







该模型主要用于处理评论信息,提高推荐的准确性。

模型分为六个部分,分别是Input embedding,Review-level Co-attention,Review Pointers,Word-level Co-Attention,Multi-Pointer Learning和Prediction Layer。
一、Input embedding
首先是Input embedding层,该层分为两个部分,即Embedding Layer和Review Gating Machanism。其中,在Embedding Layer,用与其相关的评论构成用户序列a和项目序列b,每条评论中的每个单词都用一个one-hot向量表示。在Review Gating Machanism层中,设计了一个第一阶段过滤器。一个门控机制,决定了有多少评论信息可以被传到下一层。
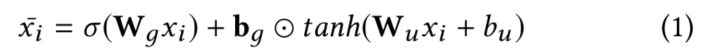
二、Review-level Co-attention
该层的主要目的是在评论库中选取那个信息最丰富的评论,包括两个部分Affinity Matrix和Pooling Function。
在Affinity Maxtrix部分,计算user的第i条评论和item的第j条评论的相似度。
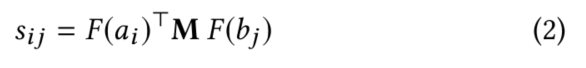
计算出相似度后,在Pooling Function部分中,选用最大池化,获取相似度矩阵的行列最大值,以此挑选出信息最丰富的评论。
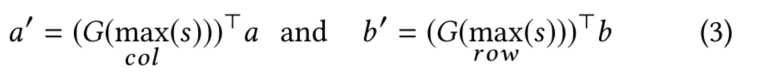
其中的函数G需要返回一个one-hot向量,因此不能是softmax函数,在下一部分,主要介绍了函数G的选取。
三、Review Pointers
评论指针指的是一个one-hot向量,起到指示某一条评论的作用。其中包括Gumbel-Max,Straight-Through Gumbel-Softmax和Learning to Point。
关于Gumbel-Max,主要作用是离散化随机变量,得到一个ont-hot向量。
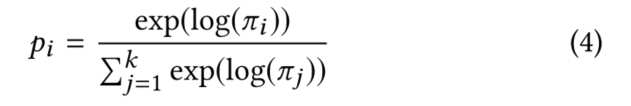
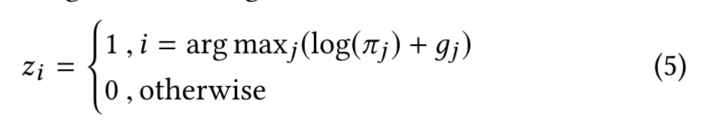
因为arg max操作不可导,故提出了Gumbel-Max的改进Gumbel-Softmax。
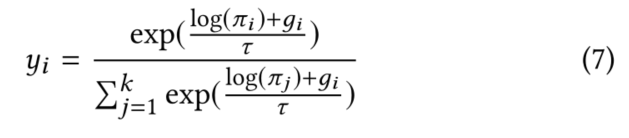
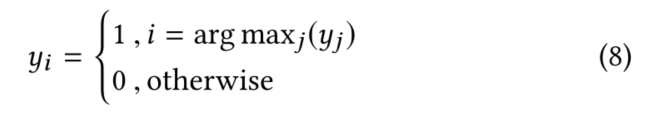
在Learning to Point部分,整合之前的步骤,获得评论指针。
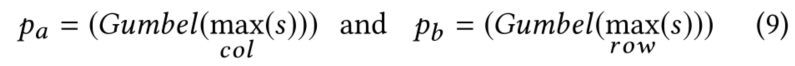
四、Word-level Co-Attention
单词级别的共同注意力机制,与评论级的类似。先获取相似度矩阵,然后采用平均池化利用每个单词的embedding来表示评论的embedding。
![]()
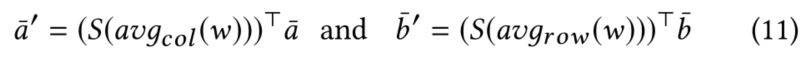
五、Multi-Pointer Learning
进行多次指针选取工作,选取评论(多次选取的评论可能相同也可能不同)。选取方法聚合这些评论,最终得到user和item的表示。
六、Prediction Layer
利用FM预测最终ueser对item的打分。
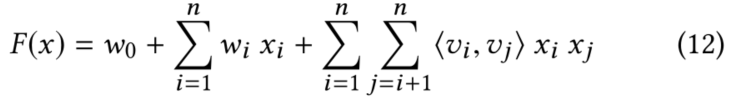















 1308
1308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









