







http://www.gaussianprocess.org/gpml/chapters/
https://github.com/dfm/gp
- 线性回归
y=ax+b, 最小二乘法, 用已有的数据集估算a和b,最小化损失函数 - 先验和后验概率
参考链接:https://www.zhihu.com/question/24261751/answer/158547500
https://blog.csdn.net/qq_23947237/article/details/78265026
先验:未知条件下,根据直觉对事情的猜测
后验:事情已经发生,这个事情由某个因素引起的可能性的大小。由结果推原因。可以表示为p(原因|结果)
似然:p(结果|原因)
贝叶斯公式:
参考链接:https://www.jianshu.com/p/a7ed8b29f570
https://www.cnblogs.com/yemanxiaozu/p/7680761.html
p(a|b)=p(a)*p(b|a)/p(b)
先有个事情a, 根据经验给出先验。当事情b已经发生后, 事情a的概率可能发生变化。根据p(b|a)/p(b)调整先验(增强或削弱或不影响先验)
最大后验估计和最大似然估计都是点估计,贝叶斯估计需要得到一个概率分布,不是点估计,是根据已经发生的事情对先验的不断修正。
贝叶斯回归
可以采用mcmc方法处理回归系数和预测值
如果没有先验,一般认为先验为高斯分布
参考链接:https://baijiahao.baidu.com/s?id=1598705784509790616&wfr=spider&for=pc
多元高斯分布:
参考链接:
https://blog.csdn.net/paulfeng20171114/article/details/80276061
https://blog.csdn.net/GoodShot/article/details/79940438
https://www.jgoertler.com/visual-exploration-gaussian-processes/
https://blog.csdn.net/qq_20195745/article/details/82721666
矩阵函数,用每个元的均值和协方差矩阵定义,协方差矩阵上对角线代表这个元的方差,其余为协方差。
协方差表示两个变量之间的相互关系,协方差大与0表示正相关。
性质:在条件作用和边缘化的运算之后,仍为高斯分布
数据集为(x,y)
预测值f(x)≈y
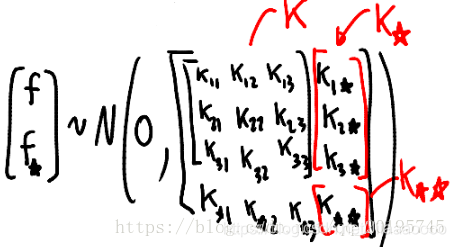
高斯过程回归的目标是得到f(x)的分布,已有f(x)标记为f,需要预测的f(x*)标记为f*
根据贝叶斯计算公式
p(f*|f)=p(f*) ✖️p(f|f*)/p(f)=p(f*,f)/p(f)
计算p(f*,f)/p(f)即可得到预测结果
f~N(u,K)
核心问题1、计算协方差矩阵2、计算f*
1、协方差矩阵用核函数
x的形状影响f(x)的形状
输入x能得到f(x)的协方差
所以用核函数,k(x,x·) 来表示x和x·的关系
如何学习kernel的参数?很简单kernel k(x,{x}’) 优劣的评价标准就是在要f(x)\sim N(m(x),k(x,x{{T}}))\的条件下,让p(Y|X)最大,为了方便求导我们将目标函数设为logp(Y|X)=log N(\mu ,K_{y}),接下来利用梯度下降法来求最优值即可:
2、计算f*














 1967
1967











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









