







web ui自动化之元素定位
前言
在我们使用driver.get(url)方法后,driver会加载整个页面,如果我们要做一些操作,如:点击页面中的某个元素、对某个元素输入内容等,则首先需要定位到这个元素,再进行操作
下面将介绍,在python+selenium中,元素定位的方法(共8种)
前置步骤,需要先安装selenium,并导入By模块
pip install selenium # 安装selenium库
from selenium import webdriver # 导入selenium驱动
from selenium.webdriver.common.by import By # 导入元素定位的模块
driver = webdriver.Chrome() # 使用chrome驱动
driver.maximize_window() # 将窗口最大化
driver.get('https://www.baidu.com/') # 访问被测域名
一、ID定位
ID一般都是唯一的,建议使用
代码如下(示例):
driver.find_element(By.ID,'kw').send_keys('NBA一共几个队') # 通过ID属性定位元素,若是多个,默认取第一个
二、NAME定位
NAME定位元素可能会重复
代码如下(示例):
driver.find_element(By.NAME,'wd').send_keys('NBA一共几个队')
三、CLASS_NAME定位
CLASS_NAME定位元素容易重复,一般不用
代码如下(示例):
driver.find_element(By.CLASS_NAME,'s_ipt').send_keys('NBA一共几个队')
四、TAG_NAM定位
TAG_NAM是通过标签名去定位元素,容易重复,一般不用,input、div 就是一个标签的名字,可以通过find_element_by_tag_name(“input”) 函数来定位
代码如下(示例):
driver.find_element(By.TAG_NAME,'_blank')
五、LINK_TEXT定位
LINK_TEXT是超链接文本精准匹配,LINK_TEXT只适用于定位a标签元素,根据a标签的linktext进行定位,该方法不支持模糊匹配。
代码如下(示例):
driver.find_element(By.LINK_TEXT,'一淘限时抢').click()
六、PARTIAL_LINK_TEXT定位
PARTIAL_LINK_TEXT与LINK_TEXT一样,只适用只适用于a标签,但它可以精准匹配,也可以模糊匹配
代码如下(示例):
driver.find_element(By.PARTIAL_LINK_TEXT,'一淘').click()
七、XPATH定位
XPATH即为XML路径语言,可通过绝对定位或相对定位的形式进行元素定位,该方法可以满足大部分的定位条件
1.XPAH语法规则
| 表达式 | 作用 |
|---|---|
| / | 表示从根节点开始选取 |
| // | 表示从任意节点开始选取 |
| . | 表示选取当前节点 |
| … | 表示选取当前节点的父节点 |
| @ | 表示选取属性,或者根据属性选取 |
| * | 通配符,表示任意节点或任意属性 |
2.XPAH属性定位
如下图中标记的位置(class、name、id等),都为属性

代码如下(示例):
driver.find_element(By.XPATH, '//a[@class="s_ipt"]') # 解析:选取具备class属性的s_ipt元素,其他属性也一样,如图中的:id、name、autocomplete等
3.XPAH标签定位
如下图中标记的位置(div、a、form、input等),都为标签
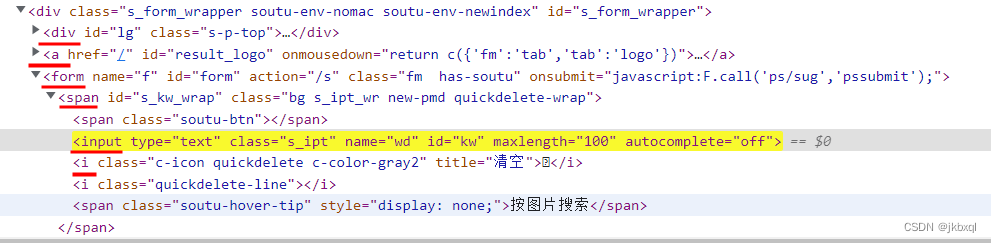
4.XPAH层级关系定位
在实际的测试过程中我们经常会遇到,页面上有很多个属性基本相同的元素,现在需要具体定位到其中的一个。由于属性基本相当,所以在定位的时候会有些麻烦,这时候就需要用到层级定位。先定位父元素,然后再通过父元素定位子孙元素。
如下图中标记的位置(一个div下边包含了好多个div,div下边有包含了div标签、a标签、span标签等),以下就为层级
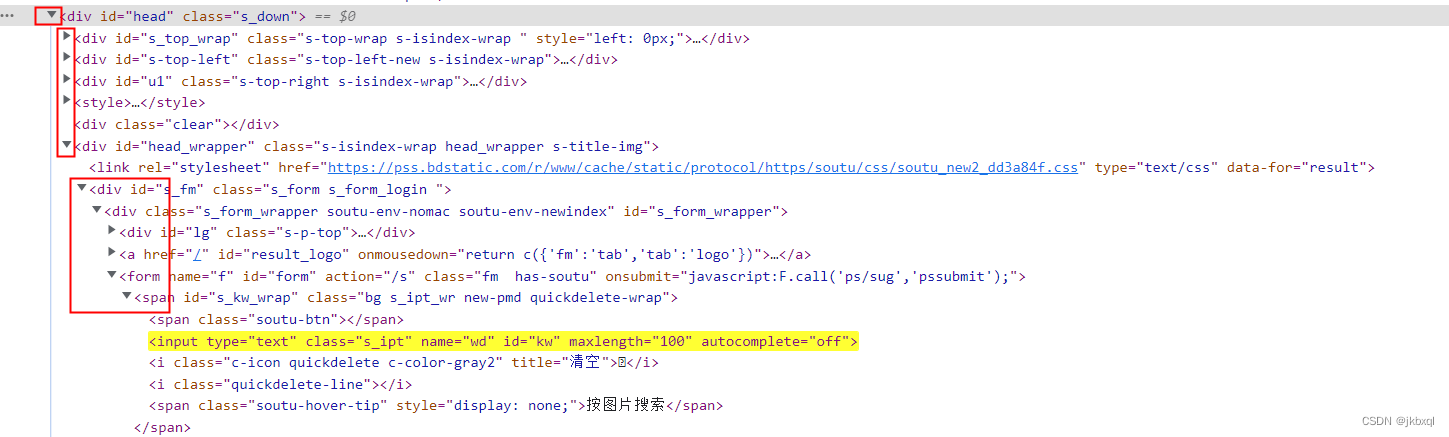
代码如下(示例):
driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input')
5.XPAH索引定位
如下图中标记的位置(中括号中的数字),就为索引定位

6.XPAH文本定位
如下图中标记的位置,就为文本定位,文本定位就是定位span标签中的文本
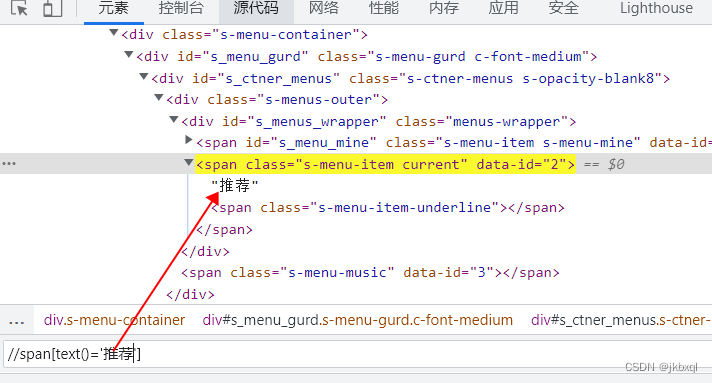
代码如下(示例):
driver.find_element(By.XPATH, '//span[text()="推荐"]')
八、CSS_SELECTOR定位
CSS_SELECTOR方法定位元素和XPATH类似,一般的元素都可以通过该方法定位,但CSS可以更快 更简捷
1.CSS语法规则
| 表达式 | 作用 |
|---|---|
| # | 代表id定位 |
| . | 代表class定位 |
2.CSS属性定位
以百度首页为例
代码如下(示例):
driver.find_element(By.CSS_SELECTOR,'#kw').send_keys('python') # 定位ID为kw的内容
driver.find_element(By.CSS_SELECTOR,'[id="kw"]').send_keys('python') # ID定位当然也可以使用该方式写
driver.find_element(By.CSS_SELECTOR,'.s_ipt').send_keys('python') # 定位class为s_ipt的内容
# driver.find_element(By.CSS_SELECTOR,'[name="wd"]').send_keys('python') # 定位name属性为wd的内容
driver.find_element(By.CSS_SELECTOR,'[autocomplete="off"]').send_keys('python') # 定位autocomplete属性为off的内容
3.CSS标签定位
以百度首页为例
代码如下(示例):
driver.find_element(By.CSS_SELECTOR,'input#kw').send_keys('python')
driver.find_element(By.CSS_SELECTOR,'input.s_ipt').send_keys('python')
driver.find_element(By.CSS_SELECTOR,'input[name="wd"]').send_keys('python')
4.CSS层级关系定位
代码如下(示例):
driver.find_element(By.CSS_SELECTOR,'form#form>span>input[name="wd"]').send_keys('python')
driver.find_element(By.CSS_SELECTOR,'form.fm>span>input').send_keys('python')
5.CSS索引定位
css也可以通过索引option:nth-child(1)来定位子元素,这点与xpath写法用很大差异
代码如下(示例):
driver.find_element(By.CSS_SELECTOR,'select#nr>option:nth-child(1)') # 查找select标签中,id为nr的第一个元素
九、定位多个元素
定位多个元素,使用find_elements()方法,以上8种定位方式均可使用该方法,该方法的返回结果为列表
driver.find_elements(By.XPATH, '//a[text()="登录"]')
driver.find_elements(By.XPATH, '//a[text()="登录"]')[3] # 定位多个元素中的第三个
总结
使用XPATH和CSS_SELECTOR两种定位方式,基本的元素定位都可以搞定,当然这两种方法也是最常用的方法,根据个人习惯选择即可。














 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









