大多数现有的 VIF 方法都没有考虑下游应用。以这种方式设计的 VIF 方法学习的一般特征和融合规则可能无法针对下游应用进行优化。因此,在VIF方法的设计中最好考虑下游应用。图 10(b) 显示了一个可能的框架,其中 VIF 损失和应用损失都用于指导训练。
7.5 更多应用
VIF 有潜力提高许多应用的性能,特别是那些需要在各种照明条件下工作的应用。然而,VIF主要应用于对象跟踪、对象检测、显着对象检测和场景分割。许多其他应用,例如人员救援和机器人,具有很大的价值,但很少被研究。
7.6 配准方法研究
可见光和红外图像的未对准可能会降低应用程序的性能。因此,处理融合的未对准非常重要。这也将有助于促进VIF方法的应用。然而,尽管已经进行了许多研究来处理可见光和红外图像的未对准问题,但对准仍然是一个悬而未决的问题,完美对准可见光和红外图像非常具有挑战性。几乎所有现有的可见光-红外数据集都存在一些未对准的问题。
7.7 将 VIF 与其他任务相结合
在大多数 VIF 研究中,仅考虑可见光和红外图像融合。最近,一些研究人员将 VIF 和其他任务一起执行,这可能会更加有效和高效。然而,VIF与其他任务结合的研究仍然非常有限。
7.8 提高融合效率
较大的模型使得VIF方法不够高效,这阻碍了VIF方法在目标跟踪和检测等实际应用中的价值。
8. 结论
本文详细回顾了基于深度学习的可见光和红外图像融合(VIF)方法。从回顾中可以看出,自2018年以来,每年都有越来越多的基于深度学习的VIF方法被开发出来,并且各种深度学习技术已被应用于执行VIF。我们对现有方法进行了仔细分组,并介绍了代表性方法。我们还讨论了该领域近期的发展特点。此外,我们还总结了VIF数据集,包括测试数据和训练数据,以及性能评估方法。基于这些回顾和分析,我们通过分析我们认为应该引起更多关注的几个重要问题来讨论VIF的未来前景。我们希望本研究可以为该领域的研究人员提供适当的参考
🚀传送门
📑图像融合相关论文阅读笔记
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[Visible and Infrared Image Fusion Using Deep Learning]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📚图像融合论文baseline总结
📑其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~



















 4716
4716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











