






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
西风 发自 凹非寺
转载自:量子位(QbitAI)
Stable Diffusion也能生成视频了!
你没听错,Stability AI推出了一款新的文本生成动画工具包Stable Animation SDK,可支持文本、文本+初始图像、文本+视频多种输入方式。

使用者可以调用包括Stable Diffusion 2.0、Stable Diffusion XL在内的所有Stable Diffusion模型,来生成动画。
Stable Animation SDK的强大功能一经展现,网友惊呼:
哇哦,等不及想试试了!

目前,Stability AI疑似还在对这个新工具进行技术优化,不久后将公开驱动动画API的组件源代码。
3D漫画摄影风,不限时长自动生成
Stable Animation SDK可支持三种创建动画的方式:
1、文本转动画:用户输入文prompt并调整各种参数以生成动画(与Stable Diffusion相似)。
2、文本输入+初始图像输入:用户提供一个初始图像,该图像作为动画的起点。图像与文本prompt结合,生成最终的输出动画。
3、视频输入+文本输入:用户提供一个初始视频作为动画的基础。通过调整各种参数,根据文本prompt生成最终的输出动画。

除此之外,Stable Animation SDK对生成视频的时长没有限制,但是长视频将需要更长的时间来生成。

Stability AI发布了Stable Animation SDK后,有很多网友分享了自己测试效果,让我们一起看下吧:



Stable Animation SDK可以设置许多参数,例如steps、sampler、scale、seed。
还有下面这么多的预设风格可选择:
3D模型、仿真胶片、动漫、电影、漫画书、数码艺术、增强幻想艺术、等距投影、线稿、低多边形、造型胶土、霓虹朋克、折纸、摄影、像素艺术。

目前,动画功能API的使用是以积分计费的,10美元可抵1000积分。
使用Stable Diffusion v1.5模型,在默认设置值(512x512分辨率,30steps)下,生成100帧(大约8秒)视频将消耗37.5积分。
默认情况下,每生成1帧,Cadence值设置为1个静止图像,可根据不同的动画模式选择较低或较高的Cadence值。Cadence值的上限是动画中的总帧数,即至少生成一张静止图像。视频转视频的Cadence必须为 1:1。
官方也给出了一个示例,可以看出生成100帧标准动画的标准静止图像(512x512/768x768/1024x1024,30 steps), 随着Cadence值变化,积分的使用情况:
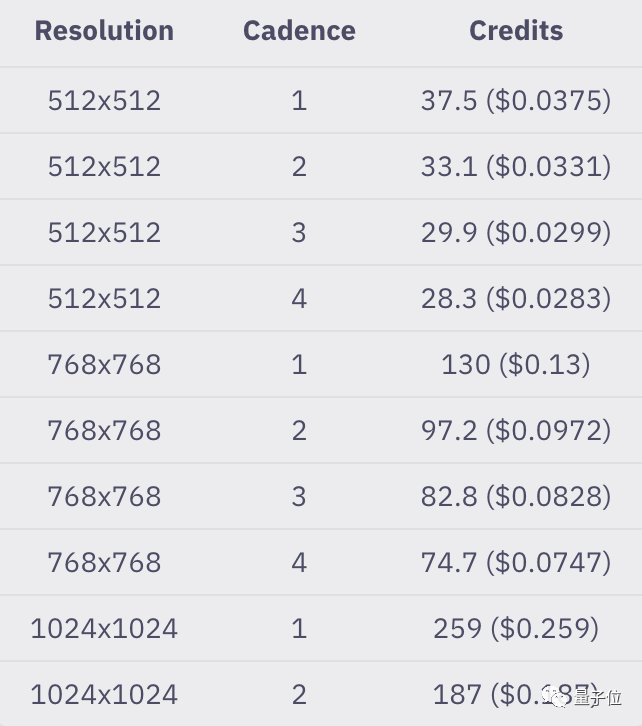
简单来说,受参数、时长等各种因素的影响,生成视频的费用并不固定。
效果和价格我们都了解了,那如何安装并调用API呢?
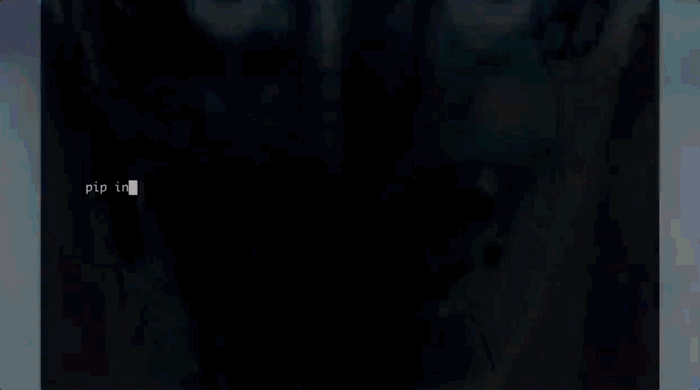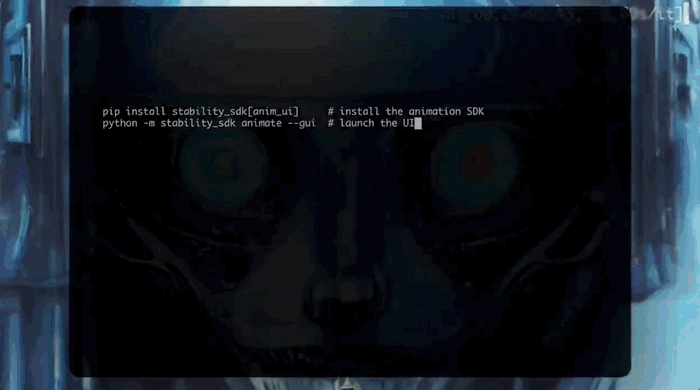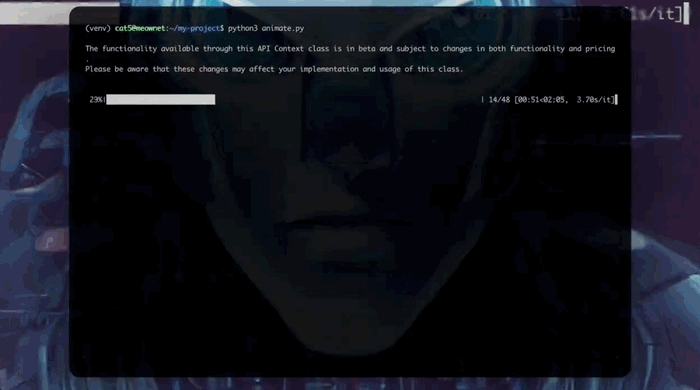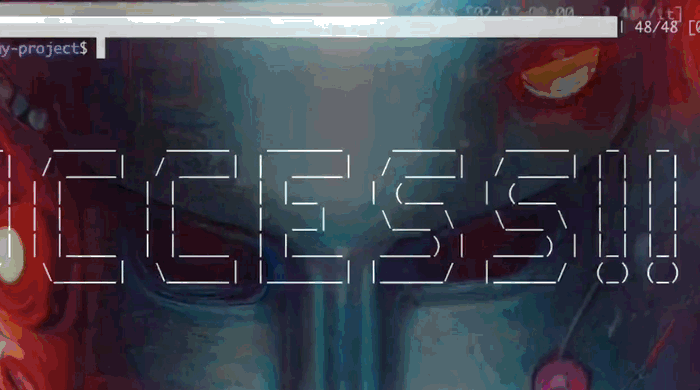
要创建动画并测试SDK的功能,只需要两个步骤即可运行用户界面:

在开发应用程序时,需要先设置一个Python虚拟环境,并在其中安装Animation SDK:

具体使用说明书放在文末啦!

越发火热的视频生成
最近,视频生成领域变得越来越热闹了。
比如,AI视频生成新秀Gen-2内测作品流出,网友看完作品直呼:太不可思议了!

Gen-2的更新更是一口气带来了八大功能:
文生视频、文本+参考图像生视频、静态图片转视频、视频风格迁移、故事板(Storyboard)、Mask(比如把一只正在走路的小白狗变成斑点狗)、渲染和个性化(比如把甩头小哥秒变海龟人)。
还有一位名叫Ammaar Reshi的湾区设计师用ChatGPT和MidJourney两个生成AI模型,成功做出一部蝙蝠侠的动画小电影,效果也是非常不错。

自Stable Diffusion开源后,一些开发者通过Google Colab等形式分享了各种魔改后的功能,自动生成动画功能一步步被开发出来。
像国外视频特效团队Corridor,他们基于Stable Diffusion,对AI进行训练,最终能让AI把真人视频转换为动画版本……
大家在对新工具的出现兴奋不已的同时,也有网友对Stable Animation SDK生成的视频所展现出的效果发出质疑:
这与 deforum有什么区别?没有时间线都不连贯,只有非常松散的一帧接一帧的图像。
那么你玩过这些工具了吗?感觉效果如何?
传送门:
https://platform.stability.ai/docs/features/animation/using(Stable Animation SDK使用说明书)
参考链接:
[1]https://www.youtube.com/watch?v=xsoMk1EJoAY
[2]https://twitter.com/_akhaliq/status/1656693639085539331
[3]https://stability.ai/blog/stable-animation-sdk
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
GAN和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-GAN或者扩散模型 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如GAN或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









