一、简介 均值不等式,又名平均值不等式、平均不等式,是数学中的一个重要公式。 公式内容: 其中的数全为正整数。 即调和平均数≤几何平均数≤算术平均数≤平方平均数。 二、证明 1.几何平均数≤算术平均数 2.调和平均数≤几何平均数 3.算术平均数≤平方平均数 三、总结 均值不等式可以说是最基本的不等式,很多不等式的证明都是在此基础上加以推导从而得出结论,是需要掌握扎实的基本不等式之一。









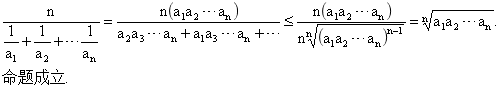
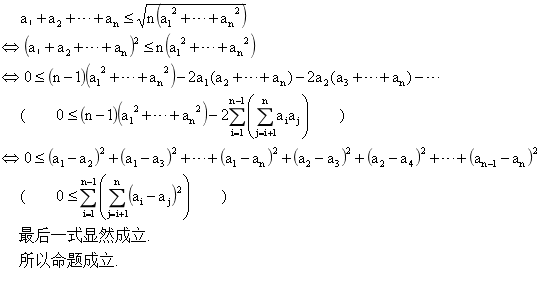

















 2948
2948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






