






论文地址:https://arxiv.org/abs/1903.09766
摘要:本文提出了一种基于条件生成对抗网络的实时水下图像增强模型。为了监督对抗训练,我们制定了一个目标函数,根据图像的整体内容、颜色、局部纹理和风格信息来评估图像的感知质量。模型源码: http:// https://github.com/xahidbuffon/ funie-gan
创新点:
1)提出了一种基于全卷积条件 GAN 的实时水下图像增强模型,我们称之为 FUnIE-GAN;为了监督对抗训练,我们制定了一个目标函数。根据图像的整体内容、颜色、局部纹理和风格信息来评估图像的感知质量,从而制定了一个多模态目标函数来训练模型。
2)我们还介绍了 EUVP 数据集,这是一个由 20K 幅水下图像(质量有好有坏)组成的配对和非配对集合,可用于单向和双向对抗训练 。该数据集可在以下网址获取:http://irvlab.cs.umn. edu/resources/euvp-dataset
FUnIE-GAN 架构
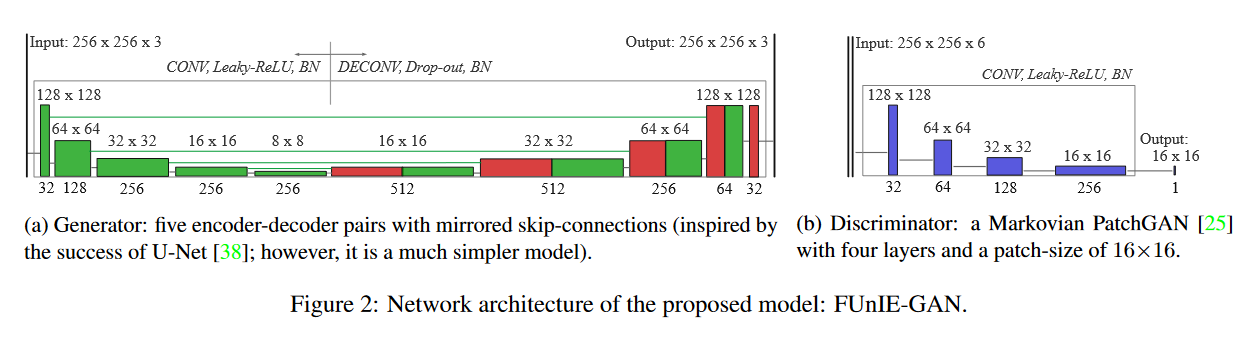
生成器:
给定源域 X(扭曲图像)和期望域 Y(增强图像),我们的目标是学习映射 G : X → Y,以执行自动图像增强。采用了一种基于条件 GAN 的模型,其中生成器试图通过迭代最小-最大博弈,与对抗性判别器共同学习这一映射。如图所示,我们按照 U-Net 的原理设计了一个生成器网络。它是一个编码器-解码器网络(e1-e5,d1-d5),镜像层之间有连接,即(e1, d4)、(e2, d3)、(e3, d2)和(e4, d1)之间有连接。具体地说,每个编码器的输出都被连接到各自的镜像解码器。生成器网络中的这种跳转连接思想在图像间转换和图像质量增强问题上非常有效 。在 FUnIE-GAN 中,为了实现快速推理,我们采用了参数更少的简单模型。网络的输入设置为 256 × 256 × 3,编码器(e1-e5)只学习大小为 8 × 8 的 256 个特征图。解码器(d1-d5)利用这些特征图和来自跳转连接的输入,学习生成 256 × 256 × 3(增强)图像作为输出。由于没有使用全连接层,因此该网络是全卷积网络。此外,每一层都使用 4 × 4 滤波器进行二维卷积,然后再进行 Leaky-ReLU 非线性处理和批归一化处理(BN)。图 2a 中标注了各层的特征图大小和其他模型参数。
判别器
采用了 Markovian PatchGAN 架构,该架构假定像素在斑块大小之外是独立的,即仅根据斑块级信息进行判别。这一假设对于有效捕捉局部纹理和风格等高频特征非常重要。此外,与在图像层面进行全局判别相比,这种配置需要的参数更少,因此计算效率更高。如图 2b 所示,四个卷积层用于将 256 × 256 × 6 输入(真实图像和生成图像)转换为 16 × 16 × 1 输出,该输出代表判别器的平均有效响应。每层使用 3 × 3 卷积滤波器,步长为 2;然后以与生成器相同的方式应用非线性和 BN。
目标函数公式:
基于条件 GAN 的标准模型学习映射 G : {X, Z} → Y,其中 X (Y ) 表示源(期望)域,Z 表示随机噪声。条件对抗损失函数表示为
生成器 G 试图最小化 LcGAN,而判别器 D 则试图最大化 LcGAN。在 FUnIE-GAN 中,我们将另外三个方面,即全局相似性、图像内容以及局部纹理和风格信息,与量化感知图像质量的目标联系起来。
全局相似性:
在目标函数中加入 L1(L2)损失项,可以让 G 学会从 L1(L2)意义上的全局相似空间中采样。由于 L1 损失不易产生模糊,我们在目标函数中添加了以下损失项:
图像内容:
在目标中添加了内容损失项,以鼓励 G 生成与目标(即真实)图像具有相似内容(即特征表示)的增强图像。将图像内容函数 Φ(-) 定义为由预先训练的 VGG-19 网络的 block5_conv2 层提取的高级特征。然后,我们将内容损失表述如下:
局部纹理和风格:
Markovian PatchGAN 能有效捕捉与局部纹理和风格相关的高频信息。因此,依靠 D 以对抗的方式加强局部纹理和风格的一致性。
配对训练
制定了一个目标函数,引导 G 学习如何提高感知图像的质量,从而使生成的图像在整体外观和高级特征表示方面接近各自的地面实况。另一方面,D 会放弃生成的局部纹理和风格不一致的图像。具体来说,我们使用以下目标函数进行配对训练:
λ1 = 0.7 和 λc = 0.3 是我们根据经验调整的超参数缩放因子。
无配对训练
由于没有配对的地面实况,我们不强制执行全局相似性和内容损失约束。相反,我们的目标是通过保持循环一致性,同时学习前向映射 GF : {X, Z} → Y 和重构 GR : {Y, Z} → X。根据 Zhu 等人的建议,我们将循环一致性损失表述如下:
非配对训练目标是:
DY (DX ) 是与生成器 GF (GR) 相关的判别器,缩放因子 λcyc = 0.1 是根据经验调整的超参数。由于 Lcyc 计算的是 L1 空间中每个域的类似重建损失,因此我们不强制执行额外的全局相似性损失项。
EUVP数据集
EUVP 数据集包含大量配对和未配对的感知质量较差和较好的水下图像。我们使用了七种不同的摄像头(包括多个 GoPros 摄像头、Aqua AUV 的 uEye 摄像头、低照度 USB 摄像头 和 Trident ROV 的高清摄像头)来捕捉数据集的图像。这些数据是在不同地点、不同能见度条件下进行海洋探索和人机合作实验时收集的。此外,数据集中还包括从一些公开的 YouTubeTM 视频中提取的图像。这些图像经过精心挑选,以适应数据中广泛的自然变化(如场景、水体类型、光照条件等)。
未配对数据是由六名人类参与者准备的,即根据视觉检查将质量好和质量差的图像分开。他们检查了几种图像属性(如颜色、对比度和清晰度),并考虑了场景是否可视化解读,即前景/物体是否可识别。因此,无配对训练认可了人类对水下图像质量的感知偏好建模。具体来说,基于 CycleGAN 的模型在未配对数据上进行训练,以学习质量好和质量差图像之间的域转换。随后,质量好的图像会被学习到的模型扭曲,从而生成相应的配对数据;我们还从 ImageNet 数据集和 FlickrTM 中添加了一组水下图像。
EUVP 数据集中有超过 12K 个配对实例和 8K 个非配对实例;图 3 中提供了一些样本。需要注意的是,我们的重点是促进感知图像增强,以增强机器人对场景的理解,而不是模拟水下光学退化过程以进行图像复原,后者需要场景深度和水体属性。
缺点
FUnIE-GAN 对于增强严重退化和无纹理的图像效果不佳。在这种情况下生成的图像通常会因噪声放大而过度饱和。虽然色调修正一般都是正确的,但色彩和纹理恢复仍然很差。其次,FUnIEGAN-UP 容易出现训练不稳定的问题。我们的研究表明,判别器往往过早地变得太好,导致梯度效应减弱,从而停止了生成器的学习。
总结
我们为水下图像增强提出了一种简单而高效的基于条件的广义广谱网络(GAN)模型。该模型根据图像的全局色彩、内容、局部纹理和风格信息来评估图像质量,从而计算出感知损失函数。我们还提出了一个大规模的数据集,其中包含一组配对和一组非配对的水下图像,用于监督训练。我们进行了广泛的定性和定量评估,并开展了一项用户研究,结果表明,与最先进的模型相比,所提出的模型不仅推理速度更快,而且性能不相上下,甚至更好。此外,我们还证明了该模型在提高水下物体检测、突出预测和人体姿态估计性能方面的有效性。未来,我们计划研究它在其他水下人机合作应用、海洋垃圾识别等方面的可行性。我们还将努力提高其在无配对训练中的色彩一致性和稳定性。















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









