







yarn安装
- 配置etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- 配置etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置web界面,默认是8088,防止被攻击改成38088-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:38088</value>
</property>
</configuration>
- 启动yarn:start-yarn.sh

ResourceManager和NodeManager是yarn的两个进程
hadoop自带的词频统计wordcount
- 先查找wordcount的jar包
[hadoop@hadoop01 hadoop]$ find ./ -name '*example*.jar'
./share/hadoop/mapreduce1/hadoop-examples-2.6.0-mr1-cdh5.16.2.jar
./share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar
./share/hadoop/mapreduce2/sources/hadoop-mapreduce-examples-2.6.0-cdh5.16.2-sources.jar
./share/hadoop/mapreduce2/sources/hadoop-mapreduce-examples-2.6.0-cdh5.16.2-test-sources.jar
- 选择最后一个执行
hadoop jar app/hadoop/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.16.2.jar wordcount /wordcount/input1/a.txt /wordcount/output1
- 执行过程
- 查看执行结果

如果是SUCCESS就是完成,UNSUCCESS就是未完成

修改机器的hostname
在root用户下修改
[root@JD ~]# hostnamectl
Static hostname: JD
Icon name: computer-vm
Chassis: vm
Machine ID: 983e7d6ed0624a2499003862230af382
Boot ID: c78cf2bffbea43d8a88110b3b8fa0c5f
Virtualization: kvm
Operating System: CentOS Linux 7 (Core)
CPE OS Name: cpe:/o:centos:centos:7
Kernel: Linux 3.10.0-327.el7.x86_64
Architecture: x86-64
[root@JD ~]# hostnamectl --help
hostnamectl [OPTIONS...] COMMAND ...
Query or change system hostname.
-h --help Show this help
--version Show package version
--no-ask-password Do not prompt for password
-H --host=[USER@]HOST Operate on remote host
-M --machine=CONTAINER Operate on local container
--transient Only set transient hostname
--static Only set static hostname
--pretty Only set pretty hostname
Commands:
status Show current hostname settings
set-hostname NAME Set system hostname
set-icon-name NAME Set icon name for host
set-chassis NAME Set chassis type for host
set-deployment NAME Set deployment environment for host
set-location NAME Set location for host
[root@JD ~]# hostnamectl set-hostname hadoop01
[root@hadoop01 ~]# cat /etc/hostname
hadoop01
[root@hadoop01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.0.3 hadoop01
JPS的使用
- jps -l或者jps -m或者jps
[hadoop@hadoop01 hsperfdata_ruoze]$ jps
23233 NameNode
23553 SecondaryNameNode
1729 Jps
29880 ResourceManager
23388 DataNode
30156 NodeManager
- 对应的标识文件在:/tmp/hsperfdata_hadoop,如果是root用户就是hsperfdata_root,如果是ruoze用户就是hsperfdata_hadoop;也就是/tmp/hsperfdata_username

- 作用:查看pid进程名称
- 进程所属的用户去执行 jps命令,只显示自己的相关的进程信息;root用户可以查看所有的进程,但是显示unavailable
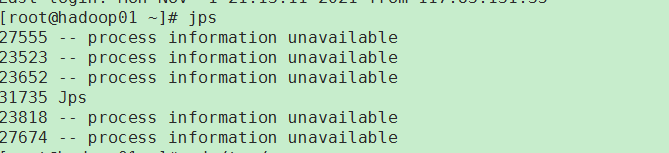
- jps一般无法准确的查看进程是否存活,需要使用命令:

这个删掉,jps是查看不到,但是ps -ef|grep 27555 命令是可以查看到的,所以需要kill掉进程才能启动resourcemanagerps -ef|grep 27555| grep -v grep | wc -l - 删除/tmp/hsperfdata_hadoop该文件下的内容不影响进程的启动和停止
Linux的oom-kill机制和一个月清除/tmp下不在规则以内的文件机制
- oom-kill机制:某个进程内存使用过高,linux系统为了保护自己,防止夯住,会去杀死内存使用过多的进程,培养意识:当某个进程挂了,要找到log位置,cat /var/log/messages | grep oom
- 清除/tmp下的文件,所以需要配置hadoop和yarn启动的进程和日志输出目录:chmod -R 777 /home/hadoop/tmp ,mv /tmp/hadoop-hadoop/dfs /home/hadoop/tmp/(该步骤一定要做不然无法启动)
vi hadoop-env.sh
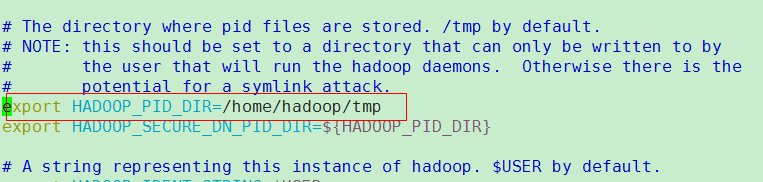
vi yarn-env.sh
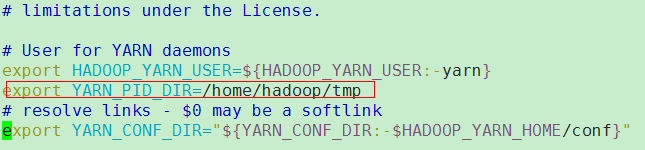
vi core-site.xml

其中hdfs-site.xml文件中
dfs.namenode.name.dir=file://${hadoop.tmp.dir}/dfs/name
dfs.datanode.data.dir=file://${hadoop.tmp.dir}/dfs/data
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
属性均由hadoop.tmp.dir决定















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









