






目录
机器学习基础
1.线性回归
假设二维空间上的20个散点
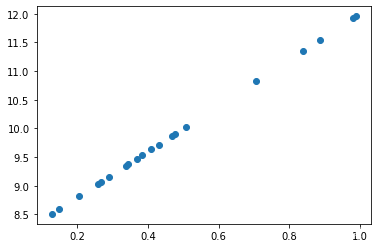
现在我们希望构建一个模型来拟合这些点,通过观察,我们很容易想到使用一条直线来拟合。二维空间上的直线表达式为,但是如何求得未知数(以下统称为权重)
和
呢?
这里引入均方误差:
表示真实值,
表示模型预测值,当
越小,表示预测值与真实值之间的误差越小,即模型越准确。下面介绍如何使得
最小:
将代入
得
散点的值已知,取一点坐标(4,12),代入得
此时问题便转换为求这个二元函数的极小值,此题可采用高数中的求极小值方法解出,但在机器学习中,对于复杂问题这种方法并不适用,因此我们采用梯度下降法
梯度下降法
这个二元函数的图像如下
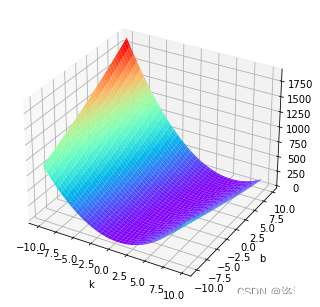
假设这是一个山谷,你随机站在一个位置,想走到山谷(极小值),那么最快的方法就是沿着最陡峭的方向(最大斜率的反方向)走一段距离,然后再寻找最陡峭方向向下走,重复此过程就能走到最低点。但是怎样才找到最陡峭的方向呢?这个答案就是梯度方向。
分别求关于
和
的偏导数,得到一个向量(
,
),称为 梯度向量 ,记作:
或
,向量是有方向的,这个方向就是函数上升最快的方向,
即为函数下降最快的方向。
随机初始化一个点(,
),那么梯度下降的过程可表示为
......
当趋近于0或达到指定的阈值(n)时,可认为当权重值取
时,损失函数达到局部最小值。若想得到全局最小值,可多次随机初始权重值进行梯度下降,最终得到的权重值便是最优解。
代码
import torch
learning_rate=0.01
x=torch.rand([20,1])
y_true=x*4+8
w=torch.rand([1,1],requires_grad=True)
b=torch.tensor(0.0,requires_grad=True)
for i in range(10000):
y_predict=torch.matmul(x,w)+b
#print(y_predict)
loss=(y_true-y_predict).pow(2).mean()
#print(w.grad)
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward()
w.data=w.data-learning_rate*w.grad
b.data = b.data - learning_rate * b.grad
print('w,b,loss',w.item(),b.item(),loss)训练结果
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)
w,b,loss 4.000154972076416 7.999902248382568 tensor(2.9782e-09, grad_fn=<MeanBackward0>)拟合效果
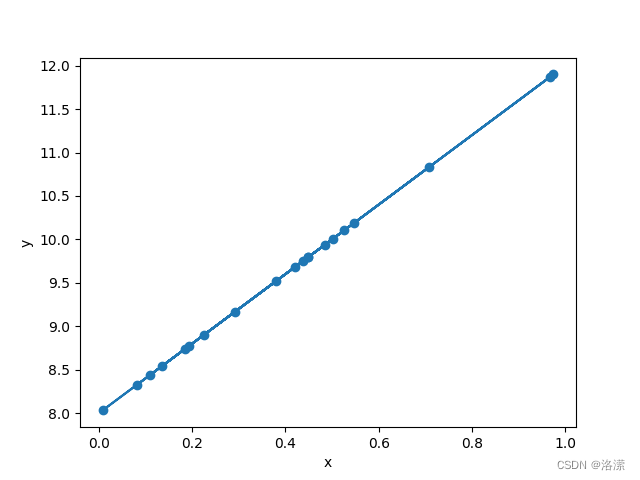
可以看到拟合效果很好 ,所以可以使用
=4.000154972076416
7.999902248382568作为预测模型
2.感知器
感知机由两层神经网络组成,可以实现二分类问题。输入层接收外界输入信号后传递给输出层(输出1正例,-1反例),输出层是 M-P 神经元, 其中从都表示权重。
这里激活函数为阶跃函数,可以实现二分类
则感知器可用公式表示为
经过多次梯度下降后可以求得权重值
数据集
这里使用鸢尾花数据集,每条数据包含四个特征值,将其中两个类别映射为-1和1
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
0 5.1 3.5 1.4 0.2 -1
1 4.9 3.0 1.4 0.2 -1
2 4.7 3.2 1.3 0.2 -1
3 4.6 3.1 1.5 0.2 -1
4 5.0 3.6 1.4 0.2 -1
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 1
146 6.3 2.5 5.0 1.9 1
147 6.5 3.0 5.2 2.0 1
148 6.2 3.4 5.4 2.3 1
149 5.9 3.0 5.1 1.8 1
[100 rows x 5 columns]代码
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
data=pd.read_csv('Iris.csv')
data.drop_duplicates()
data['Species']=data['Species'].map({'Iris-versicolor':0,'Iris-virginica':1,'Iris-setosa':-1,})
data = data[data['Species']!=0]
class Perception:
def __init__(self,alpha,times):
self.alpha=alpha
self.times=times
def step(self,z):
return np.where(z > 0, 1, -1) # 一步实现对数值或者数组的计算返回
def fit(self,X,y):
X=np.asarray(X)
y=np.asarray(y)
self.w_=np.zeros(1+X.shape[1])
self.loss_=[]
for i in range(self.times):
loss=0
for x,target in zip(X,y):
y_hat=self.step(np.dot(x,self.w_[1:])+self.w_[0])
loss+=y_hat!=target
self.w_[0]+=self.alpha*(target-y_hat)
self.w_[1:] += self.alpha * (target - y_hat)*x
self.loss_.append(loss)
def predict(self,X):
return self.step(np.dot(X,self.w_[1:])+self.w_[0])
t1 = data[data["Species"]==1]
t2 = data[data["Species"]==-1]
t1.sample(len(t1), random_state=0)
t2.sample(len(t2), random_state=0)
train_X = pd.concat([t1.iloc[:40,:-1], t2.iloc[:40, :-1]], axis=0)
train_y = pd.concat([t1.iloc[:40,-1], t2.iloc[:40, -1]], axis=0)
test_X = pd.concat([t1.iloc[40:,:-1], t2.iloc[40:, :-1]], axis=0)
test_y = pd.concat([t1.iloc[40:,-1], t2.iloc[40:, -1]], axis=0)
p = Perception(0.1, 10)
p.fit(train_X,train_y)
result = p.predict(test_X)
print(result)
print(test_y.values)
print(p.w_)
print(p.loss_)
权重
[-0.02 -0.05 -0.068 0.156 0.088]第五个权重为偏置(即
)
损失变化
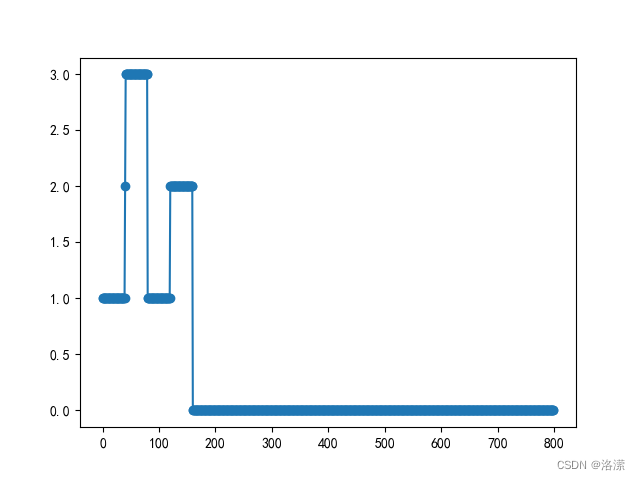
loss+=y_hat!=target表示损失,即预测值与真实值不一致时,损失值加1
经过多次梯度下降后,损失降为0
分类效果
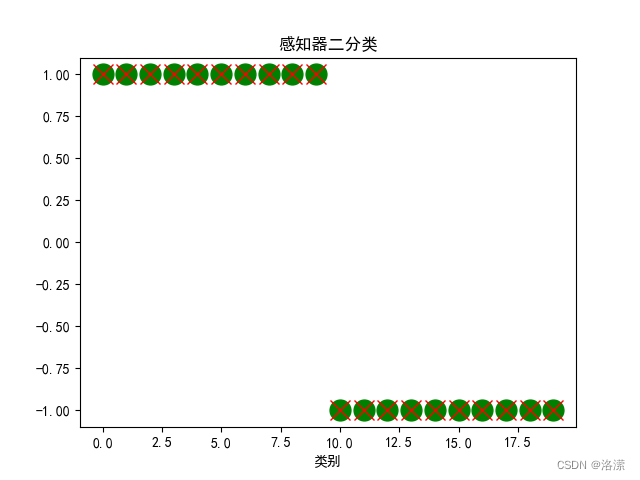
可以看到预测类别与真实类别一致
也可以使用sigmoid函数作为激活函数
sigmoid函数
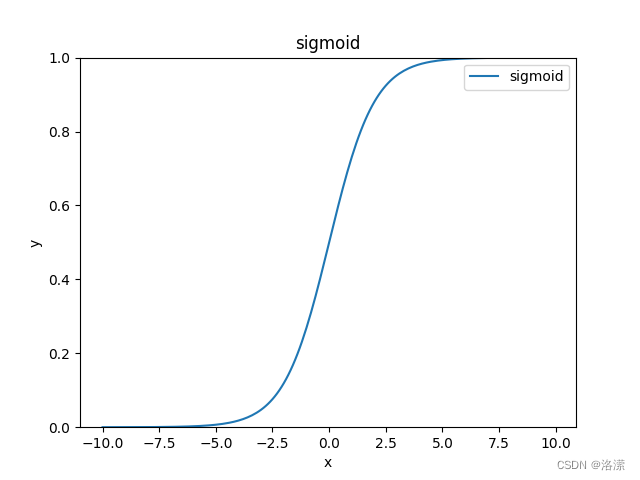
将感知器输出值传入 sigmoid函数可以得到一个0到1区间上的值,我们可以将这个值认为是概率,分类的损失只需要再把这个结果进行对数似然损失的计算即可,即:
动量法
,
表示前一次的梯度
,
表示学习率
AdaGrad
,
为小常数,为了数值稳定大约设置为
RMSProp
Adam
=0,
=0
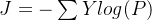
即
其中
,Y表示经过
编码(见下文)后的真实值 ,
最后,会计算每个样本的损失,即上式的平均值
我们把概率
传入对数似然损失得到的损失函数称为交叉熵损失
由对数函数图像
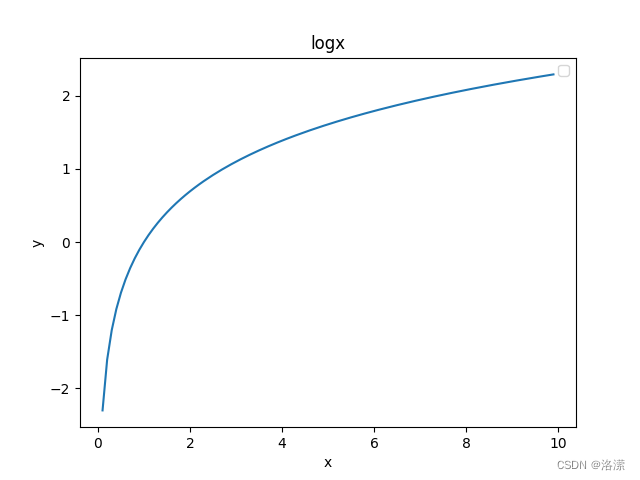
得:当p趋近于1时,J 趋近于0,所以通过多次梯度下降法求得使J最小的权重,便可以使得感知器输出结果为真实类别的概率趋近于1,错误类别的概率趋近于0
3.非线性回归
假设二维空间上的20个散点
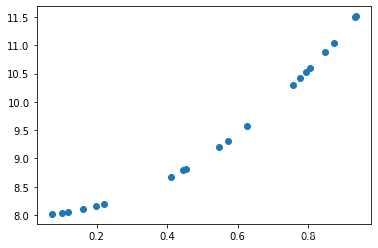
此时如果使用线性函数来拟合这些点,拟合效果就会比较差,如图:
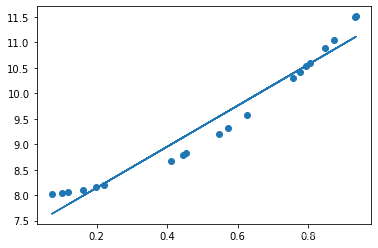
显而易见,我们需要一个非线性的模型来拟合这些点。构造非线性模型只需要把线性函数传入一个非线性的激活函数即可。
激活函数
在前面的神经元的介绍过程中我们提到了激活函数,那么他到底是干什么的呢?
假设我们有这样一组数据,三角形和四边形,需要把他们分为两类
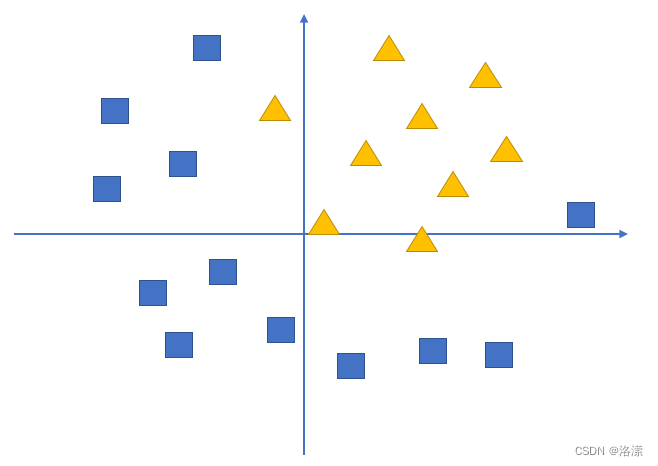
通过不带激活函数的感知机模型我们可以划出一条线, 把平面分割开
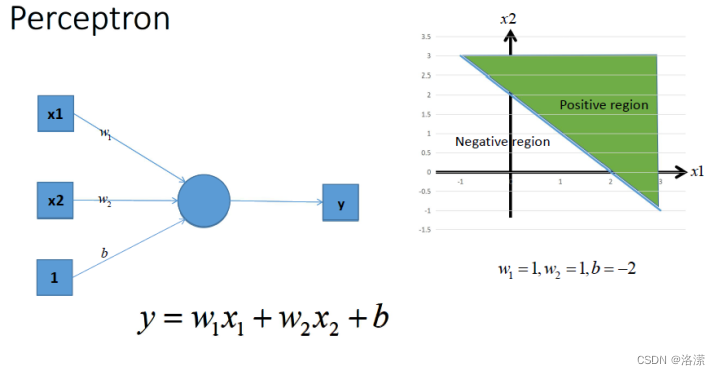
假设我们确定了参数w和b之后,那么带入需要预测的数据,如果y>0,我们认为这个点在直线的右边,也就是正类(三角形),否则是在左边(四边形)
但是可以看出,三角形和四边形是没有办法通过直线分开的,那么这个时候该怎么办?
可以考虑使用多层神经网络来进行尝试,比如在前面的感知机模型中再增加一层
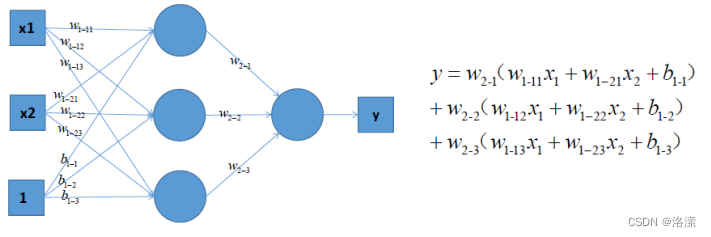
对上图中的等式进行合并,我们可以得到:
上式括号中的都为w参数,和公式完全相同,依然只能够绘制出直线
所以可以发现,即使是多层神经网络,相比于前面的感知机,没有任何的改进。
但是如果此时,我们在前面感知机的基础上加上非线性的激活函数之后,输出的结果就不在是一条直线
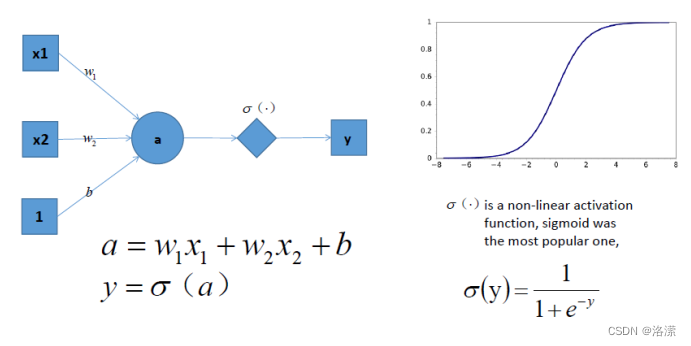
如上图,右边是sigmoid函数,对感知机的结果,通过sigmoid函数进行处理
如果给定合适的参数w和b,就可以得到合适的曲线,能够完成对最开始问题的非线性分割
所以激活函数很重要的一个作用就是增加模型的非线性分割能力
常见的激活函数有:

看图可知:
- tanh和sigmoid不同的是,tanh输出可以是负数
- Relu是输入只能大于0,如果你输入含有负数,Relu就不适合,如果你的输入是图片格式,Relu就挺常用的,因为图片的像素值作为输入时取值为[0,255]。
激活函数的作用除了前面说的增加模型的非线性分割能力外,还有
- 提高模型鲁棒性
- 缓解梯度消失问题
- 加速模型收敛等
这里使用ReLU激活函数,
损失函数依然选取均方误差,经过多次梯度下降即可得到合适的模型
代码
import torch
from torch import nn as nn
from torch.optim import SGD
x=torch.rand([20,1])
y_true=4*x**2+8
class Myliner(nn.Module):
def __init__(self):
super(Myliner,self).__init__()
#传入特征数量,输出特征数量(传入列数,输出列数)
self.linear=nn.Linear(1,100)
self.relu=nn.ReLU()
self.out=nn.Linear(100,1)
#默认input,输入x
def forward(self,x):
out=self.linear(x)
out=self.relu(out)
out=self.out(out)
return out
myliner=Myliner()
#最优化策略
optimizer=SGD(myliner.parameters(),0.001)
#损失函数
loss_fn=nn.MSELoss()
for i in range(100000):
y_predict=myliner(x)
loss=loss_fn(y_predict,y_true)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%500==0:
print(loss.item())
# print(list(myliner.parameters()))
# print(list(myliner.parameters())[0].size())
# print(list(myliner.parameters())[1].size())
# print(list(myliner.parameters())[2].size())损失
0.0003325166762806475
0.00033017684472724795
0.00032786981319077313
0.0003255746269132942
0.0003233018796890974
0.0003210595459677279
0.0003188303089700639
0.00031664027483202517
0.00031448277877643704
0.000312333315378055
0.0003102142654825002
0.0003081295290030539
0.0003060710441786796
0.00030400961986742914
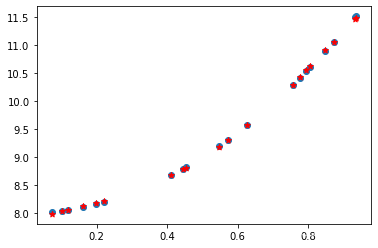
0.0003019951982423663拟合效果
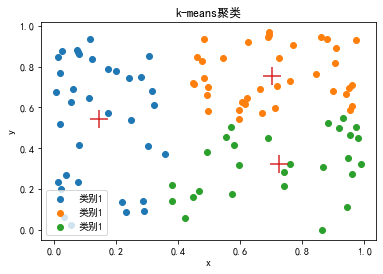
4.K-means聚类
k-means聚类算法属于无监督学习,可以将数据集分为相似的组(簇),使得组(簇)内数据相似度较高,使得组(簇)间数据相似度较低。
假设二维空间上的100个散点,要将这些点分为三个类别
K-means算法步骤
1.从样本中随机选择K个点作为初始簇中心,即:
2.计算每个样本到各个簇中心的距离,把样本划分到距离最近的簇中心所对应的簇中。距离公式为
3.根据每个簇中的所有样本,重新计算簇中心,并更新。新的簇中心为:
4.重复步骤2,3。直到簇中心的位置变化小于指定的阈值或达到最大迭代次数为止。
代码
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#from 数据挖掘.geshi import format
#format()
#Set the font to bold to support Chinese display
mpl.rcParams['font.sans-serif']=['SimHei']
#Set the Chinese font to be able to display symbols normally
mpl.rcParams['axes.unicode_minus']=False
#Set the display length of value, the default is 50
pd.set_option('display.max_colwidth',1000)
pd.set_option('display.width',10000)
#show all rows
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
class KMeans:
'''Kmeans聚类算法实现'''
def __init__(self, k, times):
'''初始化
Parameters
-----
k: int 聚成几个类
times: int 迭代次数
'''
self.k = k
self.times = times
def fit(self, X):
'''根据所给数据训练
Pararmeters
------
X: 类数组类型,形如:[样本数量,特征数量]
'''
X = np.asarray(X)
# 设置随机数种子,以便于可以相同的随机系列,以便随机结果重现
np.random.seed(0)
# 从数组中随机选择K个点作为初始聚类中心
self.cluster_centers_ = X[np.random.randint(0, len(X), self.k)]
#print(self.cluster_centers_)
# 用于存放数据所属标签
self.labels_ = np.zeros(len(X))
# 开始迭代
for t in range(self.times):
# 循环遍历样本计算每个样本与聚类中心的距离
for index, x in enumerate(X):
# 计算每个样本与每个聚类中心的欧式距离
dis = np.sqrt(np.sum((x - self.cluster_centers_) ** 2, axis=1))
# 将最小距离的索引赋值给标签数组,索引的值就是当前所属的簇。范围(0,K-1)
self.labels_[index] = dis.argmin()
#print(self.labels_[index])
# 循环便利每一个数更新聚类中心
for i in range(self.k):
# 计算每个簇内所有点的均值,用来更新聚类中心
self.cluster_centers_[i] = np.mean(X[self.labels_ == i], axis=0)
#print(self.cluster_centers_[i])
#print(self.cluster_centers_)
def predict(self, X):
'''预测样本属于哪个簇
Parameters
-----
x: 类数组类型。形如[样本数量。特征数量]
Reeturn
-----
result: 类数组,每一个x所属的簇
'''
X = np.asarray(X)
result = np.zeros(len(X))
for index, x in enumerate(X):
# 计算样本与聚类中心的距离
dis = np.sqrt(np.sum((x - self.cluster_centers_) ** 2, axis=1))
# 找到距离最近的聚类中中心划分一个类别
result[index] = dis.argmin()
return result
kmeans=KMeans(3,1)
kmeans.fit(a)
print(kmeans.cluster_centers_)聚类效果
神经网络
1. 人工神经网络的概念
人工神经网络(Artificial Neural Network),简称神经网络(Neural Network,NN)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型,用于对函数进行估计或近似。
和其他机器学习方法一样,神经网络已经被用于解决各种各样的问题,例如机器视觉和语音识别。这些问题都是很难被传统基于规则的编程所解决的。
2. 神经元的概念
在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个“阈值”,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
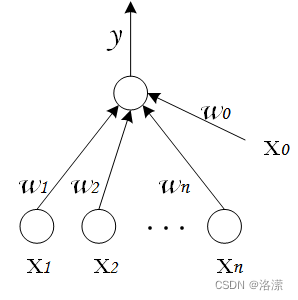
1943 年,McCulloch 和 Pitts 将上述情形抽象为上图所示的简单模型,这就是一直沿用至今的 M-P 神经元模型。把许多这样的神经元按一定的层次结构连接起来,就得到了神经网络。
一个简单的神经元如下图所示:
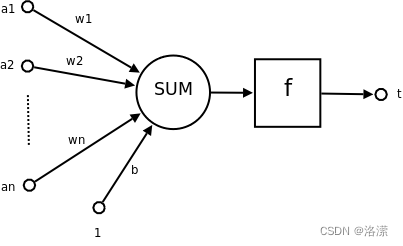
其中:
为各个输入的分量
为各个输入分量对应的权重参数
为激活函数,常见的激活函数有tanh,sigmoid,relu
为神经元的输出
一个简单的神经元可以看作是一个(非)线性回归,使用数学公式表示就是:
可见,一个神经元的功能是求得输入向量与权向量的内积后,经一个非线性传递函数得到一个标量结果。
3. 单层神经网络
是最基本的神经元网络形式,由有限个神经元构成,所有神经元的输入向量都是同一个向量。由于每一个神经元都会产生一个标量结果,所以单层神经元的输出是一个向量,向量的维数等于神经元的数目。示意图如下:

4. 多层神经网络
多层神经网络就是由单层神经网络进行叠加之后得到的,所以就形成了层的概念,常见的多层神经网络有如下结构:
- 输入层(Input layer),众多神经元(Neuron)接受大量输入消息。输入的消息称为输入向量。
- 输出层(Output layer),消息在神经元链接中传输、分析、权衡,形成输出结果。输出的消息称为输出向量。
- 隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有一层或多层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)更显著。
示意图如下:
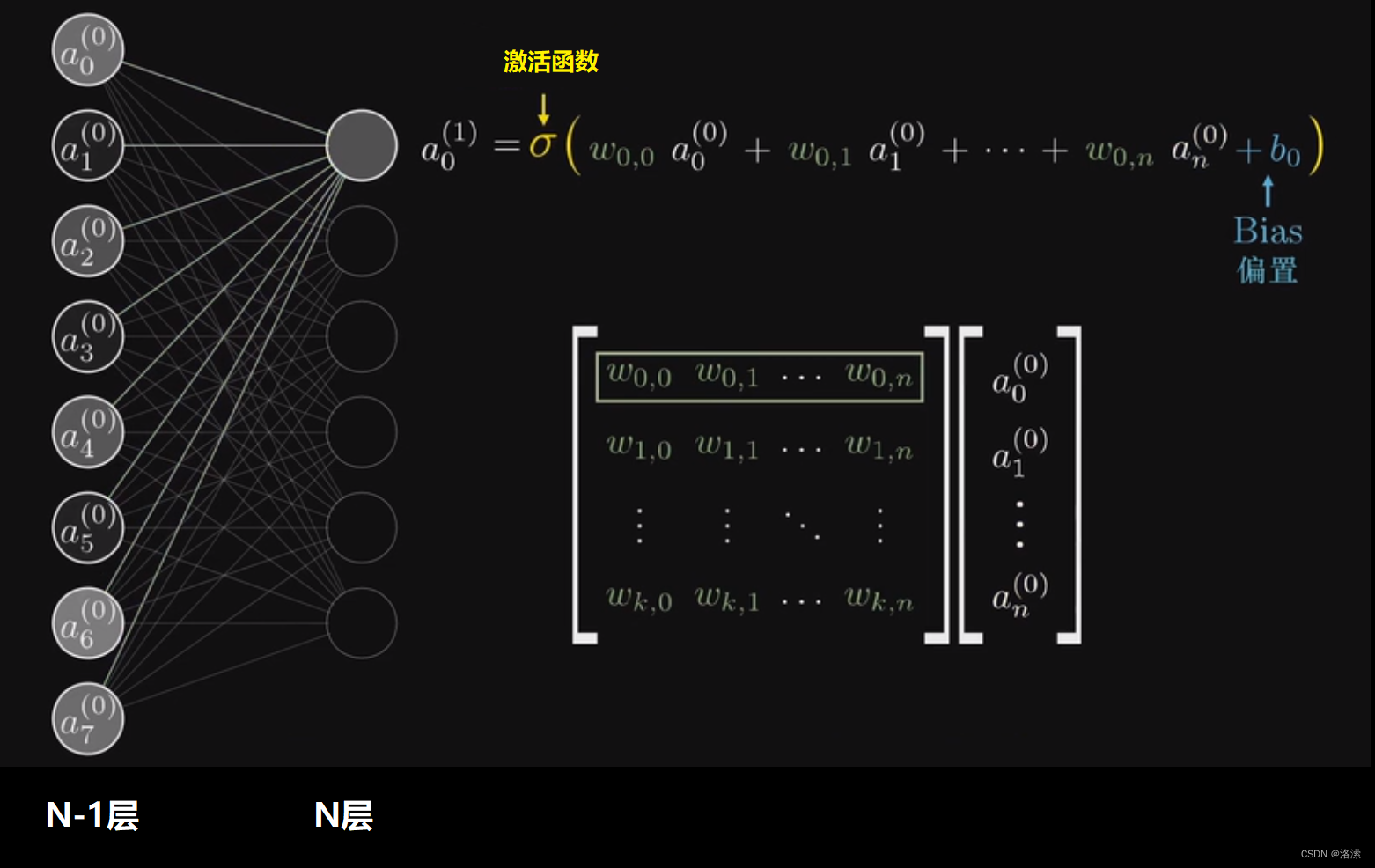
从上图可以看出,所谓的全连接层就是在前一层的输出的基础上进行一次Y=Wx+b的变化(不考虑激活函数的情况下就是一次线性变化,所谓线性变化就是平移(+b)和缩放的组合(*w))
文本分类
文本分类一般包括了文本的表达、 分类器的选择与训练、 分类结果的评价与反馈等过程,其中文本的表达又可细分为文本预处理、索引和统计、特征抽取等步骤。文本分类系统的总体功能模块为:
(1)预处理:将原始语料格式化为同一格式,便于后续的统一处理;
(2)索引:将文档分解为基本处理单元,同时降低后续处理的开销;
(3)统计:词频统计,项(单词、概念)与分类的相关概率;
(4)特征抽取:从文档中抽取出反映文档主题的特征;
(5)分类器:分类器的训练;
(6)评价:分类器的测试结果分析。
文本预处理
这里选用唐宋诗集作为数据集。由于宋诗的数量比唐诗多很多,所以选择所有唐诗和一部分宋诗。
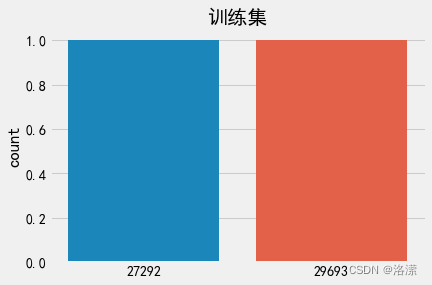
标签数量分布
训练集标签数量分布
测试集标签数量分布
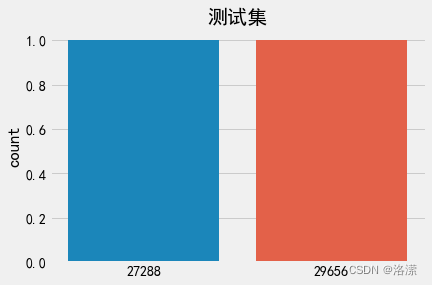
分析:在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减. 上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
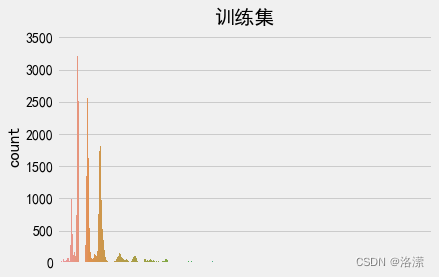
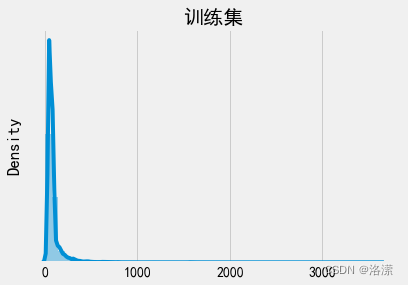
文本长度分布
训练集句子长度分布
测试集句子长度分布
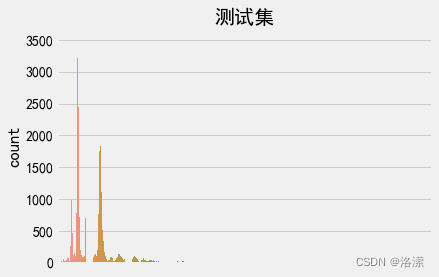
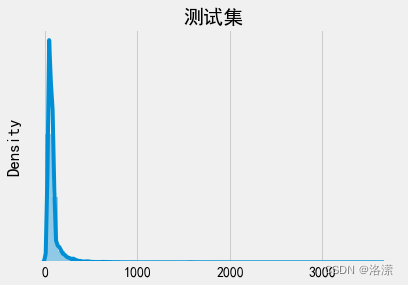
分析:由于神经网络本质上是矩阵运算,所以必须保证输入值得长度相同。即需设定指定值,对长文本进行切分,对短文本进行补全。因此需要设定一个可以包含大部分有效文本信息的阈值,由文本长度分布可得,大部分的文本长度分布在200字以内,所以可以设定最大语句长度为200
词频统计
文本序列化
one-hot编码
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
比如:
"我", "喜欢", "你"
这三个词用one-hot编码表示为一个3阶矩阵:
[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
上文中 Y表示经过编码后的真实值,Y只有两个类别,用one-hot编码表示为:
[[1, 0],
[0, 1]]
word embedding(词嵌入)
如果我们由10000个词汇,这些词汇用one-hot编码后就会形成一个10000阶的矩阵,这个计算量是非常大的,此时就可以通过word embedding将这个矩阵降维。例如:
即可以通过乘以一个权重矩阵的方法把10000阶的矩阵转换为10000X300的矩阵,从而减少计算量
通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间. 广义的word embedding包括所有密集词汇向量的表示方法,word2vec, 即可认为是wordembedding的一种. 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
代码实现
1.构建数据加载器
import os.path
import torch
from torch.utils.data import DataLoader, Dataset
from lib import sx, max_len, batch_size
train_data_path=r'E:\math\train'
test_data_path=r'E:\math\test'
def collate_fn(batch):
content,label=list(zip(*batch))
content=[sx.transform(i,max_len=max_len) for i in content]
content=torch.LongTensor(content)
label=torch.LongTensor(label)
#label=torch.tensor([[label]])
return content,label
class ImdbDataset(Dataset):
def __init__(self,train=True):
self.train_data_path=train_data_path
self.test_data_path=test_data_path
data_path=self.train_data_path if train else self.test_data_path
temp_data_path=[os.path.join(data_path,'唐诗'),os.path.join(data_path,'宋诗')]
self.total_file_path=[]
for path in temp_data_path:
file_name_list=os.listdir(path)
file_path_list=[os.path.join(path,i) for i in file_name_list if i.endswith('.txt')]
self.total_file_path.extend(file_path_list)
def __getitem__(self, index):
file_path=self.total_file_path[index]
label_str=file_path.split('\\')[-2]
label=1 if label_str=='唐诗' else 0
tokens=open(file_path,encoding='utf-8').read().split(' ')
return tokens,label
def __len__(self):
return len(self.total_file_path)
def get_dataloader(train=True,batch=batch_size):
poet_dataset = ImdbDataset()
data_loader = DataLoader(poet_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
return data_loader
if __name__ == '__main__':
for idx,(input,target) in enumerate(get_dataloader(train=True)):
print(idx,input,target)
break2.文本序列化
class Word2Sequence():
UNK_TAG='UNK'
PAD_TAG='PAD'
UNK=0
PAD=1
def __init__(self):
self.dict={
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
}
self.count={}
def fit(self,sentence):
for word in sentence:
self.count[word]=self.count.get(word,0)+1
def bulid_vocab(self,min=None,max=None,max_futures=None):
if min is not None:
self.count={word:value for word,value in self.count.items() if value>min}
if max is not None:
self.count = {word: value for word, value in self.count.items() if value <max}
if max_futures is not None:
temp=sorted(self.count.items(),key=lambda x:x[-1],reverse=True)[:max_futures]
self.count=dict(temp)
for word in self.count:
self.dict[word]=len(self.dict)
self.inverse_dict=dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentense,max_len=None):
if max_len is not None:
if max_len>len(sentense):
sentense=sentense+[self.PAD_TAG]*(max_len-len(sentense))
if max_len<len(sentense):
sentense=sentense[:max_len]
return [self.dict.get(word,self.UNK) for word in sentense]
def inverse_transform(self,indices):
return [self.inverse_dict.get(idx) for idx in indices]
def __len__(self):
return len(self.dict)
3.保存序列化数据
import os
import pickle
from tqdm import tqdm
from dataset import tokenlie
from word_sequence import Word2Sequence
if __name__ == '__main__':
ws=Word2Sequence()
path=r'E:\aclImdb\train'
temp_data_path=[os.path.join(path,'pos'),os.path.join(path,'neg')]
for data_path in temp_data_path:
file_paths=[os.path.join(data_path,file_name) for file_name in os.listdir(data_path) if file_name.endswith('txt')]
for file_path in tqdm(file_paths):
sentence=tokenlie(open(file_path,encoding='utf-8').read())
ws.fit(sentence)
ws.bulid_vocab(min=10,max_futures=10000)
pickle.dump(ws, open('../data/model/情感分类/ws.pkl', 'wb'))
print(len(ws))4.配置文件
import pickle
import torch
ws=pickle.load(open('../../data/model/情感分类/ws.pkl', 'rb'))
max_len=200
batch_size=1024
hidden_size=128
num_layers=2
bidirectional=True
dropout=0.4
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
#print(len(ws))5.构建BP神经网络模型
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from tqdm import tqdm
from dataset import get_dataloader
from lib import sx, max_len
class Mymodel(nn.Module):
def __init__(self):
super(Mymodel, self).__init__()
#词语的数量,维度
self.embedding=nn.Embedding(len(sx),300)
self.fc=nn.Linear(max_len*300,2)
def forward(self,input):
'''
:param input: [batch_size,max_len]
:return:
'''
x=self.embedding(input)#形状:[batch_size,max_len(行),100(列)]
#print(f'x:{x}')
out=self.fc(x.view([-1,max_len*300]))
#print(f'out:{out}')
#计算概率
#print(F.softmax(out, dim=-1))
#print(F.log_softmax(out, dim=-1))
# a=list(map(fy,F.log_softmax(out,dim=-1).max(dim=1)[-1]))
# print(a)
#print(F.log_softmax(out,dim=-1))
#print('类别:',F.log_softmax(out,dim=-1).max(dim=1)[-1])
return F.log_softmax(out,dim=-1)
def fy(a):
if a==1:
return '唐诗'
else:
return '宋诗'
model=Mymodel()
model.load_state_dict(torch.load('./data/BP/model.pt'))
optimizer=Adam(model.parameters(),0.01)
optimizer.load_state_dict(torch.load('./data/BP/model_optimizer.pt'))
def train(epoch):
for idx,(input,target) in enumerate(get_dataloader(train=True)):
# print(f'input:{input}')
# print(f'target:{target}')
optimizer.zero_grad()
output=model.forward(input)
#print(output)
loss=F.nll_loss(output,target)
loss.backward()
optimizer.step()
if epoch%2==0:
print('损失:',loss.item())
# print(list(model.parameters())[0])
# print(list(model.parameters())[0].size())
# print(list(model.parameters())[1])
# print(list(model.parameters())[1].size())
# print(list(model.parameters())[2])
# print(list(model.parameters())[2].size())
def test():
loss_list=[]
acc_list=[]
mode = False
model.eval()
test_dataloader = get_dataloader(train=mode,batch=1000)
for idx, (data, target) in enumerate(test_dataloader):
with torch.no_grad():
output=model(data)
cur_loss=F.nll_loss(output,target)
loss_list.append(cur_loss)
pred=output.max(dim=1)[-1]
cur_acc=pred.eq(target).float().mean()
acc_list.append(cur_acc)
print(f"平均准确率:{np.mean(acc_list)}\n平均损失:{np.mean(loss_list)}")
if __name__ == '__main__':
for i in tqdm(range(100)):
train(i)
torch.save(model.state_dict(),'./data/BP/model.pt')
torch.save(optimizer.state_dict(),'./data/BP/model_optimizer.pt')
#test()6.构建LSTM神经网络模型
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from tqdm import tqdm
from dataset import get_dataloader
from lib import sx, hidden_size, num_layers, bidirectional, dropout, device
class Mymodel(nn.Module):
def __init__(self):
super(Mymodel, self).__init__()
#词语的数量,维度
self.embedding=nn.Embedding(len(sx),300)
self.lstm=nn.LSTM(input_size=300,hidden_size=hidden_size,num_layers=num_layers,
batch_first=True,bidirectional=bidirectional,dropout=dropout)
self.fc=nn.Linear(hidden_size*2,2)
def forward(self,input):
'''
:param input: [batch_size,max_len]
:return:
'''
x=self.embedding(input)#形状:[batch_size,max_len(行),100(列)]
#print(f'x:{x}')
#x [batch_size,max_len,num_layers*hidden_size],h_n [2*num_layers,batch_size,hidden_size]
x,(h_n,c_n)=self.lstm(x)
#获取两个方向最后一次的output,进行concat
output_fw=h_n[-2,:,:]#正向最后一次的输出
output_bw=h_n[-1,:,:]#反向最后一次的输出
output=torch.concat([output_fw,output_bw],dim=-1)#[batch_size,hidden_size*2]
out=self.fc(output)
#print(f'out:{out}')
#计算概率
print(F.softmax(out, dim=-1))
#print(F.log_softmax(out, dim=-1))
# a=list(map(fy,F.log_softmax(out,dim=-1).max(dim=1)[-1]))
# print(a)
#print(F.log_softmax(out,dim=-1))
#print('类别:',F.log_softmax(out,dim=-1).max(dim=1)[-1])
return F.log_softmax(out,dim=-1)
def fy(a):
if a==1:
return '唐诗'
else:
return '宋诗'
model=Mymodel().to(device)
#model.load_state_dict(torch.load('../../data/model/情感分类/model.pt'))
optimizer=Adam(model.parameters(),0.01)
#optimizer.load_state_dict(torch.load('../../data/model/情感分类/model_optimizer.pt'))
def train(epoch):
for idx,(input,target) in enumerate(get_dataloader(train=True)):
# print(f'input:{input}')
# print(f'target:{target}')
input=input.to(device)
target=target.to(device)
optimizer.zero_grad()
output=model.forward(input)
#print(output)
loss=F.nll_loss(output,target)
loss.backward()
optimizer.step()
if epoch%2==0:
print('损失:',loss.item())
# print(list(model.parameters())[0])
# print(list(model.parameters())[0].size())
# print(list(model.parameters())[1])
# print(list(model.parameters())[1].size())
# print(list(model.parameters())[2])
# print(list(model.parameters())[2].size())
def test():
loss_list=[]
acc_list=[]
mode = False
model.eval()
test_dataloader = get_dataloader(train=mode,batch=1000)
for idx, (data, target) in enumerate(test_dataloader):
with torch.no_grad():
output=model(data)
cur_loss=F.nll_loss(output,target)
loss_list.append(cur_loss)
pred=output.max(dim=1)[-1]
cur_acc=pred.eq(target).float().mean()
acc_list.append(cur_acc)
print(f"平均准确率:{np.mean(acc_list)}\n平均损失:{np.mean(loss_list)}")
if __name__ == '__main__':
for i in tqdm(range(1)):
train(i)
torch.save(model.state_dict(),'./model.pt')
torch.save(optimizer.state_dict(),'./model_optimizer.pt')
#test()参考文献
https://github.com/SpringMagnolia/NLPnote
https://blog.csdn.net/weixin_41064957/article/details/78565314

















 2594
2594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











