









研究问题
首次使用GNN去解决多元时间序列插补问题
背景动机
- 在真实场景下,时间序列数据通常是不完整的,通过插补方法来对缺失值进行填充是一项必要工作(和时间序列的预测问题相比,插补法不仅可以利用过去的事件信息,也可以利用未来的时间信息)
- 现有方法无法有效捕捉到传感器网络中存在的非线性时间和空间依赖性,也无法充分利用关系信息
- 两个传感器具有空间相似性不意味着物理上接近,而是说它们的数据变化比较相关
- 考虑到图神经网络可用于处理具有关系归纳偏差的序列数据,论文提出了一个称之为GRIN的GNN框架,通过消息传递学习时空表示来重建多元时间序列不同通道中的缺失数据
符号定义
-
假设在每个时间点 t t t,我们都可以观测到一个有 N t N_{t} Nt个节点的图 G t = ⟨ X t , W t ⟩ \mathcal{G}_{t}=\left\langle\boldsymbol{X}_{t}, \boldsymbol{W}_{t}\right\rangle Gt=⟨Xt,Wt⟩,其节点属性矩阵为 X t ∈ R N t × d \boldsymbol{X}_{t} \in \mathbb{R}^{N_{t} \times d} Xt∈RNt×d,其中节点 i i i的属性向量为 x t i ∈ R d \boldsymbol{x}_{t}^{i} \in \mathbb{R}^{d} xti∈Rd,邻接矩阵为 W t ∈ R N t × N t \boldsymbol{W}_{t} \in \mathbb{R}^{N_{t} \times N_{t}} Wt∈RNt×Nt
-
上述定义的图具有拓扑不变性,即在任何时刻,都满足 W t = W , N t = N \boldsymbol{W}_{t}=\boldsymbol{W},N_t=N Wt=W,Nt=N
-
假设红色圈代表缺失值,则图序列如下所示。为了对缺失值建模,在每个时间点引入矩阵 M t ∈ { 0 , 1 } N t × d \boldsymbol{M}_{t} \in\{0,1\}^{N_{t} \times d} Mt∈{0,1}Nt×d,0值就表示缺失

-
时间序列插补可定义为最小化如下重构误差,其中 X ^ [ t , t + T ] \widehat{\boldsymbol{X}}_{[t, t+T]} X [t,t+T]是估计值, X ~ [ t , t + T ] \widetilde{\boldsymbol{X}}_{[t, t+T]} X [t,t+T]是真实值, M ‾ [ t , t + T ] \overline{\boldsymbol{M}}_{[t, t+T]} M[t,t+T]是对 M [ t , t + T ] \boldsymbol{M}_{[t, t+T]} M[t,t+T]的逻辑补(1表示缺失,0表示未缺失), ℓ ( ) \ell() ℓ()为误差计算函数, < > <> <>为点积操作,下面式子的实质其实就是求所有插补误差的平均
L ( X ^ [ t , t + T ] , X ~ [ t , t + T ] , M ‾ [ t , t + T ] ) = ∑ h = t t + T ∑ i = 1 N t ⟨ m ‾ h i , ℓ ( x ^ h i , x ~ h i ) ⟩ ⟨ m ‾ h i , m ‾ h i ⟩ \mathcal{L}\left(\widehat{\boldsymbol{X}}_{[t, t+T]}, \widetilde{\boldsymbol{X}}_{[t, t+T]}, \overline{\boldsymbol{M}}_{[t, t+T]}\right)=\sum_{h=t}^{t+T} \sum_{i=1}^{N_{t}} \frac{\left\langle\overline{\boldsymbol{m}}_{h}^{i}, \ell\left(\hat{\boldsymbol{x}}_{h}^{i}, \tilde{\boldsymbol{x}}_{h}^{i}\right)\right\rangle}{\left\langle\overline{\boldsymbol{m}}_{h}^{i}, \overline{\boldsymbol{m}}_{h}^{i}\right\rangle} L(X [t,t+T],X [t,t+T],M[t,t+T])=∑h=tt+T∑i=1Nt⟨mhi,mhi⟩⟨mhi,ℓ(x^hi,x~hi)⟩ -
插补可分为内插补和外插补
模型方法
- 总体框架
论文提出的模型为Graph Recurrent Imputation Network (GRIN),它是一个双向图递归神经网络,包含的两个单向GRIN子模块分别对每个方向执行两个阶段的插补,从而在时间上向前和向后渐进地处理输入序列。然后,前馈网络将前向和后向模型学习的表示作为输入,并对图的每个节点和序列的每个步骤执行最终的细化插补
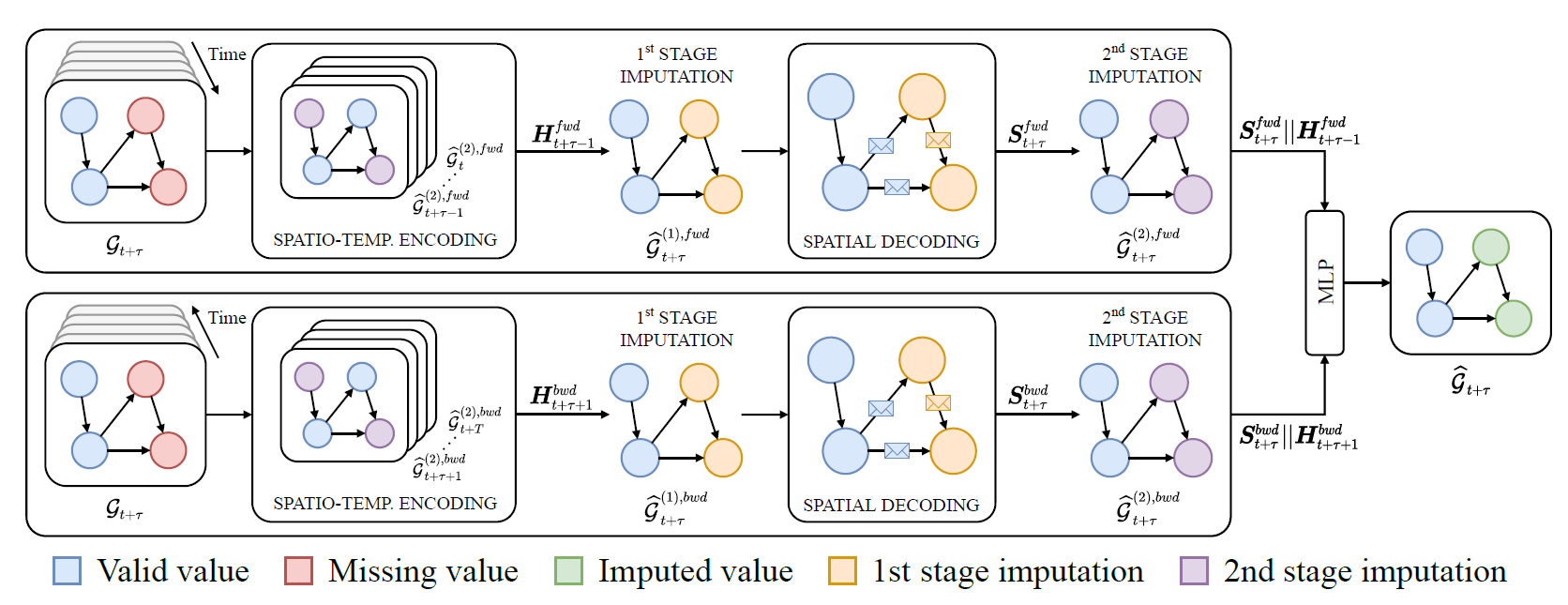
-
单向GRIN子模块
包含两个模块,一个是spatio-temporal encoder,一个是spatial decoder。前者用一个特别设计的RGNN实现,将输入特征 X [ t , t + T ] \boldsymbol{X}_{[t, t+T]} X[t,t+T]转化为时空表示 H [ t , t + T ] ∈ R N t × l \boldsymbol{H}_{[t, t+T]} \in \mathbb{R}^{N_{t} \times l} H[t,t+T]∈RNt×l;后者用MPNN(message-passing neural networks)实现,来执行两阶段插补,第一阶段执行一个线性映射,第二阶段则利用可获得的空间和关系信息 -
spatio-temporal encoder
首先定义MPNN层如下,其中 z t , k − 1 i \boldsymbol{z}_{t, k-1}^{i} zt,k−1i是节点特征向量, N ( i ) \mathcal{N}(i) N(i)是节点 i i i邻居集合, γ k , ρ k \gamma_{k}, \rho_{k} γk,ρk均为MLP层。
MPNN k ( z t , k − 1 i , W t ) = γ k ( z t , k − 1 i , ∑ j ∈ N ( i ) ρ k ( z t , k − 1 i , z t , k − 1 j ) ) = z t , k i \operatorname{MPNN}_{k}\left(\boldsymbol{z}_{t, k-1}^{i}, \boldsymbol{W}_{t}\right)=\gamma_{k}\left(\boldsymbol{z}_{t, k-1}^{i}, \sum_{j \in \mathcal{N}(i)} \rho_{k}\left(\boldsymbol{z}_{t, k-1}^{i}, \boldsymbol{z}_{t, k-1}^{j}\right)\right)=\boldsymbol{z}_{t, k}^{i} MPNNk(zt,k−1i,Wt)=γk(zt,k−1i,∑j∈N(i)ρk(zt,k−1i,zt,k−1j))=zt,ki,
-
将GRU公式与MPNN层相结合,其中 r t i \boldsymbol{r}_{t}^{i} rti为重置门, u t i \boldsymbol{u}_{t}^{i} uti为更新门, x t i ( 2 ) \boldsymbol{x}_{t}^{i(2)} xti(2)为spatial decoder在上一个时间步的输出
r t i = σ ( MPNN ( [ x ^ t i ( 2 ) ∥ m t i ∥ h t − 1 i ] , W t ) ) u t i = σ ( MPNN ( [ x ^ t i ( 2 ) ∥ m t i ∥ h t − 1 i ] , W t ) ) c t i = tanh ( MPNN ( [ x ^ t i ( 2 ) ∥ m t i ∥ r t i ⊙ h t − 1 i ] , W t ) ) h t i = u t i ⊙ h t − 1 i + ( 1 − u t i ) ⊙ c t i \begin{aligned}\boldsymbol{r}_{t}^{i} &=\sigma\left(\operatorname{MPNN}\left(\left[\hat{\boldsymbol{x}}_{t}^{i(2)}\left\|\boldsymbol{m}_{t}^{i}\right\| \boldsymbol{h}_{t-1}^{i}\right], \boldsymbol{W}_{t}\right)\right) \\\boldsymbol{u}_{t}^{i} &=\sigma\left(\operatorname{MPNN}\left(\left[\hat{\boldsymbol{x}}_{t}^{i(2)}\left\|\boldsymbol{m}_{t}^{i}\right\| \boldsymbol{h}_{t-1}^{i}\right], \boldsymbol{W}_{t}\right)\right) \\\boldsymbol{c}_{t}^{i} &=\tanh \left(\operatorname{MPNN}\left(\left[\hat{\boldsymbol{x}}_{t}^{i(2)}\left\|\boldsymbol{m}_{t}^{i}\right\| \boldsymbol{r}_{t}^{i} \odot \boldsymbol{h}_{t-1}^{i}\right], \boldsymbol{W}_{t}\right)\right) \\\boldsymbol{h}_{t}^{i} &=\boldsymbol{u}_{t}^{i} \odot \boldsymbol{h}_{t-1}^{i}+\left(1-\boldsymbol{u}_{t}^{i}\right) \odot \boldsymbol{c}_{t}^{i}\end{aligned} rtiutictihti=σ(MPNN([x^ti(2)∥∥mti∥∥ht−1i],Wt))=σ(MPNN([x^ti(2)∥∥mti∥∥ht−1i],Wt))=tanh(MPNN([x^ti(2)∥∥mti∥∥rti⊙ht−1i],Wt))=uti⊙ht−1i+(1−uti)⊙cti -
spatial decoder
第一阶段插补,直接生成线性表示
Y ^ t ( 1 ) = H t − 1 V h + b h \widehat{\boldsymbol{Y}}_{t}^{(1)}=\boldsymbol{H}_{t-1} \boldsymbol{V}_{h}+\boldsymbol{b}_{h} Y t(1)=Ht−1Vh+bh
定义filter操作,其实就是用预测出来的结果去取代缺失值 Φ ( Y t ) = M t ⊙ X t + M ‾ t ⊙ Y t \Phi\left(\boldsymbol{Y}_{t}\right)=M_{t} \odot \boldsymbol{X}_{t}+\overline{\boldsymbol{M}}_{t} \odot \boldsymbol{Y}_{t} Φ(Yt)=Mt⊙Xt+Mt⊙Yt,可以得到第一阶段的插补结果为 X t ( 1 ) = Φ ( Y t ( 1 ) ) \boldsymbol{X}_{t}^{(1)}=\Phi\left(\boldsymbol{Y}_{t}^{(1)}\right) Xt(1)=Φ(Yt(1))
执行一次MPNN,再执行一次线性运算得到第二阶段插补结果,注意这里邻居集合不包含自身,论文里面说这样可以迫使模型学习如何通过考虑空间依赖性来重构目标输入。
s t i = γ ( h t − i i , ∑ j ∈ N ( i ) / i ρ ( [ Φ ( x ^ t j ( 1 ) ) ∥ h t − 1 j ∥ m t j ] ) ) s_{t}^{i}=\gamma\left(\boldsymbol{h}_{t-i}^{i}, \sum_{j \in \mathcal{N}(i) / i} \rho\left(\left[\Phi\left(\hat{\boldsymbol{x}}_{t}^{j(1)}\right)\left\|\boldsymbol{h}_{t-1}^{j}\right\| \boldsymbol{m}_{t}^{j}\right]\right)\right) sti=γ(ht−ii,∑j∈N(i)/iρ([Φ(x^tj(1))∥∥∥ht−1j∥∥∥mtj]))
Y ^ t ( 2 ) = [ S t ∥ H t − 1 ] V s + b s ; X ^ t ( 2 ) = Φ ( Y ^ t ( 2 ) ) \widehat{\boldsymbol{Y}}_{t}^{(2)}=\left[\boldsymbol{S}_{t} \| \boldsymbol{H}_{t-1}\right] \boldsymbol{V}_{s}+\boldsymbol{b}_{s} ; \quad \widehat{\boldsymbol{X}}_{t}^{(2)}=\Phi\left(\widehat{\boldsymbol{Y}}_{t}^{(2)}\right) Y t(2)=[St∥Ht−1]Vs+bs;X t(2)=Φ(Y t(2))
最后使用 X ^ t ( 2 ) \widehat{\boldsymbol{X}}_{t}^{(2)} X t(2)来更新隐藏层的表示,并预测下一时间步结果
- 将两个子模块的结果结合
这里没有直接考虑它们显式预测出来的值,而是将中间表示进行了映射
y ^ t i = MLP ( [ s t i , f w d ∥ h t − 1 i , f w d ∥ s t i , b w d ∥ h t + 1 i , b w d ] ) \widehat{\boldsymbol{y}}_{t}^{i}=\operatorname{MLP}\left(\left[s_{t}^{i, f w d}\left\|\boldsymbol{h}_{t-1}^{i, f w d}\right\| s_{t}^{i, b w d} \| \boldsymbol{h}_{t+1}^{i, b w d}\right]\right) y ti=MLP([sti,fwd∥∥∥ht−1i,fwd∥∥∥sti,bwd∥ht+1i,bwd])
实验结果
- 指标对比
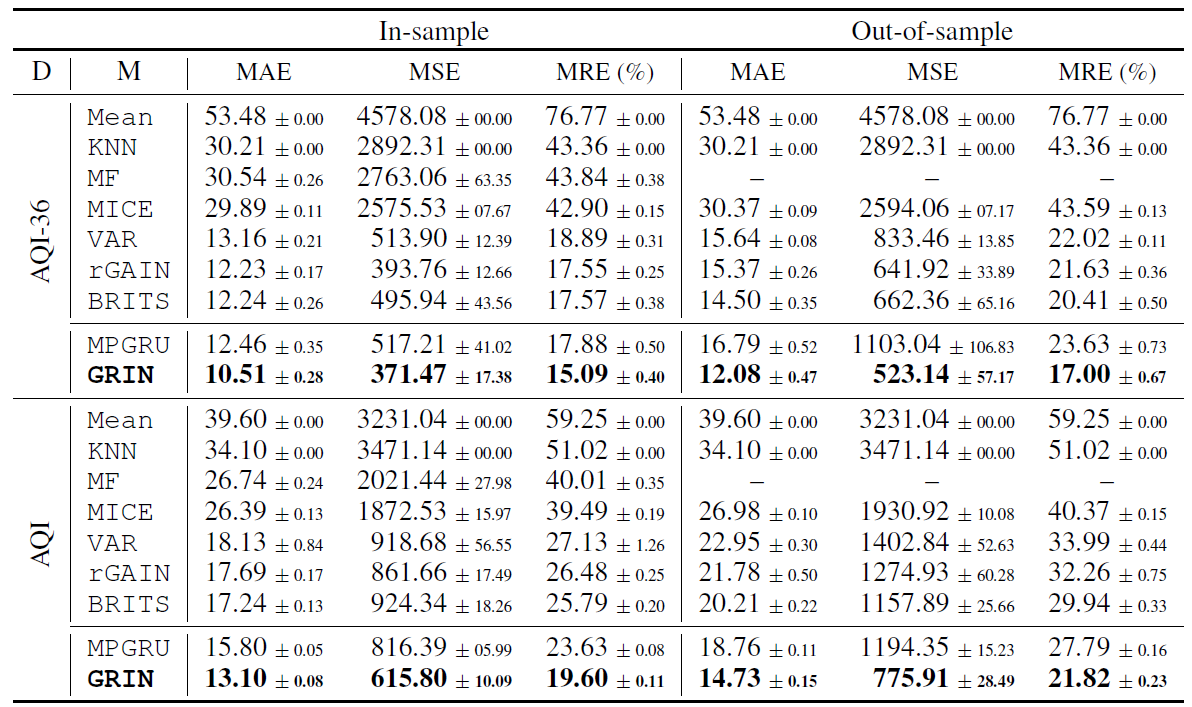
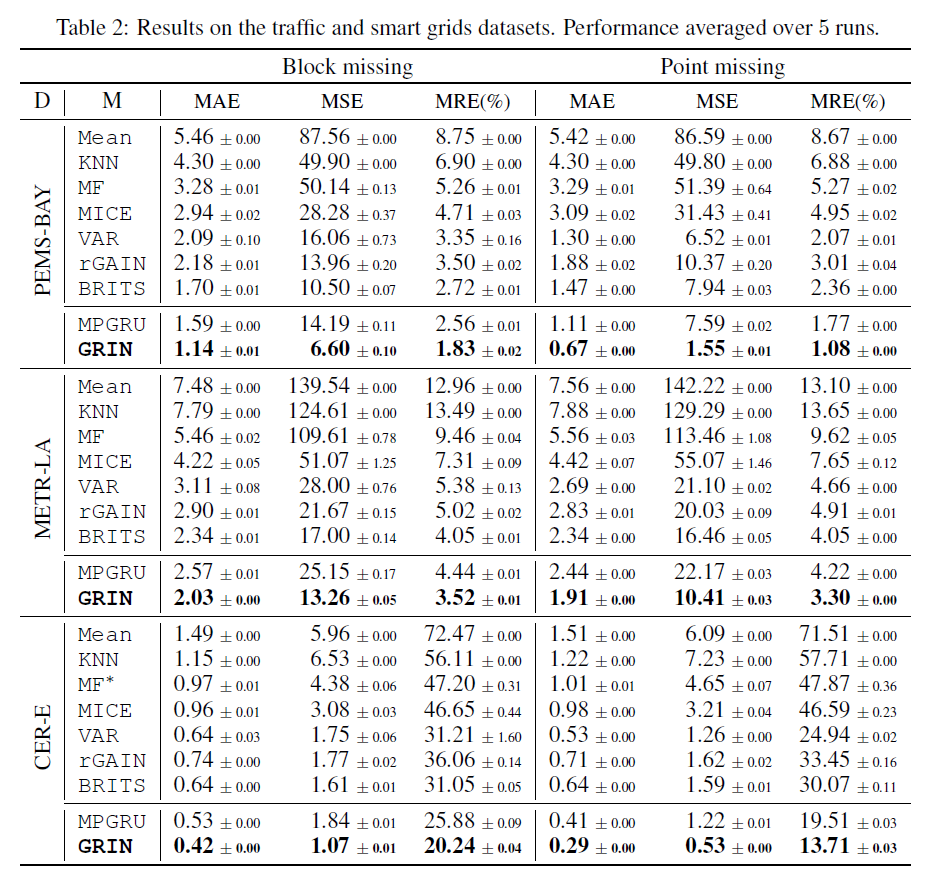
-
消融实验
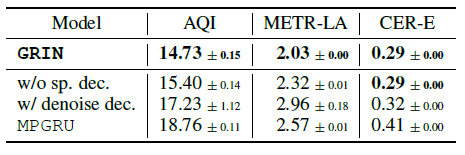
-
结果可视化
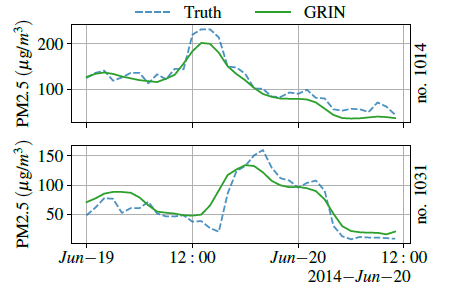
评价
这篇论文其实模型方面不是太复杂,基本就是把时序预测方面的模型改成了双向,但由于是第一次在这个领域应用,还是得到了不低的分数。但还是有两个问题让人很疑惑,一个是一开始就说了W不一定是物理连接,还要考虑相关性,但之后压根没提W怎么算出来的;再有一个就是为什么中间表示都要和矩阵M拼接起来,没有什么有解释的含义。


















 2617
2617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











