







强化学习(Reinforcement Learning)任务通常用马尔科夫决策过程(Markov Decision Process, 简称MDP)来描述, 通常对应如下四元组:
其中:
1. E(Environment) —— 所处环境
2. S(State) —— 状态空间
3. A(Action) —— 动作空间
4. P(Probability of State Transition) —— 状态转移概率
5. R(Reward) —— 奖赏集合
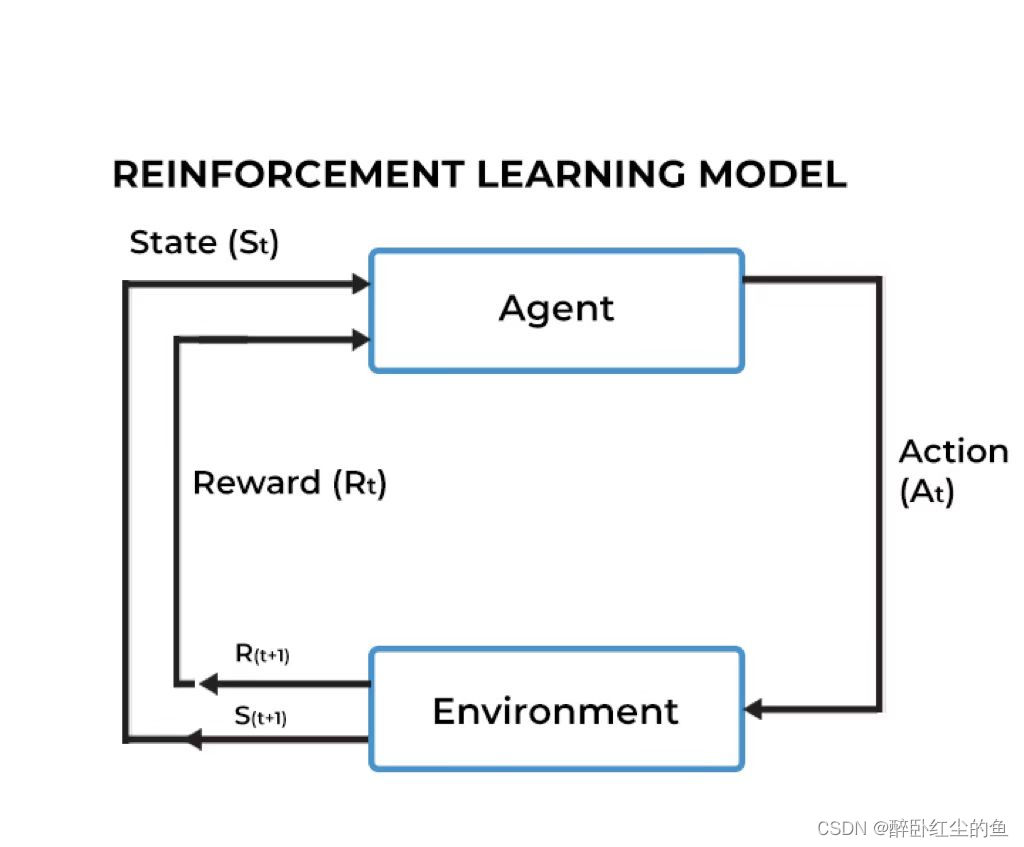
策略(Policy)是强化学习核心,即通过在环境中不断尝试而学得一个策略π,根绝这个策略,在状态s∈S下能得知要执行的动作a∈A或者概率:
或
策略有两种表示方法:函数表示和概率表示。函数表示常用于确定性(Certainty)策略,概率表示常用于随机性(Randomness)策略。
评估策略的标准是长期执行策略后得到的累积奖赏。
强化学习的目的就是找到能够使长期累积奖赏最大化的策略。















 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









