







[原文地址]🚀🚀🚀(https://www.sciencedirect.com/science/article/abs/pii/S156625352200032X)
SCI 1区;IF 18.6;武汉大学;2022年7月;《Information Fusion》
文章目录
Abstract
红外和可见光图像融合旨在即使在极端照明条件下也能合成包含显着目标和丰富纹理细节的单个融合图像。然而,现有的图像融合算法在建模过程中未能考虑光照因素。
本文提出了一种基于光照感知的渐进式图像融合网络PIAFusion:
- 设计了一个照明感知子网络用来估计光照并计算照光照概率
- 利用光照概率构建光照感知损失来指导融合网络训练
- 发布了多光谱道路场景的数据集MSRS
达到了SOTA效果,并在语义分割任务中也有优秀的表现
Keywords
Image fusion图像融合
Illumination aware光照感知
Cross-modality differential aware fusion跨模态差分感知融合
Deep learning 深度学习
Introduction
单模态图像不能充分全面描绘场景信息,因此融合使用多模态传感器采集的图像有重要意义。图像融合可以分为多模态融合及数字图像融合。
多模态融合中红外与可见光图像融合在军事、目标检测及跟踪、行人重识别等方面具有重要意义。红外图像可以高效捕获热目标(例如行人)但却忽略或者误判了其他物体(例如静态车辆、自行车)。相反,可见光图像可以捕获更多信息但是对黑暗或者烟雾后的目标捕获不佳。如图1所示。

图像融合技术可以分为两种:传统方法及数据驱动的方法。
传统方法
利用数学转换来将源图像转化至变换域并进行活动水平测量(特征提取?)及设计融合规则来实现图像融合。主要的方法有基于多尺度分解的方法、基于子空间的方法、基于稀疏表达的方法、基于优化的方法以及混合方法。主要缺点为:
- 为了更好的效果而使用过于复杂的算法,实时性不佳
- 人工设计的活动水平测量难以应对复杂场景
数据驱动的方法
AE自编码器
训练自编码器用于特征提取和特征重建。但是融合规则是人工设计的,因此并不可以完全学习(not fully learnable)。
CNN
使用优秀的网络结构及精心设计的损失函数确保融合性能。
GAN
图像融合任务缺乏ground truth,因此诞生了基于生成对抗网络的图像融合方法用于约束从而增强融合图像中的特征纹理细节,但是太强的约束可能会引入人工纹理(artificial textures)
目前存在的问题
- 缺乏大型数据集。主流的数据集有TNO、RoadScene场景过于简单,且在TNO上训练很容易过拟合。
- 照明不平衡的问题从未被研究过。(白天可见光图像纹理好,夜间红外目标突出,如图2所示)目前的方法均认为可见光图像纹理细节丰富,但是忽略了夜间的时候并不是这样的问题,因此融合夜间图像时反而容易丢失纹理细节。

融合阶段
目前的研究更多关注如何融合特征,忽略了何时融合的问题。目前融合分为两个阶段:输入融合和中途融合(halfway fusion)。
输入融合
级联多模态输入作为融合网络的输入。可能导致网络无法融合源图像中的语义信息。
中途融合(halfway fusion)
使用特定的融合规则来融合特征提取出来的深层特征。但是不恰当的融合规则可能导致无法充分整合互补信息。
提出的方法
提出了一种基于照明感知的渐进式红外和可见光图像融合网络PIAFusion,并发布了MSRS数据集。
- 处理MFNet数据集(包含大量低对比度和低信噪比图像且未配准的语义分割数据集),剔除未对齐的图像对,锐化并增强剩余图像。
- 设计了一个照明感知子网络来评估照明条件
2.1 预训练的子网络用来计算当前图像时白天还是夜晚的概率
2.2 利用概率构建光照感知损失,以指导融合网络训练 - 采用包含跨模态差分感知融合(CMDAF)模块的渐进式特征提取器来提取合并多模态图像中的互补信息
- 通过半融合方式融合互补特征和共同特征,使用图像重建器将融合特征变化到融合图像域
本文贡献
- 提出了一种创新性的光照指导的红外可见光图像融合框架
- 将跨模态差分感知模块和中途融合策略结合以整合各阶段的共同和互补特征
- 构建了MSRS数据集
- SOTA
related work
红外及可见光图像融合
传统图像融合
特征提取、融合和重建是典型传统图像融合方法的三个基本要素。这些算法的关键在于特征提取和融合,因为特征重建是特征提取的逆操作。
AE
手工制定的融合规则严重限制了融合性能的提高。
CNN
缺乏ground truth
GAN
适合无监督任务。单个鉴别器往往会打破红外和可见光图像之间数据分布的平衡。
基于照明感知的视觉应用
用于低光图像增强的全局照明感知和细节保留网络(GLADNet)
三重多任务生成对抗网络,将不同光照的特征集成到分割分支中,这极大地提高了前景分割的性能
提高多光谱行人检测性能的可行性
基于照明感知行人检测和语义分割的多光谱行人检测框架
并没有人在图像融合中引入照明感知
Methodology
问题分析
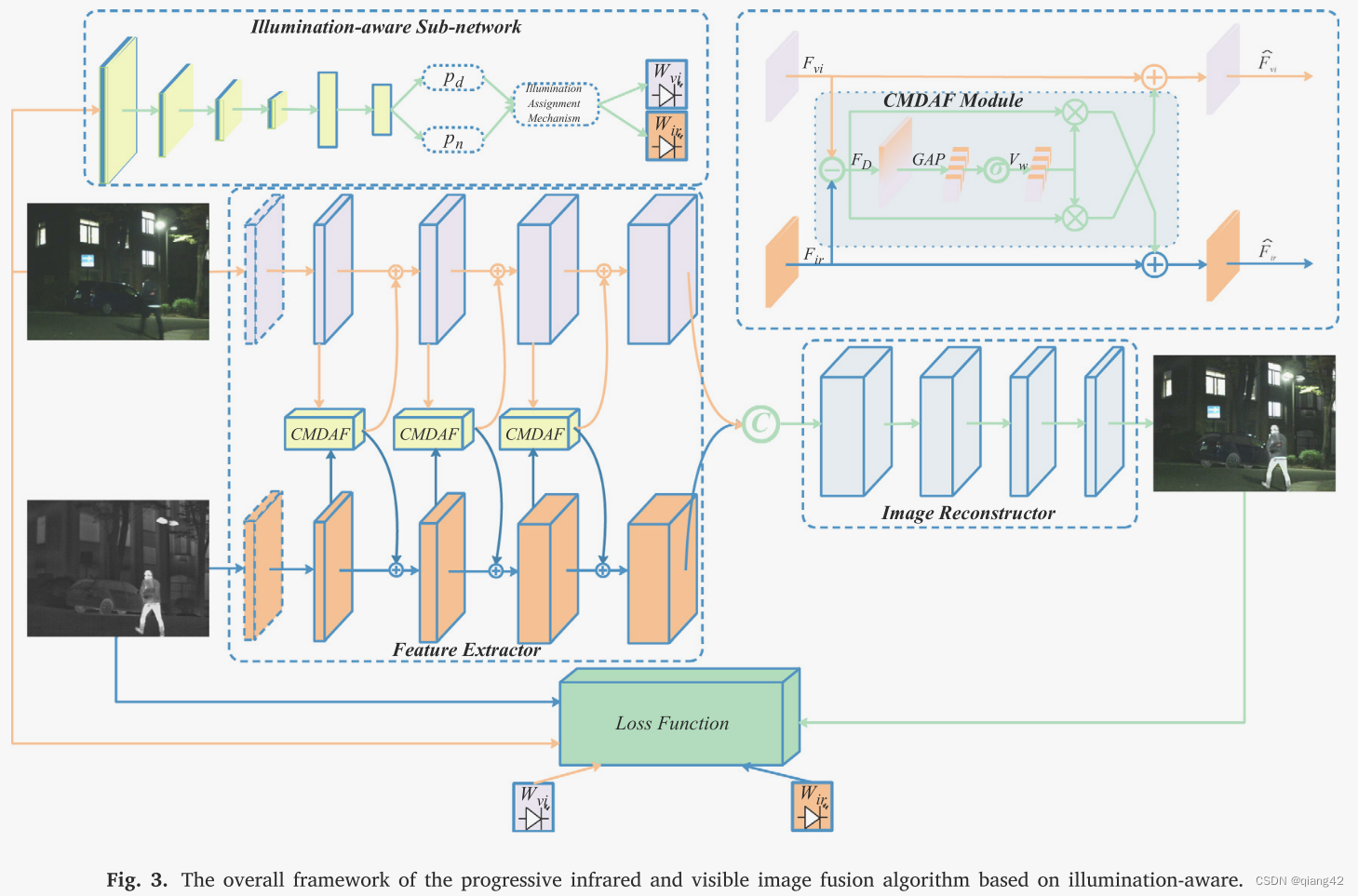
PIAFusion渐进式照明引导红外和可见光图像融合网络如图 3 所示。
红外图像
I
i
r
\ I_{ir}
Iir 可见光图像
I
v
i
\ I_{vi}
Ivi 融合图像
I
f
\ I_f
If
照明感知过程为:
{ P d , P n } = N I A ( I v i ) \{P_d, P_n\} = N_{IA}(I_{vi}) {Pd,Pn}=NIA(Ivi)
N I A \ N_{IA} NIA表示照明感知子网络。 P d \ P_d Pd和 P n \ P_n Pn分别表示图像属于白天和夜晚的概率。 P d \ P_d Pd和 P n \ P_n Pn均为非负标量。
照明分配机制采用了一个简单的归一化函数:
W
i
r
=
P
n
P
d
+
P
n
\ {W_{ir}} = \frac{{P_n}}{{P_d + P_n}}
Wir=Pd+PnPn
W
v
i
=
P
d
P
d
+
P
n
\ {W_{vi}} = \frac{{P_d}}{{P_d + P_n}}
Wvi=Pd+PnPd
W
i
r
\ W_{ir}
Wir和
W
v
i
\ W_{vi}
Wvi分别表示红外图像和可见光图像在融合过程中的贡献。
(Latex真的好难写呀,我还是截图吧🤣)
渐进式融合网络用于将共同信息和互补信息完全融合。
首先使用特征编码器
E
f
\ E_{f}
Ef从红外和可见光图像中提取深层特征:
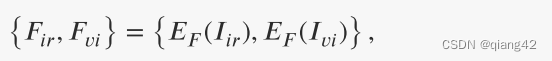
F
i
r
\ F_{ir}
Fir和
F
v
i
\ F_{vi}
Fvi分别代表红外图像特征和可见光图像特征
F
i
r
i
\ F_{ir}^{i}
Firi和
F
v
i
i
\ F_{vi}^{i}
Fvii分别代表从第i层卷积中,提取到的红外图像特征和可见光图像特征
提出了一种跨模态差分感知融合(CMDAF)模块来补偿差分信息:
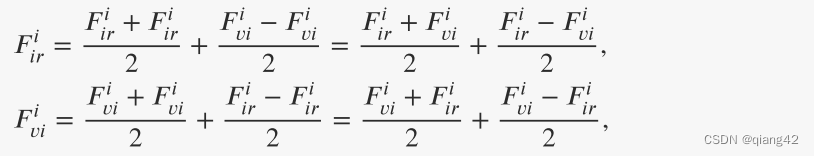
CMDAF模块可以准确定义为:
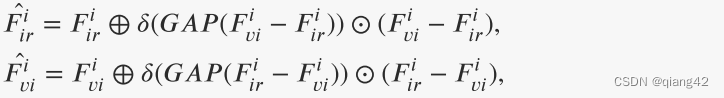
⊕表示逐元素求和
⊙表示逐通道乘法
𝛿(⋅) 和𝐺𝐴𝑃(⋅) 分别表示 sigmoid 函数和全局平均池化
上式表示全局平均池化将互补特征压缩为向量。然后,通过 sigmoid 函数将向量归一化为 [0, 1],生成通道权重。最后,将互补特征乘以通道权重,并将结果添加到原始特征中作为模态补充信息。
另外,通过半程融合的方式,即级联,将红外图像和可见光图像的共同互补特征完全融合。中途融合策略表示如下:

C(⋅) 指的是通道维度中的级联
最终,通过图像重建器
R
I
\mathcal R_I
RI从融合特征
F
f
\ F_f
Ff中恢复融合图像
I
f
\ I_f
If

损失函数
渐进式融合网络的损失函数
光照感知损失
L
i
l
l
u
m
\mathcal L_{illum}
Lillum的定义如下:
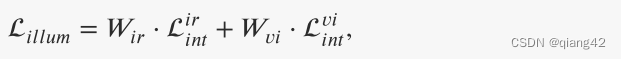
L
i
n
t
i
r
\mathcal L_{int}^{ir}
Lintir和
L
i
n
t
i
r
\mathcal L_{int}^{ir}
Lintir分别代表红外和可见光图像的强度损失。
W
i
r
\ W_{ir}
Wir和
W
v
i
\ W_{vi}
Wvi分别代表光照感知权重
强度损失衡量融合图像和源图像在像素级别上的差异。因此,我们将红外和可见光图像的强度损失定义为:
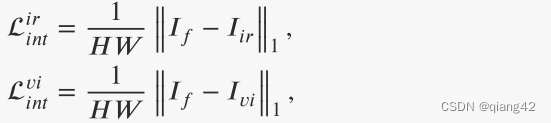
H和W是输入图像高和宽。
‖
⋅
‖
1
\ ‖⋅‖_1
‖⋅‖1代表L1范式。
根据光照情况,融合图像的强度分布应该与不同的源图像保持一致。因此,我们使用照明感知权重,即 𝑊𝑖𝑟 和 𝑊𝑣𝑖 来调整融合图像的强度约束。
照明损失驱动的渐进式融合网络根据照明条件动态保留源图像的强度信息,但它不能保持融合图像的最佳强度分布。为此,我们进一步引入辅助强度损失,其表示为:
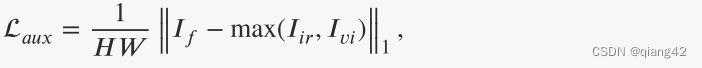
max(⋅) 表示逐元素最大选择。
融合图像的最佳纹理可以表示为红外和可见光图像纹理的最大聚合。为了使融合图像保持最佳强度分布,保留丰富的纹理细节。引入纹理损失来迫使融合图像包含更多纹理信息,其定义如下:
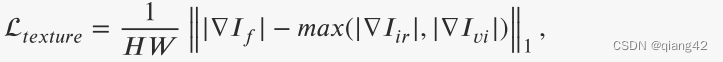
∇表示梯度算子,测量图像的纹理信息。在本文中,利用 Sobel 算子来计算梯度。 | ⋅ |指的是绝对操作。
渐进融合网络的完整目标函数是光照损失、辅助强度损失和纹理损失的加权组合,表达如下:
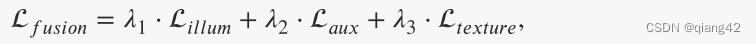
最终,渐进融合网络可以在照明损失和辅助强度损失的指导下根据照明场景动态保留最佳强度分布。并且可以在纹理损失的指导下获得理想的纹理细节。因此,融合网络可以全天候融合红外和可见光图像中的有意义的信息。
光照感知子网络的损失函数
光照感知网络本质上是一个分类器,它计算图像属于白天和夜间的概率。
采用交叉熵损失
L
I
A
N
\mathcal L_{IAN}
LIAN来约束光照感知子网络的训练过程,其表示如下:
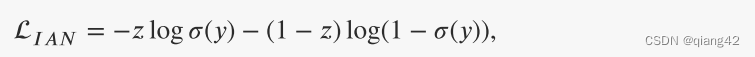
𝑧表示输入图像的光照标签,𝑦 = [𝑃𝑛, 𝑃𝑑]表示光照感知子网络的输出,𝜎指的是softmax函数,它将光照概率归一化为[0, 1]。
网络结构
采用基于 CNN 的端到端框架作为主干,渐进式网络由特征提取器和图像重建器组成。如图3所示(在上面)
特征提取器中有五个卷积层,旨在充分提取互补和共同特征。首先,设计1×1卷积层以减少红外和可见光图像之间的模态差异。因此,我们分别训练红外和可见图像的第一层。然后,采用具有共享权重的四个卷积层来提取红外和可见光图像的深层特征。值得注意的是,第2、3、4层的输出后面是CMDAF模块,用于交换模态互补特征。 CMDAF 模块使我们的网络能够以渐进的方式整合特征提取阶段的补充信息。因此,我们的特征提取器可以完全从红外和可见光图像中提取共同和互补的特征。特征提取器中所有卷积层的更多细节,例如内核大小、输出通道和激活函数,如表1所示。除第一层外,所有卷积层的内核大小均为3。特征提取器的所有层均采用 Leaky Relu 作为激活函数。
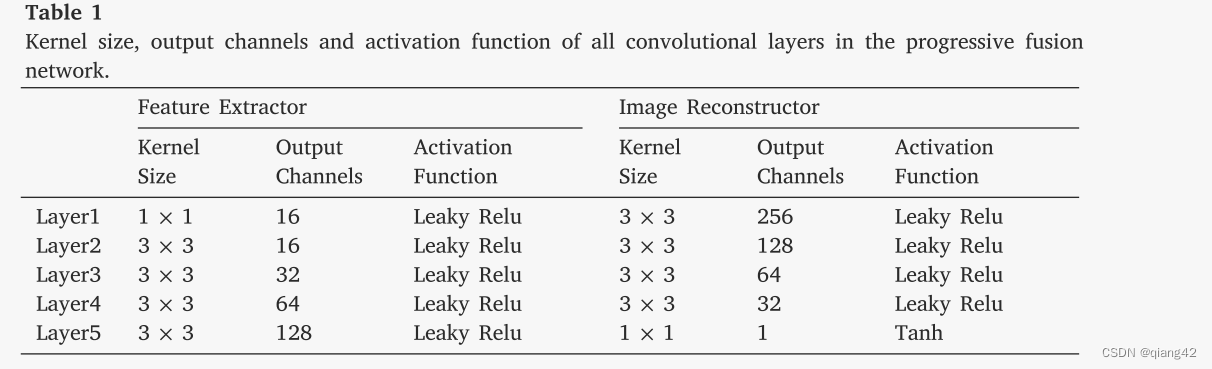
随后,将从红外和可见光图像中提取的深层特征连接起来,作为图像重建器的输入。图像重建器包含五个卷积层,负责充分整合公共和互补信息并生成融合图像。图像重建器的详细配置如表1所示。除了最后一层的内核大小为1×1之外,所有层的内核大小均为3×3。此外,图像重建器逐渐减少特征图的通道数图像重建过程。图像重建器中的所有卷积层均采用Leaky Relu作为激活函数,除了最后一层,其激活函数为Tanh。
信息丢失是图像融合过程中的一个灾难性问题。因此,渐进融合网络的所有卷积层中的填充设置为相同,并且除了第一层和最后一层之外的步幅设置为1。因此,我们的网络没有引入任何下采样,并且融合图像的大小与源图像一致。
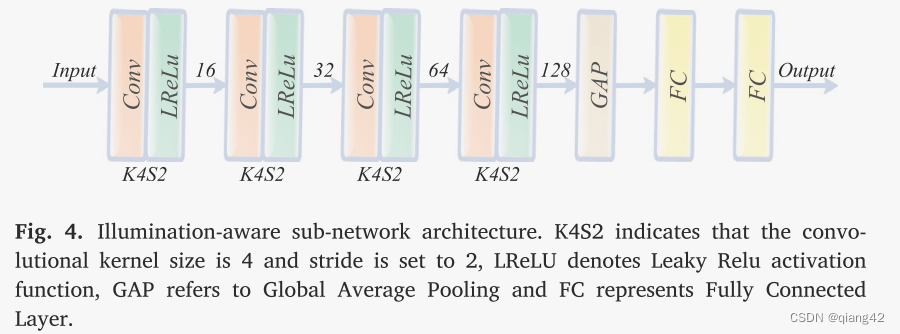
光照感知子网络
光照感知子网络旨在估计场景的光照分布,其输入是可见图像,输出是光照概率。照明感知子网络的架构如图 4 所示。它由四个卷积层、一个全局平均池化层和两个全连接层组成。步长设置为 2 的 4 × 4 卷积层压缩空间信息并提取照明信息。所有卷积层均采用 Leaky Relu 作为激活函数,并将 padding 设置为相同。然后,利用全局平均池化操作来整合照明信息。最后,两个全连接层根据照明信息计算照明概率。
实验验证
数据集构建
我们基于 MFNet 数据集构建了一个新的用于红外和可见光图像融合的多光谱数据集 。 MFNet数据集包含1,569个图像对(820个白天拍摄,749个夜间拍摄),空间分辨率为480×640。然而,MFNet数据集中存在许多未对齐的图像对,并且大多数红外图像信噪比较低和低对比度。为此,我们首先通过删除 125 个未对齐的图像对收集 715 个白天图像对和 729 个夜间图像对。此外,利用基于暗通道先验的图像增强算法来优化红外图像的对比度和信噪比。因此,发布的新多光谱道路场景 (MSRS) 数据集包含 1,444 对对齐的高质量红外和可见光图像。
结果
对比试验






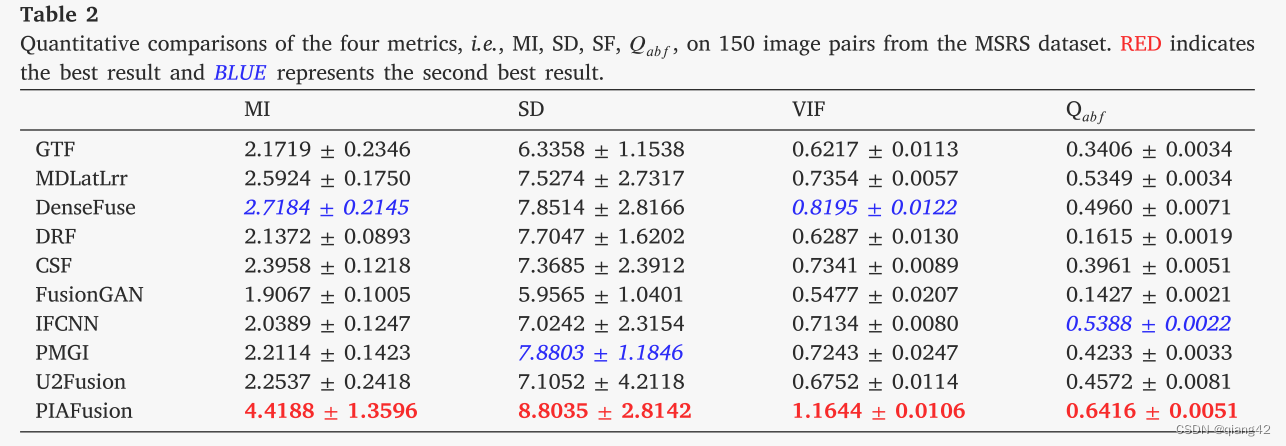
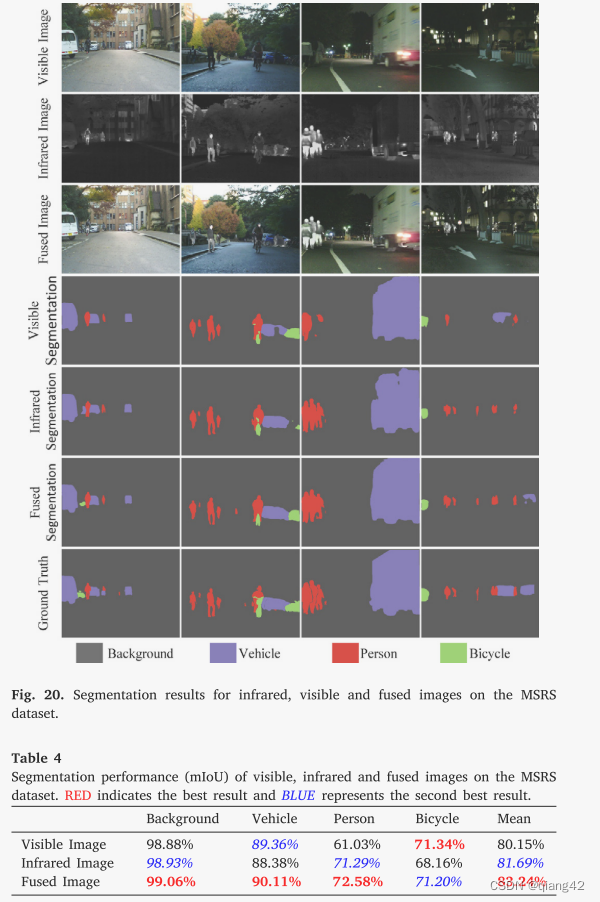
图像分割中的应用结果
消融实验

结论
在这项工作中,我们提出了一种基于照明感知的渐进式红外和可见光图像融合框架,称为 PIAFusion,它根据照明条件自适应地集成有意义的信息。我们设计了一个照明感知子网络来估计输入图像的照明分布并计算照明概率。此外,利用照明概率来构建照明感知损失。在光照感知损失的指导下,融合网络通过跨模态差分感知融合模块和中途融合策略自适应地合并公共信息和互补信息。因此,渐进式融合网络可以全天候生成包含显着目标和丰富纹理信息的融合图像。此外,我们构建了一个新的红外和可见光数据集,称为多光谱道路场景(MSRS),用于图像融合的训练和基准评估。我们进行了大量的实验来证明我们的优势,包括目标维护、纹理保存和照明适应。此外,语义分割的扩展实验证明了我们提出的方法在高级视觉任务中的潜力。
🚀传送门
📑图像融合相关论文阅读笔记
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[Visible and Infrared Image Fusion Using Deep Learning]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📚图像融合论文baseline总结
📑其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~



















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











