







@article{xing2024cfnet,
title={CFNet: An infrared and visible image compression fusion network},
author={Xing, Mengliang and Liu, Gang and Tang, Haojie and Qian, Yao and Zhang, Jun},
journal={Pattern Recognition},
volume={156},
pages={110774},
year={2024},
publisher={Elsevier}
}
| 中科/JCR分区:1区/Q1 |
| 影响因子:14.8 |
文章目录
📖论文解读
现有方法没有充分考虑图像数据的冗余度和传输效率。针对这一局限性,提出了一种基于联合CNN和Transformer的红外与可见光图像压缩融合网络CFNet。首先,将变分自动编码器图像压缩的思想引入到图像融合框架中,在保持图像融合质量和降低冗余度的同时,实现了数据压缩。在此基础上,提出了一种CNN和Transformer联合网络结构,该网络结构综合考虑了CNN提取的局部信息和Transformer强调的全局远程依赖关系。最后,利用基于感兴趣区域的多通道损失来指导网络训练。不仅可以直接融合彩色可见光和红外图像,而且可以将更多的比特分配给感兴趣的前景区域,从而获得更高的压缩比。
说重点就是,结合了变分自动编码器VAE,结合了CNN和Transformer、可以直接融合彩色可见光和红外图像、考虑了冗余度和传输效率
🔑关键词
Image fusion 图像融合
Image compression 图像压缩
Variational autoencoder 变分自编码器
Transformer
Region of interest
💭核心思想
将VAE引入IVIF,而且考虑了数据传输的问题
将变分自动编码器(VAE)图像压缩模型引入到图像融合框架中。具体地,通过图像编码器将图像映射到潜在特征空间,便于后续的量化编码过程。然后,利用超先验编解码器得到特征点的概率分布函数,从而得到更紧凑的特征。这在最大程度上消除了统计上的依赖性。然后应用量化编码来生成用于存储和传输的比特流,随后对其进行解码以产生最终的融合图像。
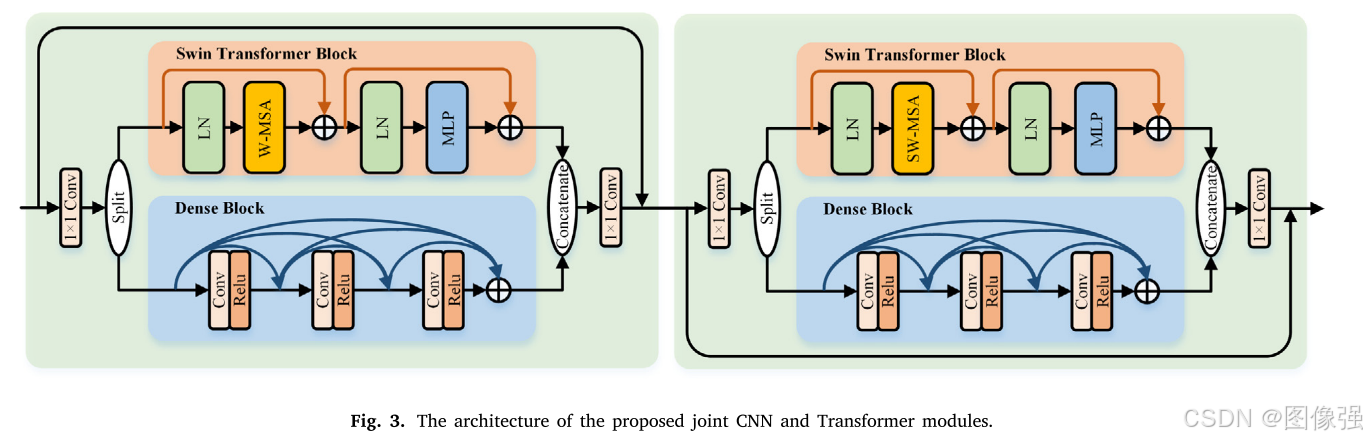
将CNN和Transformer嵌入到同一个模块中,以聚合本地和非本地信息。
用多通道像素损失和多通道梯度损失指导网络训练
🎖️本文贡献
- 这是VAE压缩框架首次被引入图像融合领域
- 提出了一种新颖的CNN和Transformer联合网络结构
- 设计了一种新颖的感兴趣区域多通道损失函数来指导网络训练
🪅相关背景知识
-
深度学习
-
神经网络
-
图像融合
-
VAE
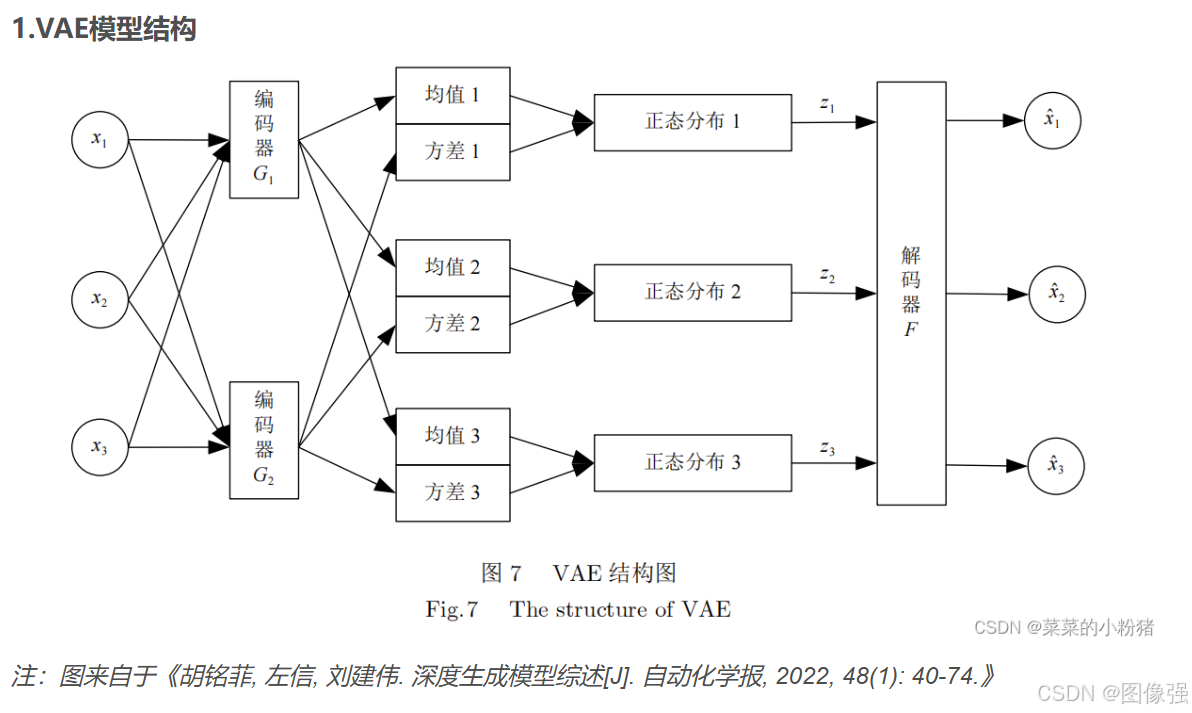
🪢网络结构
作者提出的网络结构如下所示。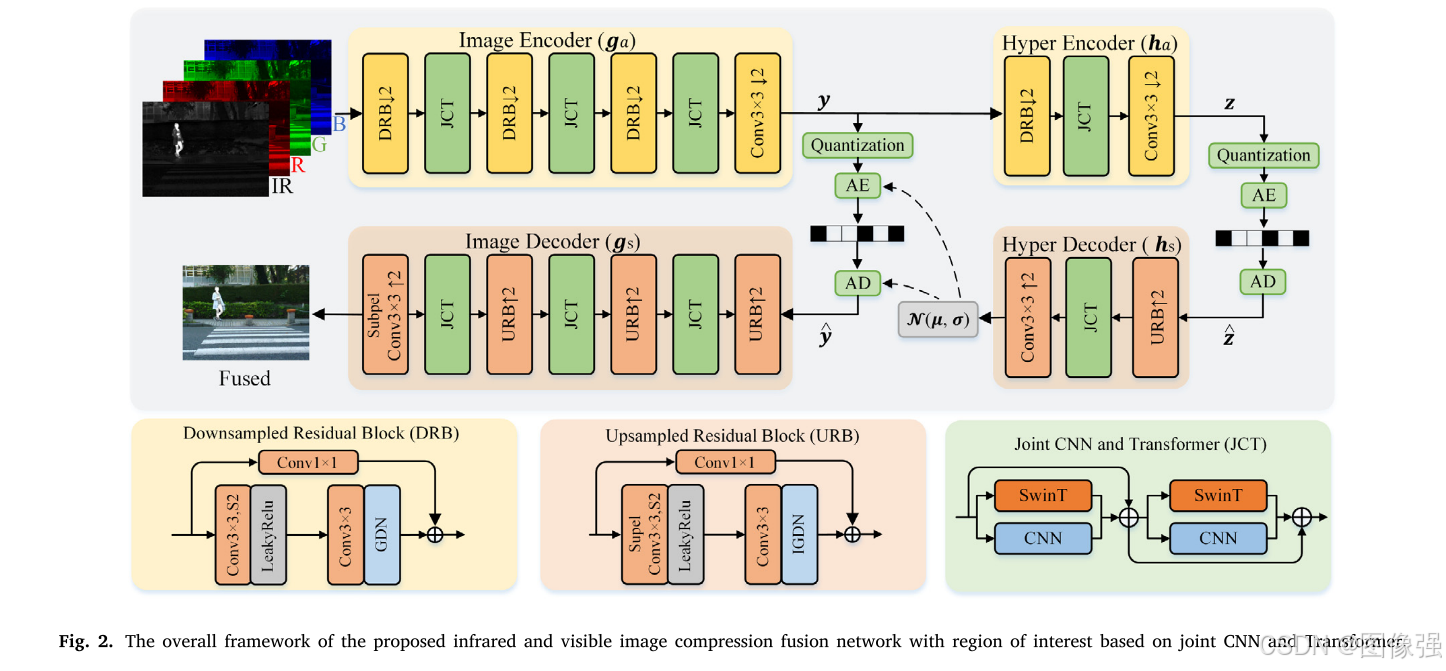
首先可以看到,模型的输入为三通道RGB彩色可见光图像和单通道的红外图像。
网络结构包括:图像编码器模块𝑔𝑎、超先验编码器模块ℎ𝑎、超先验解码器模块ℎ𝑠、图像解码器模块𝑔𝑠和两个量化和熵编码模块𝑈|𝑄𝑦和𝑈|𝑄𝑧
该模型的过程可以表示为:
首先将红外图像和可见光图像输入至图像编码模块得到潜在特征表示y。然后将其输入至超先验编码器模块,得到超先验表示z。将z量化转换为离散形式得到
z
^
\hat z
z^。将
z
^
\hat z
z^输入超先验解码器得到均值 𝜇 和标准差 𝜎,y根据概率分布进行编码得到
y
^
\hat y
y^,通过图像解码器得到最终的融合图像。
具体来说,超先验编码器将输入数据 𝑦 映射到表示 𝑧 的编码。表明𝑧旨在捕获𝑦的关键信息,同时去除冗余和不相关的部分,从而实现数据的有效压缩。
JCT的结构如下图
📉损失函数
训练过程损失包括融合损失和比率损失
📉融合损失
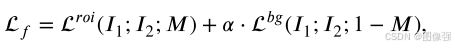
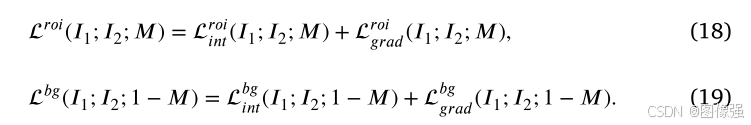
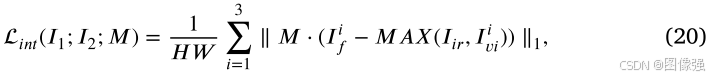
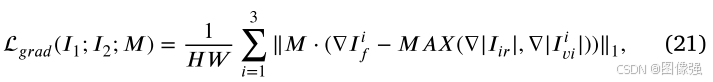
📉比率损失
最小平均码长
R
\mathcal R
R是通过最小化对原始图像𝑝𝑥的数据分布𝑥的期望来实现的。
R
\mathcal R
R由潜在表示和实际分布之间的香农交叉点给出:
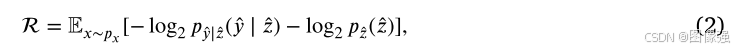
🔢数据集
- M3FD
- RoadScene
- TNO
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置
在训练阶段,将图像大小随机裁剪为 256 × 256。控制各种损失项的超参数根据经验设置为 𝜆 = 500,𝛼 = 0.5。 CFNet是在PyTorch平台上实现的。 Adam 的批量大小为 8,用作训练模型的优化器。 学习率设置为0.0001。 epoch 设置为 200。对于 Swin Transformer 块,窗口大小在图像编解码器中设置为 8,在超先验编解码器中设置为 4。 在测试阶段,图像在输入到网络之前会被填充到128的倍数,然后在融合后裁剪到原始尺寸。 CFNet算法伪代码如算法1所示。训练平台配备Intel® Xeon® Silver 4210R CPU、64 GB内存和NVIDIA GeForce GTX 3090 GPU。
🔬实验
📏评价指标
- MI
- VIF
- SCD
- Q A B F Q^{ABF} QABF
- SSIM
- MS-SSIM
- F M I p i x e l FMI_{pixel} FMIpixel
- Delta-E
- SF
- SSIM
- SCD
- QABF
- VIF
扩展学习
[图像融合定量指标分析]
🥅Baseline
- DenseFuse
- FusionGAN
- DDcGAN
- SDNet
- STDFusionNet
- U2Fusion
- CUFD
- DIVFusion
- TarDAL
- PSFusion
- YDTR
- DATFuse
- CDDFuse
✨✨✨扩展学习✨✨✨
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
🔬实验结果

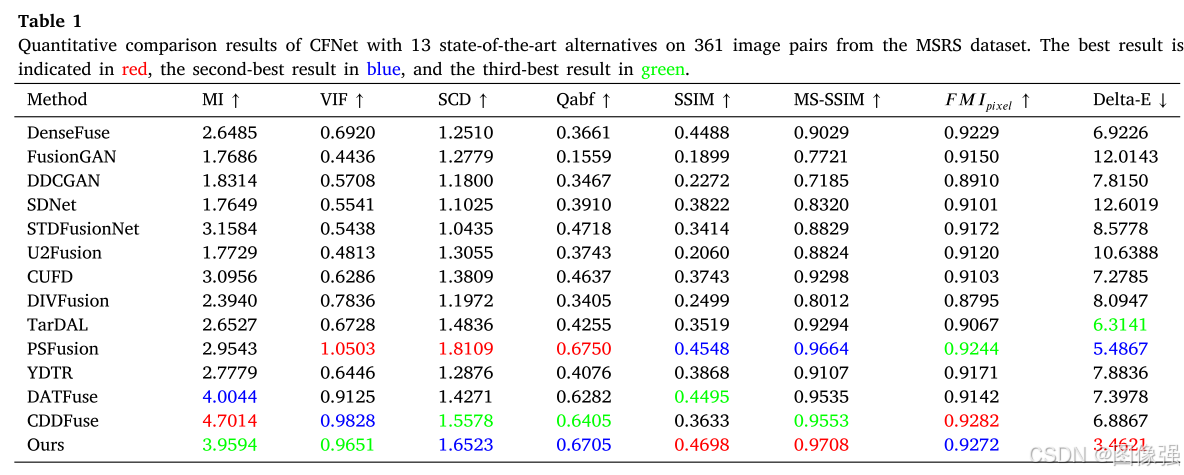
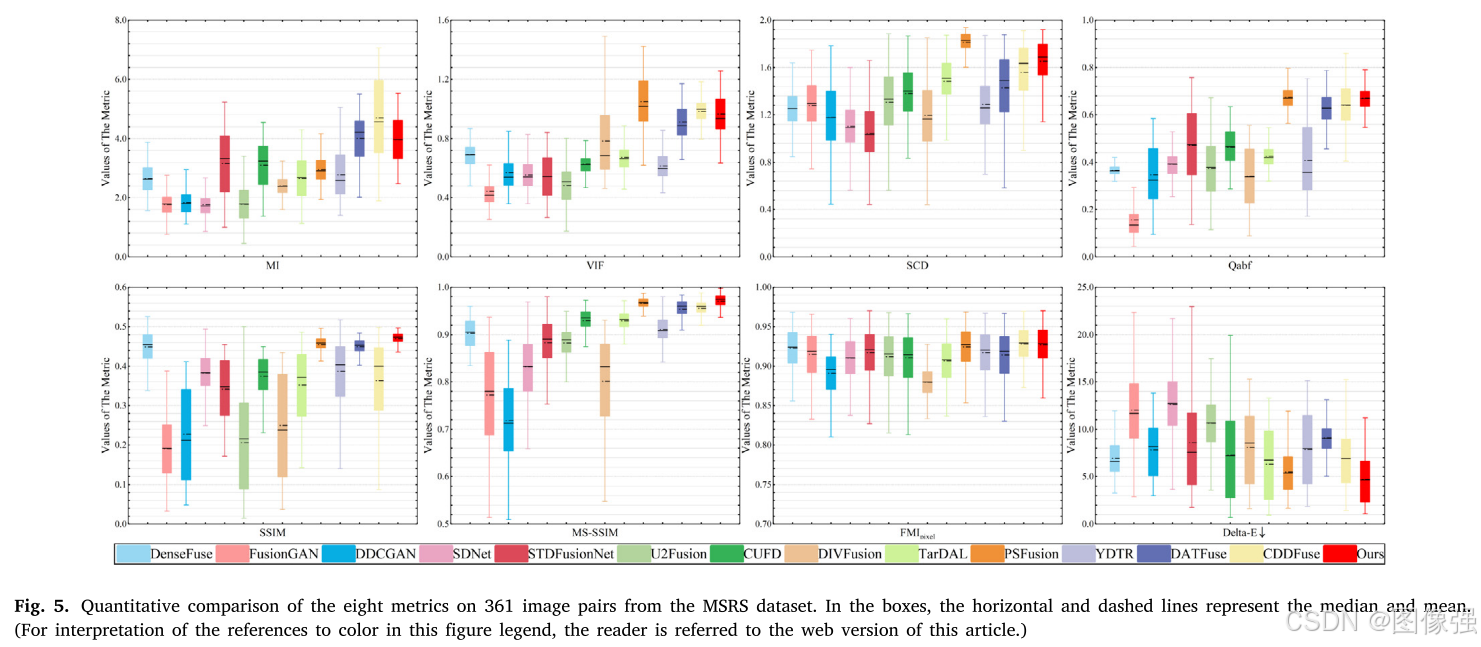

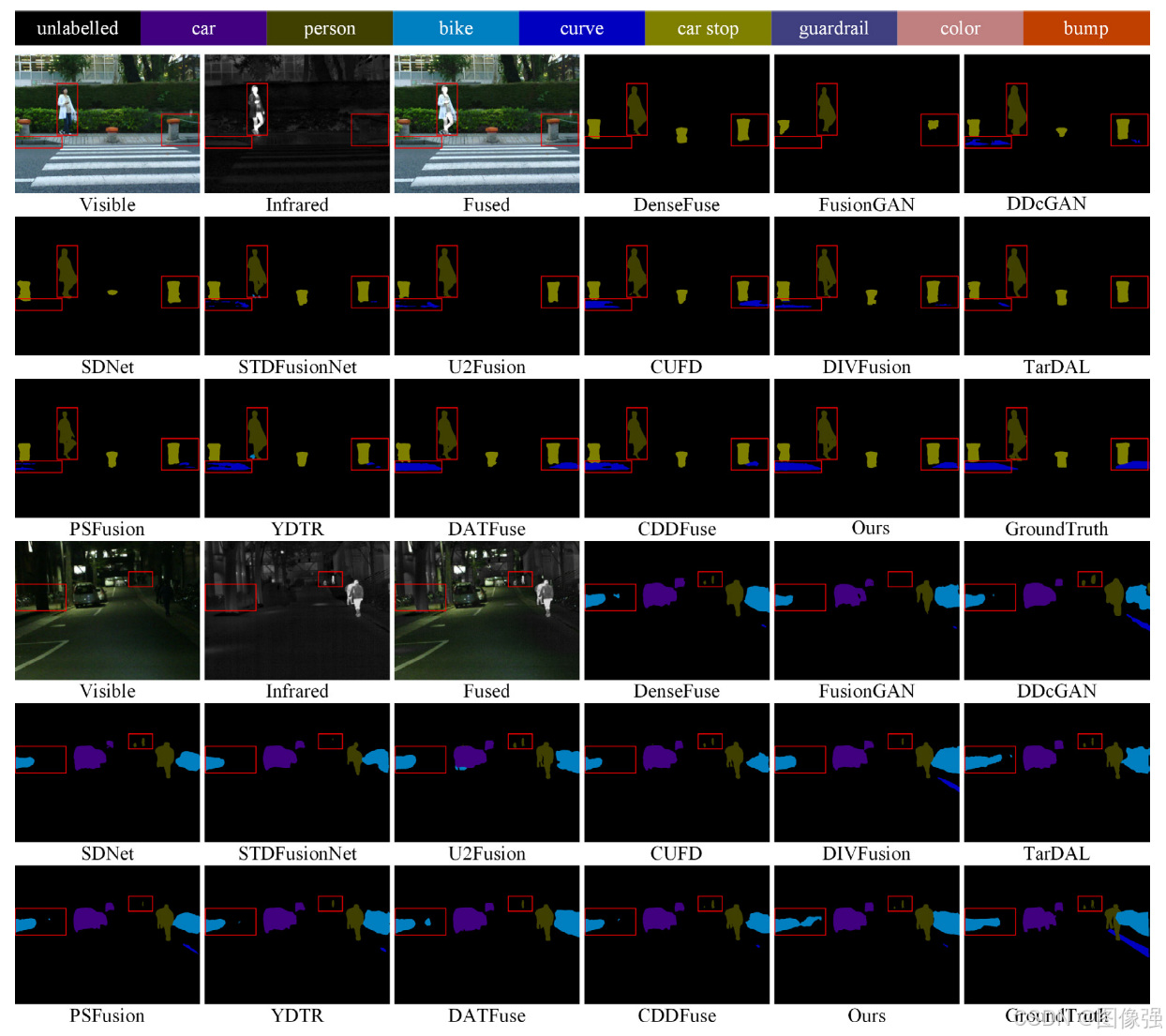
更多实验结果及分析可以查看原文:
📖[论文下载地址]
🧷总结体会
🚀传送门
📑图像融合相关论文阅读笔记
📑[SMAE-Fusion: Integrating saliency-aware masked autoencoder with hybrid attention transformer for infrared-visible image fusion]
📑[Conti-Fuse: A novel continuous decomposition-based fusion framework for infrared and visible images]
📑[SDCFusion:A semantic-driven coupled network for infrared and visible image fusion]
📑[PSFusion: Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity]
📑[SGFusion: A saliency guided deep-learning framework for pixel-level image fusion]
📑[MUFusion: A general unsupervised image fusion network based on memory unit]
📑[(TLGAN)Boosting target-level infrared and visible image fusion with regional information coordination]
📑[ReFusion: Learning Image Fusion from Reconstruction with Learnable Loss via Meta-Learning]
📑[YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer]
📑[CS2Fusion: Contrastive learning for Self-Supervised infrared and visible image fusion by estimating feature compensation map]
📑[CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach]
📑[(DIF-Net)Unsupervised Deep Image Fusion With Structure Tensor Representations]
📑[(MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion]
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
🌻【如侵权请私信我删除】
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~



















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











